这篇文章我们主要了解高可用集群概念及工作原理,以及高可用集群的逻辑架构等。
ll 本文导航
· 什么是高可用集群?
· 高可用集群有哪些特点?
· 高可用集群的逻辑架构
· 高可用集群的解决方案
· 高可用集群的工作模型
ll 要求
掌握高可用集群的基础原理与逻辑架构。
什么是高可用集群?
所谓高可用集群,即当前服务器出现故障时,可以将该服务器中的服务、资源、IP等转移到另外一台服务器上,从而满足业务的持续性;这两台或多台服务器构成了服务器高可用集群。
对于客户端来说,集群就像是一台服务器,因为集群运行的是同一种服务,即使其中有的服务器宕机或无法通信时,也不会对业务造成影响。
高可用集群有哪些特点?
一、高可用服务
集群最大的目的和作用就是实现服务的高可用性,其最终目的是保证业务不会因为线路、硬件、软件故障而导致的服务不可用。
二、度量标准(服务可用性)
由系统可靠性(Availability)和可维护性(maintainabilit)来度量
计算方式:HA=MTTF(平均无故障事件)/(MTTF+MTTR(平均修复事件))*100%
99% 全年服务中断时间不超过4天
99.9% 全年服务中断时间不超过10个小时
99.99% 全年服务中断时间不超过1个小时
99.999% 全年服务中断时间不超过6分钟
三、集群节点
集群存在所有主机都称为节点,每HA集群最低要求需有2个节点;正常来说,节点数最好为奇数。在生产环境中,HA集群的节点数至少为3个,可以降低发生脑裂的概率。
四、集群服务与资源
集群服务通常包括多个资源,多个资源组成某种集群服务。如mysql高可用服务,其资源包括vip、mysqld、共享存储等。对于集群服务的管理,实际上就是对资源的管理。
五、脑裂、资源争用、资源隔离
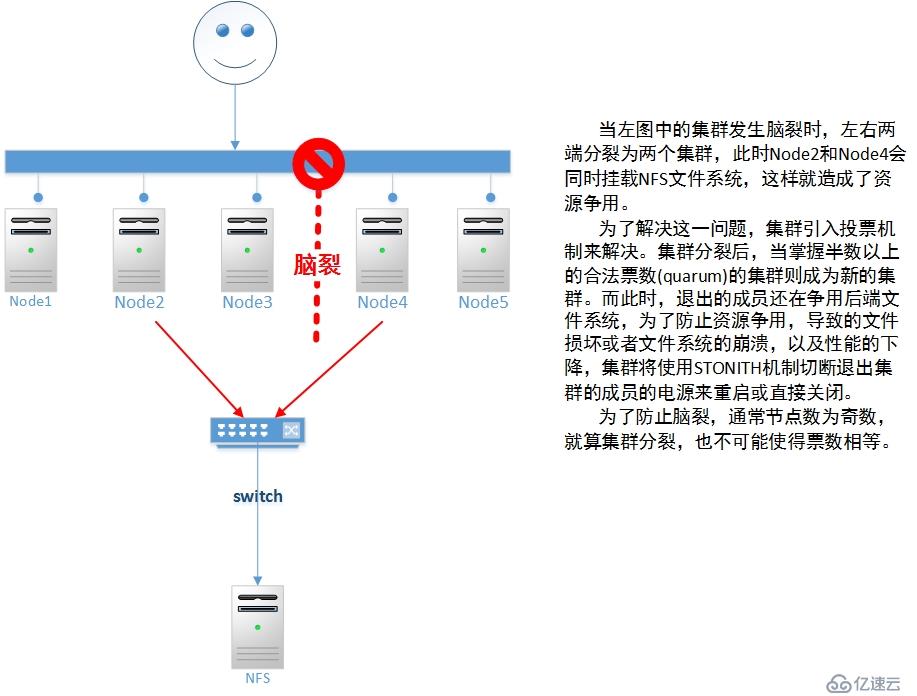
脑裂:因某种特殊原因造成集群分裂成两个小集群,而这两个小集群互相不能正常通信,此时,就会发生闹裂(Brain Split)现象。
资源争用:当一个集群中因特殊情况分裂成两个小集群,且这两个集群都不能通信时,这时可能会造成资源争用的情况;分裂情况发生后,如果没有及时的决策,那么可能会因为两个小集群同时使用一个文件系统,而造成后端共享存储中文件损坏,甚至造成整个文件系统的崩溃。显然,这种情况是不允许发生的。
资源隔离:主要为了解决资源争用的问题。资源隔离分为节点级别隔离和资源级别隔离。所谓节点级别隔离指当集群发生分裂时,即发生脑裂现象后,通过STONITH机制将资源隔离,并通过仲裁机制将分裂的票数不足的集群退出集群。STONITH指通过硬件设备,使得退出的主机重启或关机,或者通过交换机阻断退出的集群向外通信和资源通信的能力。
资源隔离的解决方案:
1、当集群分裂成两个小集群时会发生资源争用的情况,为避免争用后端存储系统而造成灾难性的系
统崩溃,集群系统引入了投票机制,只有拥有半数以上合法票数的集群才能存活,否则就推出集群
系统。
2、当集群为偶数时,如果分裂,两边可能都掌握相等的票数;因此,集群系统不应该为偶数,如果
是偶数则需要一个额外的ping节点参与投票。
3、票数不足的集群退出集群服务后,为了保证它不会争用资源需要STONITH机制来进行资源隔离。
所以,为了防止脑裂,集群节点数一般为奇数,就算集群分裂,也不可能使得两个集群的票数相等。
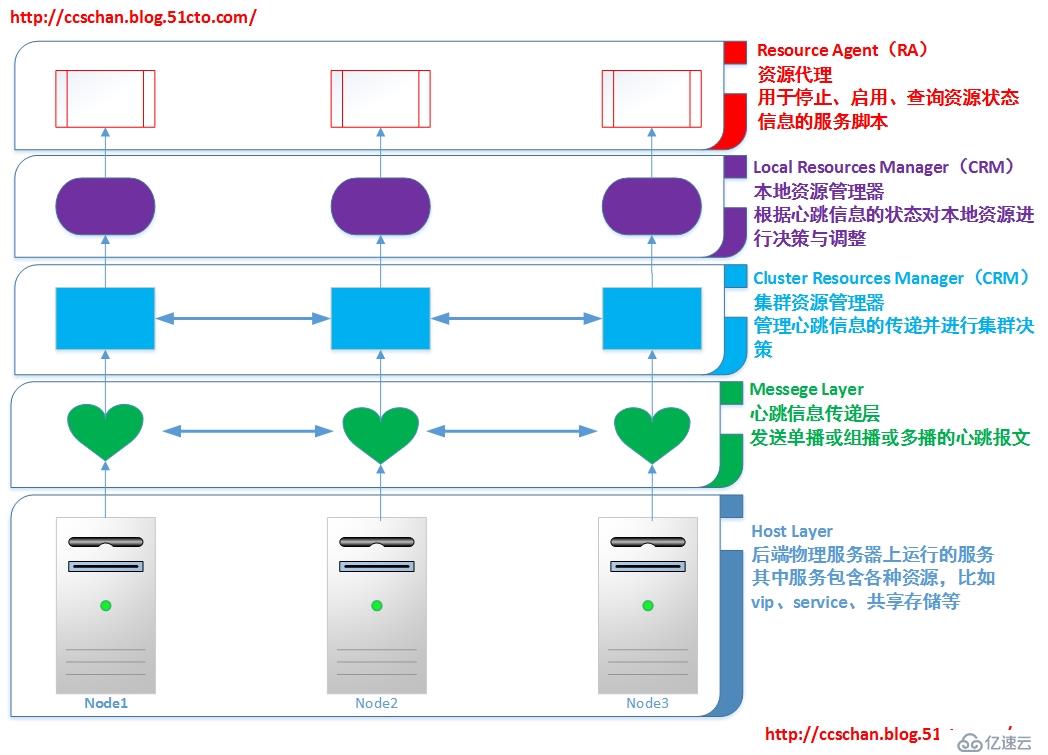
高可用集群的逻辑架构
高可用集群的解决方案
一、基于【CentOS | RHEL】5:
1、自带: RHCS(cman+rgmanager)
2、选用第三方:corosync+pacemaker, heartbeat(v1或v2), keepalived
二、基于【CentOS | RHEL】6:
1、RHCS(cman+rgmanager)
2、corosync+rgmanager
3、cman+pacemaker
4、heartbeat v3 + pacemaker:6.4之前
5、keepalived:6.4之后
高可用集群的工作模型
A/P:两个节点,工作于主备模型;
N-M: N>M,N个节点,M个服务,活动节点为N,备用节点为N-M;
N-N:N个节点,N个服务;
A/A:双主模型:两个节点都是活动的;
资源转移的方式:
rgmanager:failover domain(故障切换域), priority(优先级)
failover domain: 故障转移域,设定一个资源只能在哪些主机上面转移
priority: 设定,在一个转移域中,哪些主机优先被转移资源
pacemaker:
资源黏性:如果两个节点倾向性位置约束一致,资源对哪个节点粘性为正值,则留在哪个节点。
资源约束(3种类型):
位置约束:资源更倾向于哪个节点上;
inf: 无穷大
n: 倾向于运行在某节点
-n: 倾向于离开某节点
-inf: 负无穷
排列约束:资源运行在同一节点的倾向性;
inf: 两者永远在一起
-inf: 两者永远不再一起
顺序约束:资源启动次序及关闭次序;
例子:如何让web service中的三个资源:vip、httpd及filesystem运行于同一节点上?
1、排列约束;说明三个在一起可能性inf
2、资源组(resource group);三个资源定义在一个组内,然后这个组决定在某一个节点上启动
3、定义顺序约束,保证启动顺序,vip–filesystem–httpd
对称性与非对称性:
对称性: 默认所有节点都能转移资源。
非对称性; 有些节点不能转移资源。
如果节点不再成为集群节点成员时,如何处理运行于当前节点的资源:
stoped: 直接停止服务
ignore:忽略,以前运行什么服务现在还运行什么。
freeze: 事先建立的连接,接续保持,不再接收新的请求。
suicide: kill掉服务。
一个资源刚配置完成时,是否启动?
target-role: 目标角色,可以为启动,也可以为不启动。
资源代理类型(RA):
heartbeat legacy: 传统类型
LSB: /etc/rc.d/init.d/ 下面的服务脚本
OCF:
STONITH: 专门用来实现资源隔离的
资源类型:
primitive, native : 主资源,只能运行于一个节点。
group: 组资源
clone: 克隆资源,所有节点都运行的资源,首先是主资源。
通常为STONITH资源, Cluster filesystem, 分布式锁
1) 最多运行的最大数。 总clone数
2) 每一个节点上最多运行几个。
master/slave: 主从资源内容,只能克隆两份,主的能读能写,从的不能做任何操作
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





