今天就跟大家聊聊有关Scrapy爬虫容易忽视的点,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
scrapy爬虫注意事项
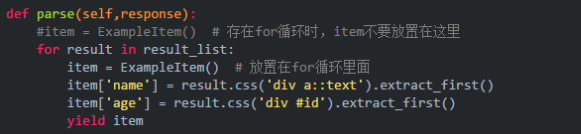
一、item数据只有最后一条
这种情况一般存在于对标签进行遍历时,将item对象放置在了for循环的外部。解决方式:将item放置在for循环里面。
二、item字段传递后错误,混乱
有时候会遇到这样的情况,item传递几次之后,发现不同页面的数据被混乱的组合在了一起。这种情况一般存在于item的传递过程中,没有使用深拷贝。解决方式:使用深拷贝来传递item。
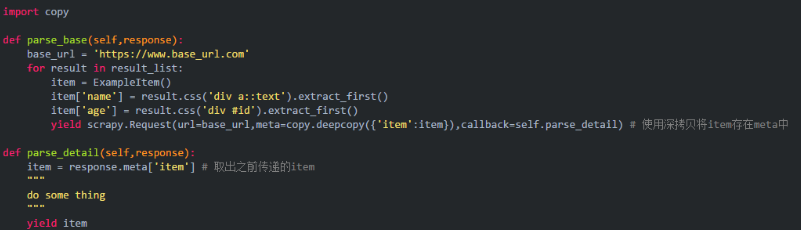
三、对一个页面要进行两种或多种不同的解析
这种情况一般出现在对同一页面有不同的解析要求时,但默认情况下只能得到第一个parse的结果。产生这个结果的原因是scrapy默认对拥有相同的url,相同的body以及相同的请求方法视为一个请求。解决方式:设置参数dont_filter='True'。

四、xpath中contains的使用
这种情况一般出现在标签没有特定属性值但是文本中包含特定汉字的情况,当然也可以用来包含特定的属性值来使用(只不过有特定属性值的时候我也不会用contains了)。
作者:村上春树
书名:挪威的森林
以上面这两个标签为例(自行F12查看),两个span标签没有特定的属性值,但里面一个包含作者,一个包含书名,就可以考虑使用contains来进行提取。

五、提取不在标签中的文本
有时候会遇到这样的情况,文本在两个标签之间,但不属于这两个标签的任何一个。此时可以考虑使用xpath的contains和following共同协助完成任务。
示例:
作者:
"村上春树"
书名
"挪威的森林"

六、使用css、xpath提取倒数第n个标签
对于很多页面,标签的数量有时候无法保证是一致的。如果用正向的下标进行提取,很可能出现数组越界的情况。这种时候可以考虑反向提取,必要时加一些判断。

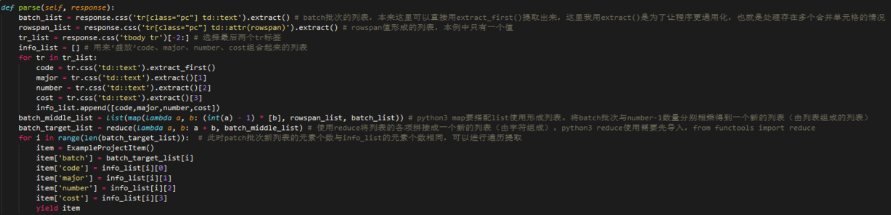
七、提取表格信息
其实对于信息抓取,很多时候我们需要对表格页面进行抓取。一般的方方正正的表格提取相对简单,这里不讨论。只说下含有合并单元格的情况。
以这个网页的表格为例,定义5个字段批次,招生代码,专业,招生数量以及费用,注意到合并单元格的标签里有个rowspan属性,可以用来辨识出有几行被合并。我的思路是有多少行数据,就将batch批次扩展到多少个,形成一个新的列表,然后进行遍历提取数据。
八、模拟登陆
当页面数据需要登陆进行抓取时,就需要模拟登陆了。常见的方式有:使用登陆后的cookie来抓取数据;发送表单数据进行登陆;使用自动化测试工具登陆,比如selenium配合chrome、firefox等,不过听说selenium不再更新,也可以使用chrome的无头模式。鉴于自动化测试的抓取效率比较低,而且我确实很久没使用过这个了。本次只讨论使用cookie和发送表单两种方式来模拟登陆。
使用cookie
使用cookie的方式比较简单,基本思路就是登陆后用抓包工具或者类似chrome的F12调试界面查看cookie值,发送请求时带上cookie值即可。
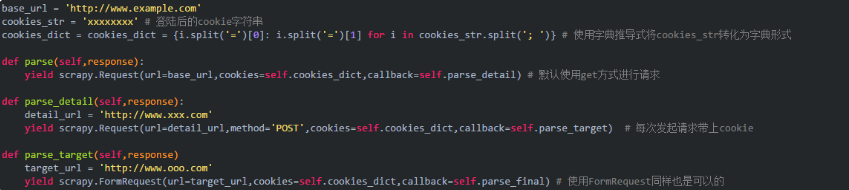
发送表单方式进行登陆
cookie是有有效期的,对于大量数据的抓取,更好的方式是发送表单进行模拟登陆。scrapy有专门的函数scrapy.FormRequest()用来处理表单提交。网上有些人说cookie没法保持,可以考虑用我下面的方式。

看完上述内容,你们对Scrapy爬虫容易忽视的点有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





