зҲ¬иҷ«жҳҜд»Җд№Ҳ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…ізҲ¬иҷ«жҳҜд»Җд№ҲпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
дёҖгҖҒзҲ¬иҷ«жҳҜд»Җд№Ҳпјҹ
еҰӮжһңжҲ‘们жҠҠдә’иҒ”зҪ‘жҜ”дҪңдёҖеј еӨ§зҡ„иңҳиӣӣзҪ‘пјҢж•°жҚ®дҫҝжҳҜеӯҳж”ҫдәҺиңҳиӣӣзҪ‘зҡ„еҗ„дёӘиҠӮзӮ№пјҢиҖҢзҲ¬иҷ«е°ұжҳҜдёҖеҸӘе°ҸиңҳиӣӣпјҢжІҝзқҖзҪ‘з»ңжҠ“еҸ–иҮӘе·ұзҡ„зҢҺзү©пјҲж•°жҚ®пјүзҲ¬иҷ«жҢҮзҡ„жҳҜпјҡеҗ‘зҪ‘з«ҷеҸ‘иө·иҜ·жұӮпјҢиҺ·еҸ–иө„жәҗеҗҺеҲҶжһҗ并жҸҗеҸ–жңүз”Ёж•°жҚ®зҡ„зЁӢеәҸгҖӮ
д»ҺжҠҖжңҜеұӮйқўжқҘиҜҙе°ұжҳҜ йҖҡиҝҮзЁӢеәҸжЁЎжӢҹжөҸи§ҲеҷЁиҜ·жұӮз«ҷзӮ№зҡ„иЎҢдёәпјҢжҠҠз«ҷзӮ№иҝ”еӣһзҡ„HTMLд»Јз Ғ/JSONж•°жҚ®/дәҢиҝӣеҲ¶ж•°жҚ®пјҲеӣҫзүҮгҖҒи§Ҷйў‘пјү зҲ¬еҲ°жң¬ең°пјҢиҝӣиҖҢжҸҗеҸ–иҮӘе·ұйңҖиҰҒзҡ„ж•°жҚ®пјҢеӯҳж”ҫиө·жқҘдҪҝз”Ёпјӣ
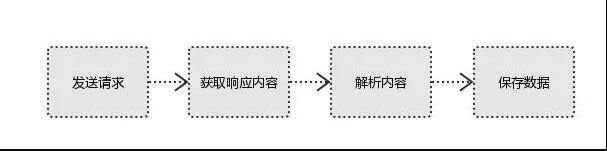
дәҢгҖҒзҲ¬иҷ«зҡ„еҹәжң¬жөҒзЁӢ
з”ЁжҲ·иҺ·еҸ–зҪ‘з»ңж•°жҚ®зҡ„ж–№ејҸпјҡ
ж–№ејҸ1пјҡжөҸи§ҲеҷЁжҸҗдәӨиҜ·жұӮвҖ”>дёӢиҪҪзҪ‘йЎөд»Јз ҒвҖ”>и§ЈжһҗжҲҗйЎөйқў
ж–№ејҸ2пјҡжЁЎжӢҹжөҸи§ҲеҷЁеҸ‘йҖҒиҜ·жұӮ(иҺ·еҸ–зҪ‘йЎөд»Јз Ғ)->жҸҗеҸ–жңүз”Ёзҡ„ж•°жҚ®->еӯҳж”ҫдәҺж•°жҚ®еә“жҲ–ж–Ү件дёӯ
зҲ¬иҷ«иҰҒеҒҡзҡ„е°ұжҳҜж–№ејҸ2гҖӮ
1гҖҒеҸ‘иө·иҜ·жұӮ
дҪҝз”Ёhttpеә“еҗ‘зӣ®ж Үз«ҷзӮ№еҸ‘иө·иҜ·жұӮпјҢеҚіеҸ‘йҖҒдёҖдёӘRequest
RequestеҢ…еҗ«пјҡиҜ·жұӮеӨҙгҖҒиҜ·жұӮдҪ“зӯү
RequestжЁЎеқ—зјәйҷ·пјҡдёҚиғҪжү§иЎҢJS е’ҢCSS д»Јз Ғ
2гҖҒиҺ·еҸ–е“Қеә”еҶ…е®№
еҰӮжһңжңҚеҠЎеҷЁиғҪжӯЈеёёе“Қеә”пјҢеҲҷдјҡеҫ—еҲ°дёҖдёӘResponse
ResponseеҢ…еҗ«пјҡhtmlпјҢjsonпјҢеӣҫзүҮпјҢи§Ҷйў‘зӯү
3гҖҒи§ЈжһҗеҶ…е®№
и§Јжһҗhtmlж•°жҚ®пјҡжӯЈеҲҷиЎЁиҫҫејҸпјҲREжЁЎеқ—пјүпјҢ第дёүж–№и§Јжһҗеә“еҰӮBeautifulsoupпјҢpyqueryзӯү
и§Јжһҗjsonж•°жҚ®пјҡjsonжЁЎеқ—
и§ЈжһҗдәҢиҝӣеҲ¶ж•°жҚ®:д»Ҙwbзҡ„ж–№ејҸеҶҷе…Ҙж–Ү件
4гҖҒдҝқеӯҳж•°жҚ®
ж•°жҚ®еә“пјҲMySQLпјҢMongdbгҖҒRedisпјү
ж–Ү件
дёүгҖҒhttpеҚҸи®® иҜ·жұӮдёҺе“Қеә”
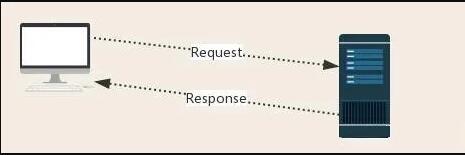
Requestпјҡз”ЁжҲ·е°ҶиҮӘе·ұзҡ„дҝЎжҒҜйҖҡиҝҮжөҸи§ҲеҷЁпјҲsocket clientпјүеҸ‘йҖҒз»ҷжңҚеҠЎеҷЁпјҲsocket serverпјү
ResponseпјҡжңҚеҠЎеҷЁжҺҘ收иҜ·жұӮпјҢеҲҶжһҗз”ЁжҲ·еҸ‘жқҘзҡ„иҜ·жұӮдҝЎжҒҜпјҢ然еҗҺиҝ”еӣһж•°жҚ®пјҲиҝ”еӣһзҡ„ж•°жҚ®дёӯеҸҜиғҪеҢ…еҗ«е…¶д»–й“ҫжҺҘпјҢеҰӮпјҡеӣҫзүҮпјҢjsпјҢcssзӯүпјү
psпјҡжөҸи§ҲеҷЁеңЁжҺҘ收ResponseеҗҺпјҢдјҡи§Јжһҗе…¶еҶ…е®№жқҘжҳҫзӨәз»ҷз”ЁжҲ·пјҢиҖҢзҲ¬иҷ«зЁӢеәҸеңЁжЁЎжӢҹжөҸи§ҲеҷЁеҸ‘йҖҒиҜ·жұӮ然еҗҺжҺҘ收ResponseеҗҺпјҢжҳҜиҰҒжҸҗеҸ–е…¶дёӯзҡ„жңүз”Ёж•°жҚ®гҖӮ
еӣӣгҖҒ request
1гҖҒиҜ·жұӮж–№ејҸпјҡ
еёёи§Ғзҡ„иҜ·жұӮж–№ејҸпјҡGET / POST
2гҖҒиҜ·жұӮзҡ„URL
urlе…Ёзҗғз»ҹдёҖиө„жәҗе®ҡдҪҚз¬ҰпјҢз”ЁжқҘе®ҡд№үдә’иҒ”зҪ‘дёҠдёҖдёӘе”ҜдёҖзҡ„иө„жәҗ дҫӢеҰӮпјҡдёҖеј еӣҫзүҮгҖҒдёҖдёӘж–Ү件гҖҒдёҖж®өи§Ҷйў‘йғҪеҸҜд»Ҙз”Ёurlе”ҜдёҖзЎ®е®ҡ
urlзј–з Ғ
https://www.baidu.com/s?wd=еӣҫзүҮ
еӣҫзүҮдјҡиў«зј–з ҒпјҲзңӢзӨәдҫӢд»Јз Ғпјү
зҪ‘йЎөзҡ„еҠ иҪҪиҝҮзЁӢжҳҜпјҡ
еҠ иҪҪдёҖдёӘзҪ‘йЎөпјҢйҖҡеёёйғҪжҳҜе…ҲеҠ иҪҪdocumentж–ҮжЎЈпјҢ
еңЁи§Јжһҗdocumentж–ҮжЎЈзҡ„ж—¶еҖҷпјҢйҒҮеҲ°й“ҫжҺҘпјҢеҲҷй’ҲеҜ№и¶…й“ҫжҺҘеҸ‘иө·дёӢиҪҪеӣҫзүҮзҡ„иҜ·жұӮ
3гҖҒиҜ·жұӮеӨҙ
User-agentпјҡиҜ·жұӮеӨҙдёӯеҰӮжһңжІЎжңүuser-agentе®ўжҲ·з«Ҝй…ҚзҪ®пјҢжңҚеҠЎз«ҜеҸҜиғҪе°ҶдҪ еҪ“еҒҡдёҖдёӘйқһжі•з”ЁжҲ·hostпјӣ
cookiesпјҡcookieз”ЁжқҘдҝқеӯҳзҷ»еҪ•дҝЎжҒҜ
жіЁж„ҸпјҡдёҖиҲ¬еҒҡзҲ¬иҷ«йғҪдјҡеҠ дёҠиҜ·жұӮеӨҙ
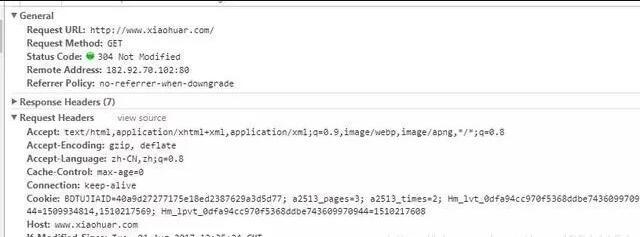
иҜ·жұӮеӨҙйңҖиҰҒжіЁж„Ҹзҡ„еҸӮж•°пјҡ
пјҲ1пјүReferrerпјҡи®ҝй—®жәҗиҮіе“ӘйҮҢжқҘпјҲдёҖдәӣеӨ§еһӢзҪ‘з«ҷпјҢдјҡйҖҡиҝҮReferrer еҒҡйҳІзӣ—й“ҫзӯ–з•ҘпјӣжүҖжңүзҲ¬иҷ«д№ҹиҰҒжіЁж„ҸжЁЎжӢҹпјү
пјҲ2пјүUser-Agent:и®ҝй—®зҡ„жөҸи§ҲеҷЁпјҲиҰҒеҠ дёҠеҗҰеҲҷдјҡиў«еҪ“жҲҗзҲ¬иҷ«зЁӢеәҸпјү
пјҲ3пјүcookieпјҡиҜ·жұӮеӨҙжіЁж„ҸжҗәеёҰ
4гҖҒиҜ·жұӮдҪ“
иҜ·жұӮдҪ“еҰӮжһңжҳҜgetж–№ејҸпјҢиҜ·жұӮдҪ“жІЎжңүеҶ…е®№ пјҲgetиҜ·жұӮзҡ„иҜ·жұӮдҪ“ж”ҫеңЁ urlеҗҺйқўеҸӮж•°дёӯпјҢзӣҙжҺҘиғҪзңӢеҲ°пјүеҰӮжһңжҳҜpostж–№ејҸпјҢиҜ·жұӮдҪ“жҳҜformat datapsпјҡ1гҖҒзҷ»еҪ•зӘ—еҸЈпјҢж–Ү件дёҠдј зӯүпјҢдҝЎжҒҜйғҪдјҡиў«йҷ„еҠ еҲ°иҜ·жұӮдҪ“еҶ…2гҖҒзҷ»еҪ•пјҢиҫ“е…Ҙй”ҷиҜҜзҡ„з”ЁжҲ·еҗҚеҜҶз ҒпјҢ然еҗҺжҸҗдәӨпјҢе°ұеҸҜд»ҘзңӢеҲ°postпјҢжӯЈзЎ®зҷ»еҪ•еҗҺйЎөйқўйҖҡеёёдјҡи·іиҪ¬пјҢж— жі•жҚ•жҚүеҲ°post
дә”гҖҒ е“Қеә”Response
1гҖҒе“Қеә”зҠ¶жҖҒз Ғ
200пјҡд»ЈиЎЁжҲҗеҠҹ
301пјҡд»ЈиЎЁи·іиҪ¬
404пјҡж–Ү件дёҚеӯҳеңЁ
403пјҡж— жқғйҷҗи®ҝй—®
502пјҡжңҚеҠЎеҷЁй”ҷиҜҜ
2гҖҒrespone header
е“Қеә”еӨҙйңҖиҰҒжіЁж„Ҹзҡ„еҸӮж•°пјҡ
пјҲ1пјүSet-Cookie:BDSVRTM=0; path=/пјҡеҸҜиғҪжңүеӨҡдёӘпјҢжҳҜжқҘе‘ҠиҜүжөҸи§ҲеҷЁпјҢжҠҠcookieдҝқеӯҳдёӢжқҘ
пјҲ2пјүContent-LocationпјҡжңҚеҠЎз«Ҝе“Қеә”еӨҙдёӯеҢ…еҗ«Locationиҝ”еӣһжөҸи§ҲеҷЁд№ӢеҗҺпјҢжөҸи§ҲеҷЁе°ұдјҡйҮҚж–°и®ҝй—®еҸҰдёҖдёӘйЎөйқў
3гҖҒpreviewе°ұжҳҜзҪ‘йЎөжәҗд»Јз Ғ
JSOж•°жҚ®
еҰӮзҪ‘йЎөhtmlпјҢеӣҫзүҮ
дәҢиҝӣеҲ¶ж•°жҚ®зӯү
е…ӯгҖҒжҖ»з»“
1гҖҒжҖ»з»“зҲ¬иҷ«жөҒзЁӢпјҡ
зҲ¬еҸ–вҖ”>и§ЈжһҗвҖ”>еӯҳеӮЁ
2гҖҒзҲ¬иҷ«жүҖйңҖе·Ҙе…·пјҡ
иҜ·жұӮеә“пјҡrequests,seleniumпјҲеҸҜд»Ҙй©ұеҠЁжөҸи§ҲеҷЁи§ЈжһҗжёІжҹ“CSSе’ҢJSпјҢдҪҶжңүжҖ§иғҪеҠЈеҠҝпјҲжңүз”ЁжІЎз”Ёзҡ„зҪ‘йЎөйғҪдјҡеҠ иҪҪпјүпјӣпјү и§Јжһҗеә“пјҡжӯЈеҲҷпјҢbeautifulsoupпјҢpyquery еӯҳеӮЁеә“пјҡж–Ү件пјҢMySQLпјҢMongodbпјҢRedis
е…ідәҺзҲ¬иҷ«жҳҜд»Җд№Ҳе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





