这篇文章将为大家详细讲解有关Python中的垃圾回收机制实例,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
1. 引用计数器
1.1 环状双向链表 refchain
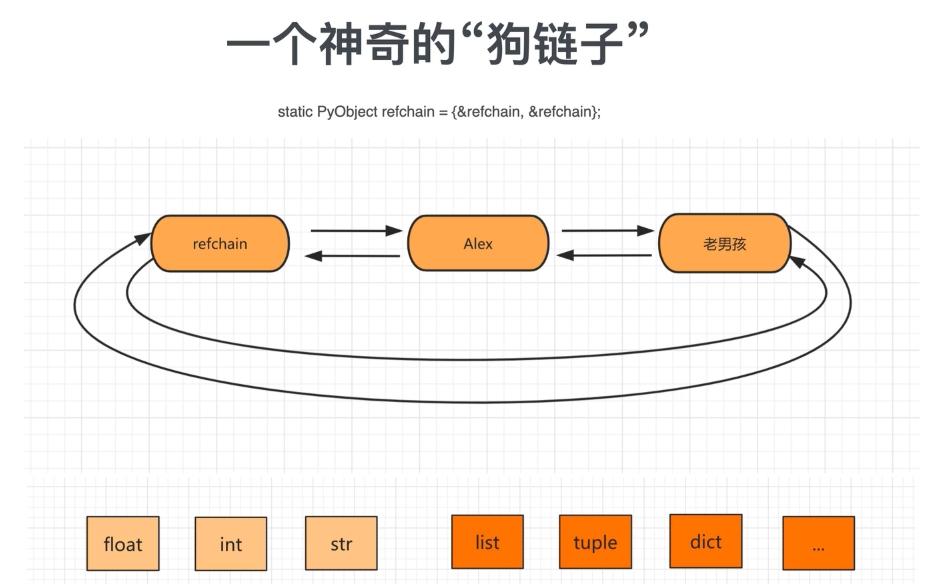
在python程序中创建的任何对象都会放在refchain链表中。
#define PyObject_HEAD PyObject ob_base;
#define PyObject_VAR_HEAD PyVarObject ob_base;
// 宏定义,包含 上一个、下一个,用于构造双向链表用。(放到refchain链表中时要用到)
#define _PyObject_HEAD_EXTRA \
struct _object *_ob_next; \
struct _object *_ob_prev;name = "阿玮"
age = 18
hobby = ["健身", "美女"]内部会创建一些数据 [ 上一个对象、下一个对象、类型、引用个数 ]
name = "阿玮"
new = name # 引用个数变成2
内部会创建一些数据 [ 上一个对象、下一个对象、类型、引用个数、val=18 ]
age = 18
内部会创建一些数据 [ 上一个对象、下一个对象、类型、引用个数、items=元素、元素个数 ]
hobby = ["健身", "美女"]#define PyObject_HEAD PyObject ob_base;
#define PyObject_VAR_HEAD PyVarObject ob_base;
// 宏定义,包含 上一个、下一个,用于构造双向链表用。(放到refchain链表中时要用到)
#define _PyObject_HEAD_EXTRA \
struct _object *_ob_next; \
struct _object *_ob_prev;
typedef struct _object {
_PyObject_HEAD_EXTRA; // 用于构造双向链表
Py_ssize_t ob_refcnt; // 引用计数器
struct _typeobject *ob_type; // 数据类型
} PyObject;
typedef struct {
PyObject ob_base; // PyObject对象
Py_ssize_t ob_size; // Number of items in variable part,即:元素个数
} PyVarObject;在C源码中如何体现每个对象中都有的相同的值:PyObject结构体(4个值)。
有多个元素组成的对象:PyObject结构体(4个值)+ ob_size = PyVarObject。
1.2 类型封装结构体
float类型
typedef struct {
PyObject_HEAD;
double ob_fval;
};
data = 3.14;
内部会创建:
_ob_next = refchain中的下一个对象
_ob_prev = refchain中的上一个对象
ob_refcnt = 1
ob_type = float
ob_fval = 3.14int类型
struct _longobect {
PyObject_VAR_HEAD;
digit ob_dit[1];
};
/* Long (arbitrary precision) integer object interface */
typedef struct _longobject PyLongObject; /* Revealed in longintrepr.h */list类型
typedef struct {
PyObject_VAR_HEAD;
PyObject ** ob_item;
Py_ssize_t allocated;
} PyListObject;tuple类型
typedef struct {
PyObject_VAR_HEAD;
PyObject *ob_item[1];
} PyTupleObject;dict类型
typedef struct {
PyObject_HEAD;
Py_ssize_t ma_used;
PyDictKeyObject *ma_keys;
PyObject **ma_values;
} PyDictObject;1.3 引用计数器
v1 = 3.14
v2 = 999
v3 = (1,2,3)当python程序运行时,会根据数据类型的不同找到其结构体,根据结构体中的字段来进行创建相关的数据,然后将对象添加到refchain双向链表中。
在C源码中有两个关键的结构体:PyObject、PyVarObject。
每个对象中有 ob_refcnt 就是引用计数器,值默认为1,当有其他变量引用这个对象时,引用计数器就会发生变化。
引用
a = 99999
b = a
# 此时 99999 这个对象引用计数器的值为2
'''
下面情况会导致引用计数器+1:
1.对象被创建,如 a = 2
2.对象被引用,如 b = a
3.对象被作为参数,传入到一个函数中
4.对象作为一个元素,存储在容器中
可以通过sys包中的getrefcount()来获取一个名称所引用的对象当前的引用计数器的值(注意这里getrefcount()本身会使得引用计数器+1)
'''删除引用
a = 99999
b = a
# b变量删除,b对应对象的引用计数器-1
def b
# a变量删除,a对应对象的引用计数器-1
'''
下面情况会导致引用计数器-1:
1.变量被显示销毁 del
2.变量被赋予新的对象
3.一个对象离开它的作用域
4.对象所在的容器被销毁或从容器中删除对象
'''
# 当一个对象的引用计数器为0时,意味着没有人再使用这个对象了,这个对象就是垃圾,垃圾回收。
# 回收:1.对象从rechain链表移出。2.将对象销毁,内存归还。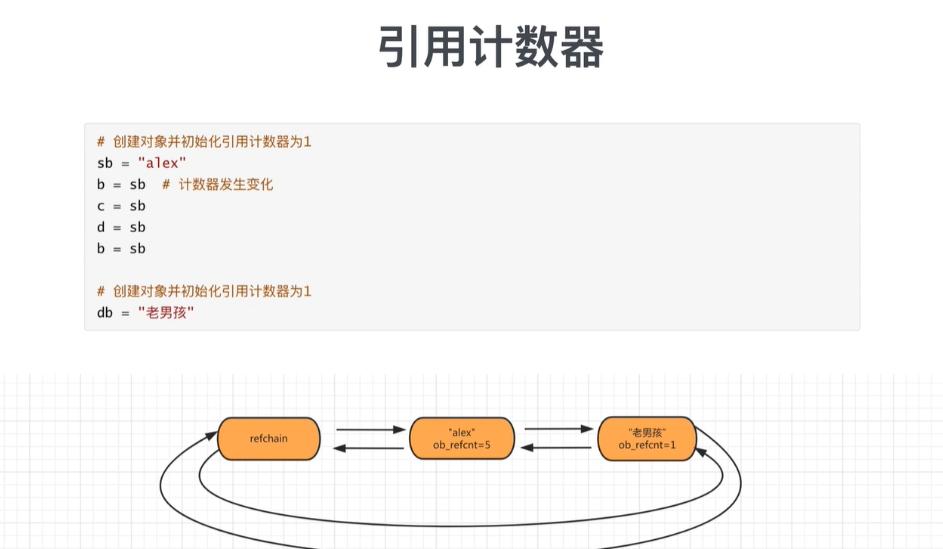
1.4 循环引用问题
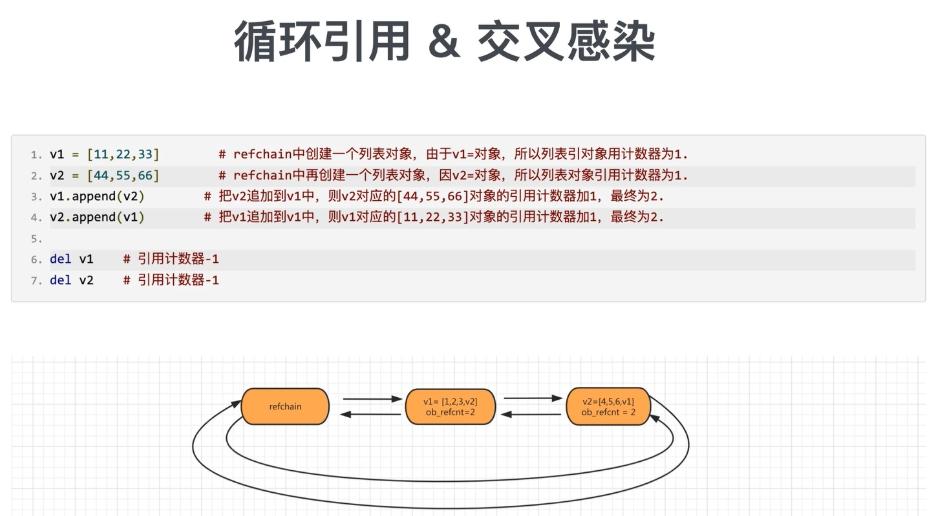
由于 v1 指向的对象引用了 v2,v2 指向的对象也引用了 v1,当将 v1、v2 两个变量删除时,虽然引用计数器会减1,但是两个对象间还存在循环引用,而此时已经没有变量能去指向它们,这两个对象就会在内存中常驻无法处理。
2. 标记清除
目的:为了解决引用计数器循环引用的问题。
实现:在python的底层再维护一个链表,链表中专门放哪些可能存在循环应用的对象(容器类对象:list、tuple、dict、set)。
在Python内部某种情况下触发,会去扫描可能存在循环引用的链表中的每个元素,检查是否有循环引用,如果有则让双方的引用计数器-1;如果是0则垃圾回收。
2.1 标记阶段
遍历所有对象,如果是可达的(reachable),也就是还有对象引用它,那么就将该对象标记为可达
该阶段从某个对象开始扫描(而不是从变量),如果变量A引用了变量B,则将变量B的引用计数器-1(指的是gc_ref),然后扫描变量B
如图所示,link1、link2、link3形成了一个引用环,link4自引用。从link1开始扫描,link1引用了link2,则link2的gc_ref-1,接着扫描link2…
像这也将链表中所有对象考察一遍后,两个链表中的对象ref_count和gc_ref,这一步操作就相当于解除了循环引用对引用计数器的影响
如果gc_ref为0,则将对象标记为 GC_TENTATIVELY_UNREACHABLE,并且被移至”Unreachable“链表中,如下图link3、link4(我觉得link2应该也是)
如果gc_ref不为0,那么这个对象会被标记为可达的GC_REACHABLE,同时当gc发现有一个节点是可达的,那么它会递归式的从该节点触发将所有可达的节点标记为GC_REACHABLE,这样把link2、link3救回来
2.2 清除阶段
将被标记成 GC_UNREACHABLE 的对象销毁,内存归还(也就是Unreachable链表中的对象)
2.3 标记清除的问题
在标记清除算法开始后,会暂停整个应用程序,等待标记清除结束后才会恢复应用的运行,且对循环引用的扫描代价大,每次扫描耗时可能很久
3. 分代回收
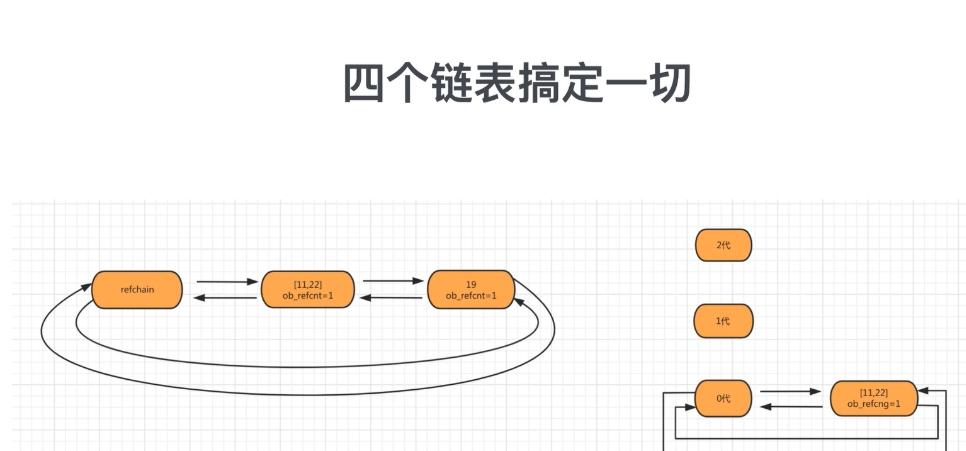
将可能存在循环引用的对象维护成3个链表:
0代:0代中对象个数达到700个扫描一次
1代:0代扫描10次,则1代扫描一次
2代:1代扫描10次,则2代扫描一次
4. 小结
在python中维护了一个refchain的双向环状链表,这个链表中存储程序创建的所有对象,每种类型的对象都有一个ob_refcnt引用计数器的值,当引用计数器变为0时会进行垃圾回收(对象销毁、refchain中移出)。
但是,在python中对于那些可以有多个元素组成的对象可能会存在循环引用的问题,为了解决这个问题,python又引入了标记清除和分代回收,在其内部维护了4个链表,分别为:
refchain
2代
1代
0代
在源码内部,当达到各自的阈值时,就会触发扫描链表进行标记清除的动作(有循环引用则各自-1)。But,源码内部在上述流程中提出了优化机制。
关于Python中的垃圾回收机制实例就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



