小编给大家分享一下如何用python实现专业评估舞蹈程序,希望大家阅读完这篇文章后大所收获,下面让我们一起去探讨方法吧!
整体实现思路
主要以安崎小甜心的主题曲直拍视频作为标准视频,谢可寅shaking的主题曲直拍视频作为测试视频
1、将标准视频进行爬取,将视频逐帧读取成图片;
2、由于图片背景光线不太利于关键点捕抓,利用deeplabv3p_xception65_humanseg进行抠图处理;
3、基于pose_resnet50_mpii模型进行关键点检测并存储检测结果;
4、然后对测试视频作同样处理存储检测结果;
5、基于单通道的直方图对标准检测结果集以及测试检测结果集进行图片相似度计算,取结果均值作为选手的主题曲实力值;
6、将获取的实力值合成到选手图片并输出
7、爬取微博测试选手相关评论,统计高频词输出图
8、对评论进行情感分析,输出总体评论积极与消极的对比饼图
提前披露效果
看了那么长我的肺腑之言,来看点效果,提升阅读欲望
首先我们接下来会用人体关键点识别模型去识别动作,识别的效果大概是这样的,可以看到我们把安崎小甜心的四肢都能识别到。

然后为了方便比对,我们直接把四肢关键点画线部分单独提取出来,方便后面对比
对比项:

计算每一帧的对比结果,得出评估分值,合成到选手图片上

最后通过爬取微博评论,经过LSTM模型进行情感分析后,得出选手的大众好感度对比
舞蹈实力评估
舞蹈实力评估主要对选手的舞蹈动作进行关键点检测与标准的动作进行对比,得出相似度,计算每一帧的动作相似度均值,得出选手舞蹈实力评估值。
模型介绍
主要使用的模型是pose_resnet50_mpii
人体骨骼关键点检测(Pose Estimation) 是计算机视觉的基础性算法之一,
在诸多计算机视觉任务起到了基础性的作用,如行为识别、人物跟踪、步态识别等相关领域。
具体应用主要集中在智能视频监控,病人监护系统,人机交互,虚拟现实,人体动画,智能家居,智能安防,运动员辅助训练等等。
环境准备
终端下载最新版的paddlehub以及paddlepaddle
pip install --upgrade paddlepaddle
pip install --upgrade paddlehub引入库
#相关库的导入
import os
import cv2
import paddlehub as hub
from moviepy.editor import *
from matplotlib import pyplot as plt
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from PIL import ImageFont, ImageDraw, Image
import requests打开终端下载模型
hub install pose_resnet50_mpii
引入模型
pose_resnet50_mpii = hub.Module(name="pose_resnet50_mpii")人体骨骼关键点检测
定义数据转化格式
函数change_data(result)
输入参数:人体骨骼关键点检测模型的输出结果
输出参数:关于人体关键点的全局变量
函数功能 :将位置点预测模型输出的数据形式转为预期的数据
def change_data(result):
global left_ankle,left_knee,left_hip,right_hip,right_knee,right_ankle,pelvis,thorax,upper_neck
global right_wrist,right_elbow,right_shoulder,left_shoulder,left_elbow,left_wrist,head_top
left_ankle = result['data']['left_ankle']
left_knee = result['data']['left_knee']
left_hip = result['data']['left_hip']
right_hip = result['data']['right_hip']
right_knee = result['data']['right_knee']
right_ankle = result['data']['right_ankle']
pelvis = result['data']['pelvis']
thorax = result['data']['thorax']
upper_neck = result['data']['upper neck']
head_top = result['data']['head top']
right_wrist = result['data']['right_wrist']
right_elbow = result['data']['right_elbow']
right_shoulder = result['data']['right_shoulder']
left_shoulder = result['data']['left_shoulder']
left_elbow = result['data']['left_elbow']
left_wrist = result['data']['left_wrist']将位置点连线
格式 cv2.circle(img, point, point_size, point_color, thickness)
输入参数:predict_img_path为输入图片的地址
输出参数:由两个分别是将人体关键点的线画在空白背景上/模型输出的图片上
功能:给图片划线并写入将图片按一定顺序保存
def write_line(predict_img_path,output_path):
global count_frame
print(predict_img_path)
img = cv2.imread(predict_img_path)
thickness = 2
point_color = (0, 255, 0) # BGR
# 格式cv2.circle(img, point, point_size, point_color, thickness)
cv2.line(img, (head_top[0],head_top[1]), (upper_neck[0],upper_neck[1]), point_color, 1)
cv2.line(img, (upper_neck[0],upper_neck[1]), (thorax[0],thorax[1]), point_color, thickness)
cv2.line(img, (upper_neck[0],upper_neck[1]), (left_shoulder[0],left_shoulder[1]), point_color, thickness)
cv2.line(img, (upper_neck[0],upper_neck[1]), (right_shoulder[0],right_shoulder[1]), point_color, thickness)
cv2.line(img, (left_shoulder[0],left_shoulder[1]), (left_elbow[0],left_elbow[1]), point_color, thickness)
cv2.line(img, (left_elbow[0],left_elbow[1]), (left_wrist[0],left_wrist[1]), point_color, thickness)
cv2.line(img, (right_shoulder[0],right_shoulder[1]), (right_elbow[0],right_elbow[1]), point_color, thickness)
cv2.line(img, (right_elbow[0],right_elbow[1]), (right_wrist[0],right_wrist[1]), point_color, thickness)
cv2.line(img, (left_hip[0],left_hip[1]), (left_knee[0],left_knee[1]), point_color, thickness)
cv2.line(img, (left_knee[0],left_knee[1]), (left_ankle[0],left_ankle[1]), point_color, thickness)
cv2.line(img, (right_hip[0],right_hip[1]), (right_knee[0],right_knee[1]), point_color, thickness)
cv2.line(img, (right_knee[0],right_knee[1]), (right_ankle[0],right_ankle[1]), point_color, thickness)
cv2.line(img, (thorax[0],thorax[1]), (left_hip[0],left_hip[1]), point_color, thickness)
cv2.line(img, (thorax[0],thorax[1]), (right_hip[0],right_hip[1]), point_color, thickness)
true_count = count_frame //2
cv2.imwrite(output_path+ str(true_count) +".jpg",img)
count_frame = count_frame +1连接监测点进行画线并输出
def GetOutputPose(frame_path,output_black_path,output_pose_path):
"输入需要进行关键点检测的图片目录,进行检测后分别输出原图加线的图片以及只有关键点连线的图"
"black_path:只有关键点连线的图片目录"
"frame_path:需要处理的图片目录"
"output_pose_path:带原图加连线的图片目录"
# 配置
num = os.listdir(frame_path)
for i in range(0,len(num)-1):
img_black = np.zeros((size_x,size_y,3), np.uint8)
img_black.fill(255)
img_black_path =output_black_path + str(i) + ".jpg"
cv2.imwrite(img_black_path,img_black)
for i in range(0,len(num)-1):
path_dict = frame_path + str(i) + ".jpg"
input_dict = {"image":[path_dict]}
print("This is OutputPose {} pictrue".format(i))
results = pose_resnet50_mpii.keypoint_detection(data=input_dict)
for result in results:
change_data(result)
write_line(path_dict,output_pose_path)
write_line(img_black_path,output_black_path)输出结果,获取每一帧的人体骨骼检测图

动作评估
上面我们已经生成了青春有你2的主题曲标准舞蹈的关键点画线集合,接下来,我们需要实现对比标准舞蹈动作以及测试舞蹈动作,计算每一帧图片的相似度,然后通过均值计算获取选手主题曲的舞蹈实力分数
相似值计算
基于直方图计算两个图片之间的相似度
import cv2
# 计算单通道的直方图的相似值
def calculate(image1, image2):
hist1 = cv2.calcHist([image1], [0], None, [256], [0.0, 255.0])
hist2 = cv2.calcHist([image2], [0], None, [256], [0.0, 255.0])
# 计算直方图的重合度
degree = 0
for i in range(len(hist1)):
if hist1[i] != hist2[i]:
degree = degree + (1 - abs(hist1[i] - hist2[i]) / max(hist1[i], hist2[i]))
else:
degree = degree + 1
degree = degree / len(hist1)
return degree将实力值合成到测试选手的图片上面
from PIL import Image
from PIL import ImageFilter
from PIL import ImageEnhance
from PIL import ImageDraw , ImageFont
def draw_text(bg_path,text,output_path):
"""
实现图片上面叠加中文
bg_path:需要加中文的图片
text: 添加的中文内容
output_path: 合成后输出的图片路径
"""
im = Image.open(bg_path)
draw = ImageDraw.Draw(im)
fnt = ImageFont.truetype(r'fonts/SimHei.ttf',32)
draw.text((100, 600), text, fill='red', font=fnt)
im.show()
im.save(output_path)输出结果

大众好感分析
主要是基于LSTM模型对微博评论进行情感分析
1.爬取与测试选手相关微博评论
2.训练模型
3.得出选手好感度以及搜索输出选手话题词频统计
模型介绍
情感倾向分析(Sentiment Classification,简称Senta)针对带有主观描述的中文文本,可自动判断该文本的情感极性类别并给出相应的置信度,能够帮助企业理解用户消费习惯、分析热点话题和危机舆情监控,为企业提供有利的决策支持。该模型基于一个LSTM结构,情感类型分为积极、消极。该PaddleHub Module支持预测和Fine-tune。
引入模型
下载
hub install senta_lstm
引入
senta = hub.Module(name="senta_lstm")爬取微博评论
import requests
from pyquery import PyQuery as pq
import time
from urllib.parse import quote
import os
def get_page(page):
"""
通过微博api获取微博数据
page: 分页页数
"""
headers = {
'Host': 'm.weibo.cn',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
url = 'https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D'+quote(m)+'&page_type=searchall&page='+str(page)#将你检索内容转为超链接
print(url)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(page)
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
def parse_page(json):
f_comments=open('comment/comment.txt','a')
f_user=open('comment/weibo_user.txt','a')
if json:
items = json.get('data').get('cards')
for i in items:
item = i.get('mblog')
if item == None:
continue
weibo = {}
weibo['id'] = item.get('id')
weibo['text'] = pq(item.get('text')).text()
weibo['name'] = item.get('user').get('screen_name')
if item.get('longText') != None :#要注意微博分长文本与文本,较长的文本在文本中会显示不全,故我们要判断并抓取。
weibo['longText'] = item.get('longText').get('longTextContent')
else:
weibo['longText'] =None
# print(weibo['name'])
# print(weibo['text'])
if weibo['longText'] !=None:
f_comments.write(weibo['longText'])
f_comments.write(weibo['text']+'\n')
f_user.write(weibo['name']+'\n')
# yield weibo
f_comments.close()
f_user.close()
if __name__ == '__main__':
m = '谢可寅'
n = 50
for page in range(1,n+1):
time.sleep(1) #设置睡眠时间,防止被封号
json = get_page(page)
parse_page(json)爬取评论结果:

清洗评论以及去除停用词
由于评论中含有一些表情包什么的,得处理一下
import re #正则匹配
import jieba #中文分词
#去除文本中特殊字符
def clear_special_char(content):
'''
正则处理特殊字符
参数 content:原文本
return: 清除后的文本
'''
f_clear = open('comment/clear_comment.txt','a')
clear_content = re.findall('[\u4e00-\u9fa5a-zA-Z0-9]+',content,re.S) #只要字符串中的中文,字母,数字
str=','.join(clear_content)
f_clear.write(str+'\n')
f_clear.close
return str
def fenci(content):
'''
利用jieba进行分词
参数 text:需要分词的句子或文本
return:分词结果
'''
jieba.load_userdict(r"dic/user_dic.txt")
seg_list = jieba.cut(content)
return seg_list
def stopwordslist():
'''
创建停用词表
参数 file_path:停用词文本路径
return:停用词list
'''
stopwords = [line.strip() for line in open('work/stopwords.txt',encoding='UTF-8').readlines()]
acstopwords=['哦','因此','不然','谢可寅','超话']
stopwords.extend(acstopwords)
return stopwords
import pandas as pd
def movestopwords(sentence_depart,stopwords):
'''
去除停用词,统计词频
参数 file_path:停用词文本路径 stopwords:停用词list counts: 词频统计结果
return:None
'''
segments = []
# 去停用词
for word in sentence_depart:
if word not in stopwords:
if word != '\t':
# outstr += word
# outstr += " "
segments.append(word)
return segments处理结果:

统计选手高频TOP10词
通过微博评论 统计选手高频TOP10词
import collections
def drawcounts(segments):
'''
绘制词频统计表
参数 counts: 词频统计结果 num:绘制topN
return:none
'''
# 词频统计
word_counts = collections.Counter(segments) # 对分词做词频统计
word_counts_top10 = word_counts.most_common(10) # 获取前10最高频的词
print (word_counts_top10)
dic=dict(word_counts_top10)
print(dic)
x_values=[]
y_values=[]
for k in dic:
x_values.append(k)
y_values.append(dic[k])
# 设置显示中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.figure(figsize=(20,15))
plt.bar(range(len(y_values)), y_values,color='r',tick_label=x_values,facecolor='#9999ff',edgecolor='white')
# 这里是调节横坐标的倾斜度,rotation是度数,以及设置刻度字体大小
plt.xticks(rotation=45,fontsize=20)
plt.yticks(fontsize=20)
plt.legend()
plt.title('''谢可寅微博评论词频统计''',fontsize = 24)
plt.savefig('highwords.jpg')
plt.show()
return word_counts
if __name__ == '__main__':
stopwords=stopwordslist()
f = open(r"comment/comment.txt")
line = f.readline()
segments=[]
while line:
line = f.readline()
clear_line=clear_special_char(line)
seg_list= fenci(clear_line)
segments_list=movestopwords(seg_list,stopwords)
segments.extend(segments_list)
f.close()
drawcounts(segments)输出结果:

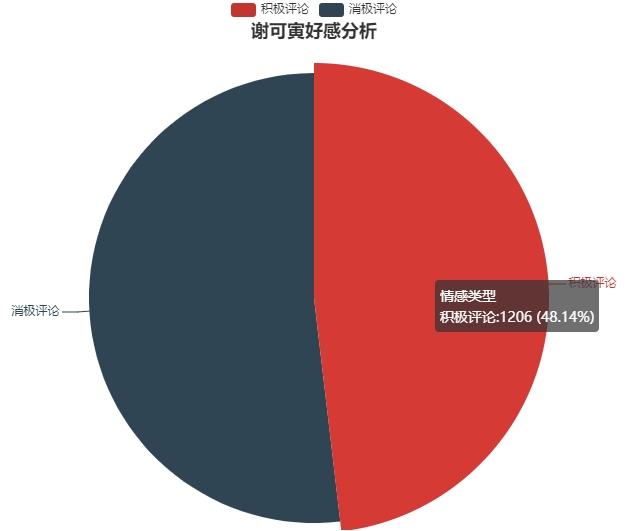
对评论进行情感分析
定义饼图绘制方法
使用pyecharts库进行饼图绘制
# from pyecharts import Pie
# from pyecharts.charts.basic_charts.pie import Pie
from pyecharts.charts import Pie
from pyecharts import options as opts
def draw_pie(data,labels):
"""
绘制饼图
"""
data_pie = [list(i) for i in zip(labels,data)]
# 创建实例对象
pie = Pie(init_opts=opts.InitOpts(width='1000px',height='600px'))
# 添加数据
pie.add(series_name="情感类型",data_pair=data_pie)
# 设置全局项
pie.set_global_opts(title_opts=opts.TitleOpts(title="谢可寅好感分析",pos_left='center',pos_top=20))
#设置每项数据占比
pie.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item',formatter="{a} <br/> {b}:{c} ({d}%)"))
pie.render("pie_charts.html")lstm模型分析评论
if __name__ == '__main__':
f = open(r"comment/clear_comment.txt")
line = f.readline()
comments=[]
while line:
comments.append(line)
line = f.readline()
f.close()
input_dict = {"text": comments}
## 情感分析
results = senta.sentiment_classify(data=input_dict,batch_size=5)
positive_num=0
negative_num=0
for result in results:
if result['sentiment_key'] == 'positive':
positive_num+=1
else:
negative_num+=1
print("total:%f,pos:%f,neg:%f"%(len(results),positive_num,negative_num))
data=[positive_num,negative_num]
labels=['积极评论','消极评论']
draw_pie(data,labels)输出结果:
看完了这篇文章,相信你对如何用python实现专业评估舞蹈程序有了一定的了解,想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



