这篇文章主要介绍了flask模型类数据序列化的方法,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获。下面让小编带着大家一起了解一下。
我们在做后台接口的时候,对于返回值,用的最多的就是json数据格式
flask中,返回json数据格式,我们可以用到flask的jsonify函数。
对于基础序列是可以直接序列化的,但是更多的情况下,我们要返回给前端的是一个从数据库查询的模型对象。那么要如何序列化一个模型对象呢?
追踪flask源码,我们会发现,在处理特殊类型的数据的时候,flask用到了json包下的一个JSONEncoder类,它里面有一个很重要的函数,default(),这里面对datetime,date,uuid,html等都做了特殊处理,但是没有对模型对象做处理。
所以思路就出来了,我们需要重写JSONEncoder的default函数,想办法将模型对象转化为dict类型,这样jsonify就可以直接处理了。
那么如何处理模型对象?
最开始想到的是,是用模型对象的__dict__属性,但是这个属性中只有实例属性,没有类属性,所以显然用这个不可取的。
又想到我们平时要定义一个字典类型,是怎么处理的?
可以使用d = dict() 函数来创建一个字典类型的变量。
那如果我们将模型对象实例作为参数传递给dict() 是否可行呢?
答案是可行的,但是我们需要在模型对象中定义两个方法,keys()方法和__getitem__()方法
keys()方法返回值为一个序列,用于告诉dict,当前dict()的key值
__getitem__() 方法,用于将key值和value值对应起来返回给dict()

所以,flask中,如何序列化模型对象呢?答案就呼之欲出了。直接上代码
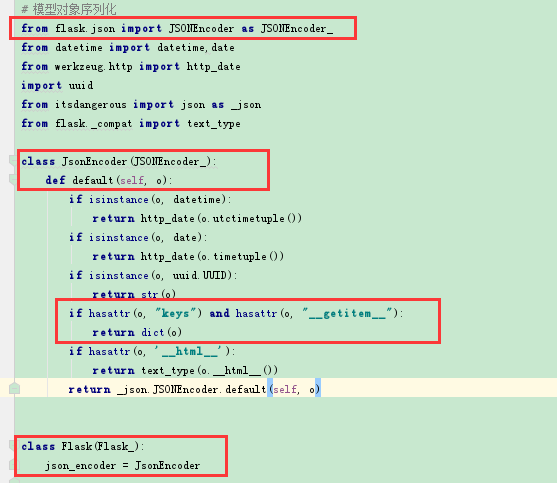
如上图,定义类JsonEncode,继承自flask.json下面的JSONEncoder,然后重写里面的default函数,其他的不变,唯一就是增加模型对象的序列化,
判断如果当前对象中存在keys和__getitem__属性(即我们上面自定义的两个方法),则表示是模型对象,把它作为参数传给dict(),
然后将我们顶一个JsonEncoder函数替换掉flask.json下面的JSONEncoder类。
最后在需要序列化的模型下面定义keys()和__getitem__()方法。
感谢你能够认真阅读完这篇文章,希望小编分享flask模型类数据序列化的方法内容对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,遇到问题就找亿速云,详细的解决方法等着你来学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



