小编给大家分享一下python中api的使用方法是什么,希望大家阅读完这篇文章后大所收获,下面让我们一起去探讨吧!
API:
Web应用编程接口(API)自动请求网站的特定信息而不是整个网页。因此即便数据瞬息万变,它呈现的信息也都是最新的。
一、使用Web API
Web API是网站的一部分,用于与使用非常具体的URL请求特定信息的程序交互。这种请求称为API调用。请求的数据将以易于处理的格式(如JSON或CSV)返回。依赖于外部数据源的大多数应用程序都依赖于API调用。
1、Git 和GitHub
我们将使用GitHub的API来请求有关该网站中Python项目的信息,GitHub(https://github.com/)的名字源自Git,Git是一个分布式版本控制系统,让程序员团队能够协作开发项目。
Git帮助大家管理为项目所做的工作,避免一个人所做的修改影响其他人所做的修改。
你在项目中实现新功能时,Git将跟踪你对每个文件所做的修改。确定代码可行后,你提交所做的修改,而Git将记录项目最新的状态。
(1)在Windows 系统中安装Git
要在Windows系统中安装Git,请访问http://msysgit.github.io/,并单击Download。
(2)配置Git
Git跟踪谁修改了项目,哪怕参与项目开发的人只有一个。为此,Git需要知道你的用户名和电子邮件地址。你必须提供用户名,但可以使用虚构的电子邮件地址:
$ git config --global user.name "username"
$ git config --global user.email "username@example.com"(3)创建项目
在你的系统中创建一个文件夹,并将其命名为git_practice。在这个文件夹中,创建一个简单的Python程序:
hello_world.py
print("Hello Git world!")我们将使用这个程序来探索Git的基本功能。
(4)忽略文件
扩展名为.pyc的文件是根据.py文件自动生成的,因此我们无需让Git跟踪它们。这些文件存储在目录__pycache__中。为让Git忽略这个目录,创建一个名为.gitignore的特殊文件(这个文件名以句点打头,且没有扩展名),并在其中添加下面一行内容:
.gitignore
__pycache__/这让Git忽略目录__pycache__中的所有文件。使用文件.gitignore可避免项目混乱,开发起来更容易。
(5)初始化仓库
你创建了一个目录,其中包含一个Python文件和一个.gitignore文件,可以初始化一个Git仓库了。为此,打开一个终端窗口,切换到文件夹git_practice,并执行如下命令:
git_practice$ git init
Initialized empty Git repository in git_practice/.git/
git_practice$输出表明Git在git_practice中初始化了一个空仓库。仓库是程序中被Git主动跟踪的一组文件。
Git用来管理仓库的文件都存储在隐藏的.git/中,你根本不需要与这个目录打交道,但千万不要删除这个目录,否则将丢弃项目的所有历史记录。
(6)检查状态
执行其他操作前,先来看一下项目的状态:
git_practice$ git status.在Git中,分支是项目的一个版本。从这里的输出可知,我们位于分支master上。你每次查看项目的状态时,输出都将指出你位于分支master上。
接下来的输出表明,我们将进行初始提交。提交是项目在特定时间点的快照。

# Untracked files:
Git指出了项目中未被跟踪的文件,因为我们还没有告诉它要跟踪哪些文件。
nothing added to commit but untracked files present (use "git add" to track)
我们被告知没有将任何东西添加到当前提交中,但我们可能需要将未跟踪的文件加入到仓库中
2、使用API 调用请求数据
GitHub的API让你能够通过API调用来请求各种信息。这个调用返回GitHub当前托管了多少个Python项目,还有有关最受欢迎的Python仓库的信息。
https://api.github.com/search/repositories?q=language:python&sort=stars
第一部分(https://api.github.com/)将请求发送到GitHub网站中响应API调用的部分
第二部分(search/repositories)让API搜索GitHub上的所有仓库。
第三部分(repositories后面的?)指出我们要传递的实参
第四部分(q=)q表示查询,= 符号让我们能够开始指定查询(q=)
第五部分(language:python)指出只想获取主要语言为python的仓库的信息
第六部分(&sort=stars) 指定将项目按其获得的星级进行排序。
3、安装requests
requests包让Python程序能够轻松地向网站请求信,息以及检查返回的响应
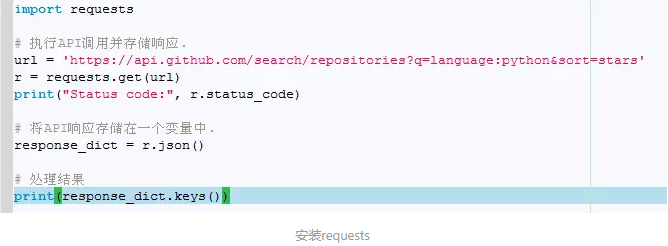
1. 导入了模块requests
2. 存储API调用的URL
3. 使用requests来执行调用,调用get()并将URL传递给它,再将响应对象存储在变量r中,响应对象包含一个名为status_code的属性,它让我们知道请求是否成功了。
4. 打印status_code,核实调用是否成功了。
5. API返回JSON格式的信息,因此我们使用方法json()将这些信息转换为一个Python字典。我们将转换得到的字典存储在response_dict中。
最后,打印response_dict中的键。
4、处理响应字典
将API调用返回的信息存储到字典中后,就可以处理这个字典中的数据了。
生成一些概述这些信息的输出,可确认收到了期望的信息,进而可以开始研究感兴趣的信息。
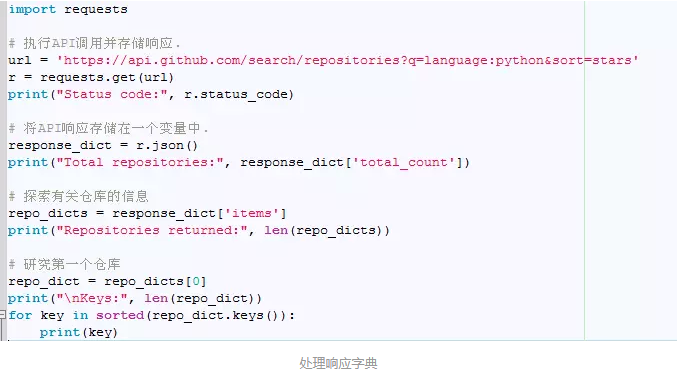
print("Total repositories:", response_dict['total_count'])打印了与'total_count'相关联的值,它指出了GitHub总共包含多少个Python仓库。
与'items'相关联的值是一个列表,其中包含很多字典,而每个字典都包含有关一个Python仓库的信息。
repo_dicts = response_dict['items']
print("Repositories returned:", len(repo_dicts))我们将这个字典列表存储在repo_dicts中。接下来,我们打印repo_dicts的长度,以获悉我们获得了多少个仓库的信息。
repo_dict = repo_dicts[0]为更深入地了解返回的有关每个仓库的信息,我们提取了repo_dicts中的第一个字典,并将其存储在repo_dict中。
print("\nKeys:", len(repo_dict))我们打印这个字典包含的键数,看看其中有多少信息。
for key in sorted(repo_dict.keys()):
print(key)我们打印这个字典的所有键,看看其中包含哪些信息。
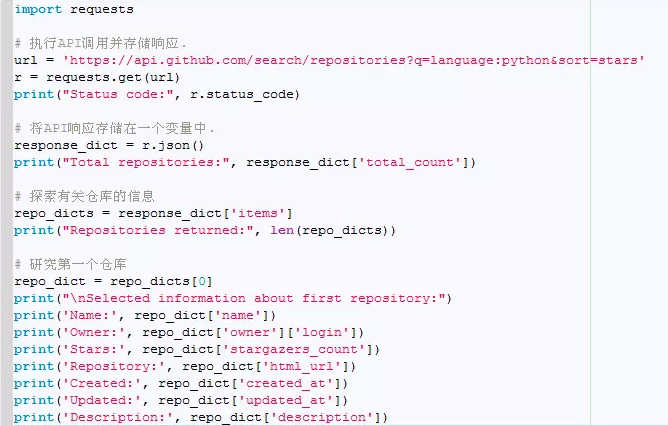
5、概述最受欢迎的仓库
对这些数据进行可视化时,我们需要涵盖多个仓库。打印API调用返回的每个仓库的特定信息,以便能够在可视化中包含所有这些信息。

6、监视API 的速率限制
大多数API都存在速率限制,即你在特定时间内可执行的请求数存在限制。要获悉你是否接近了GitHub的限制,请在浏览器中输入https://api.github.com/rate_limit
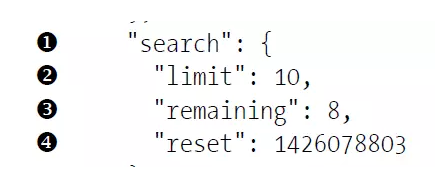
"search": {
搜索API的速率限制
"limit": 10,
极限为每分钟10个请求
"remaining": 8,
在当前这一分钟内,我们还可执行8个请求。
"reset": 1426078803
reset值指的是配额将重置的Unix时间或新纪元时间(1970年1月1日午夜后多少秒)
用完配额后,你将收到一条简单的响应,由此知道已到达API极限。到达极限后,你必须等待配额重置。
注意:很多API都要求你注册获得API密钥后才能执行API调用。编写本书时,GitHub没有这样的要求,但获得API密钥后,配额将高得多。
看完了这篇文章,相信你对python中api的使用方法是什么有了一定的了解,想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



