这篇文章主要介绍了Python之常用反爬虫措施和解决办法有哪些,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获。下面让小编带着大家一起了解一下。
一、全网代理IP的JS混淆
首先进入全网代理IP,打开开发者工具,点击查看端口号,看起来貌似没有什么问题:
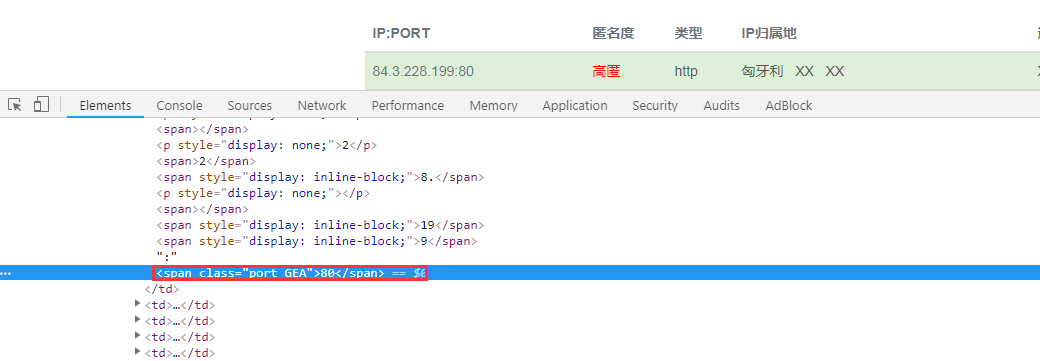
如果你已经爬取过这个网站的代理,你就会知道事情并非这么简单。如果没爬过呢?也很简单,点击鼠标右键然后查看网页源代码,搜索”port“,可以找到如下内容:

很明显这不是网页上显示的端口号了,那我们要怎么才能得到真正的端口号呢?
解决办法:
首先需要找到一个JS文件:http://www.goubanjia.com/theme/goubanjia/javascript/pde.js?v=1.0,点开后可以看到如下内容:

这么复杂的JS代码看得人头都大了,不过我们发现这个JS代码是一个eval函数,那我们能不能把它解码一下呢?这时候你需要一个工具--脚本之家在线工具,把这些JS代码复制进去:
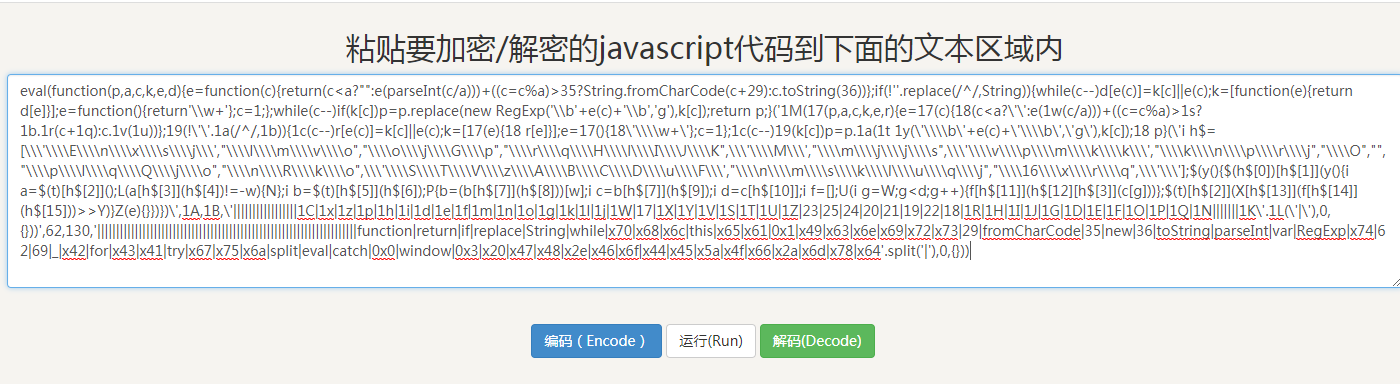
然后点击解码:
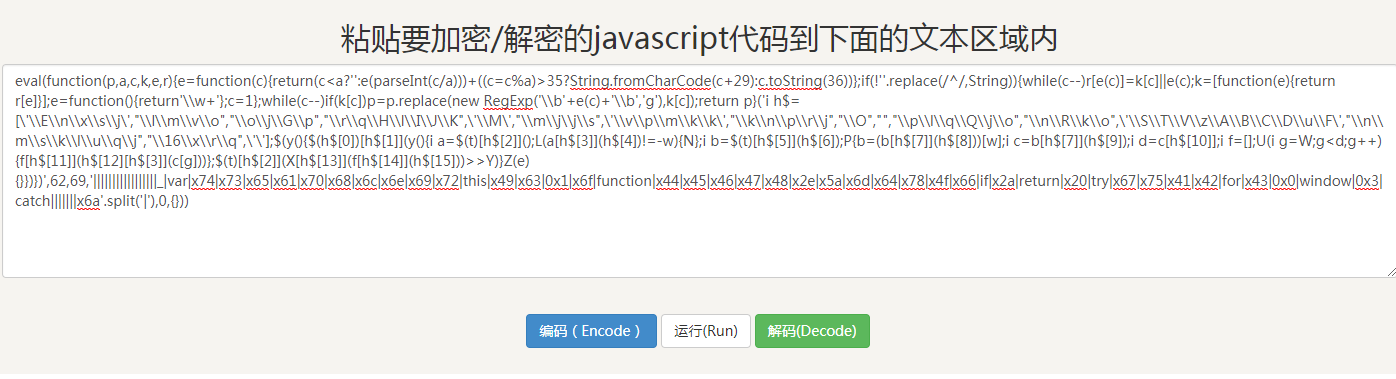
还是一个eval函数,所以再次解码:
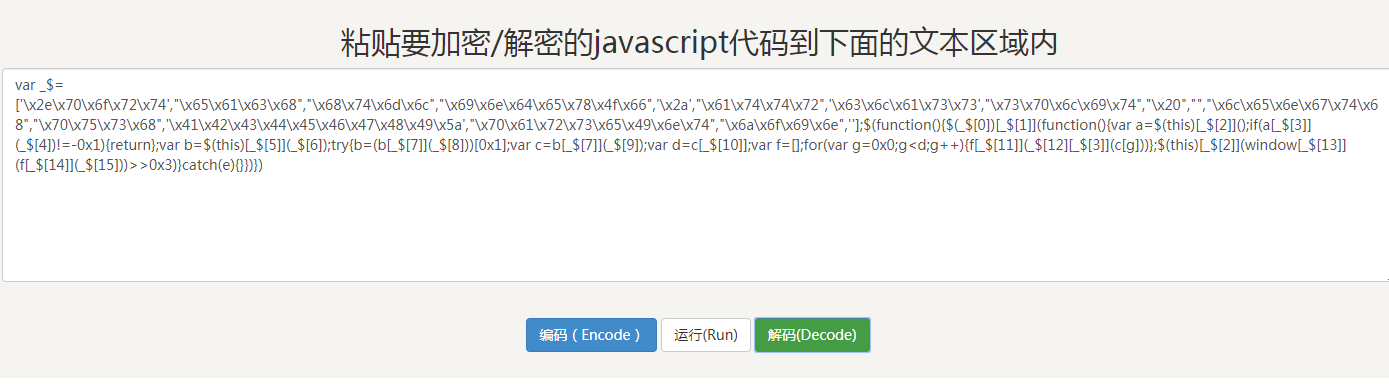
到这一步,已经比最开始的代码简洁多了,但是还易读性还是很差,所以我们需要先格式化一下:
var _$ = [
"\x2e\x70\x6f\x72\x74",
"\x65\x61\x63\x68",
"\x68\x74\x6d\x6c",
"\x69\x6e\x64\x65\x78\x4f\x66",
"\x2a",
"\x61\x74\x74\x72",
"\x63\x6c\x61\x73\x73",
"\x73\x70\x6c\x69\x74",
"\x20",
"",
"\x6c\x65\x6e\x67\x74\x68",
"\x70\x75\x73\x68",
"\x41\x42\x43\x44\x45\x46\x47\x48\x49\x5a",
"\x70\x61\x72\x73\x65\x49\x6e\x74",
"\x6a\x6f\x69\x6e",
""
];
$(function() {
$(_$[0])[_$[1]](function() {
var a = $(this)[_$[2]]();
if (a[_$[3]](_$[4]) != -0x1) {
return;
}
var b = $(this)[_$[5]](_$[6]);
try {
b = b[_$[7]](_$[8])[0x1];
var c = b[_$[7]](_$[9]);
var d = c[_$[10]];
var f = [];
for (var g = 0x0; g < d; g++) {
f[_$[11]](_$[12][_$[3]](c[g]));
}
$(this)[_$[2]](window[_$[13]](f[_$[14]](_$[15])) >> 0x3);
} catch (e) {}
});
});可以看到有一个列表和一个函数,而这个函数应该就是混淆的函数了,但是这列表里的数据都是十六进制的,还需要解码一下(这一步可以用Python来做):
_ = ["\x2e\x70\x6f\x72\x74", "\x65\x61\x63\x68", "\x68\x74\x6d\x6c", "\x69\x6e\x64\x65\x78\x4f\x66", "\x2a",
"\x61\x74\x74\x72", "\x63\x6c\x61\x73\x73", "\x73\x70\x6c\x69\x74", "\x20", "", "\x6c\x65\x6e\x67\x74\x68",
"\x70\x75\x73\x68", "\x41\x42\x43\x44\x45\x46\x47\x48\x49\x5a", "\x70\x61\x72\x73\x65\x49\x6e\x74",
"\x6a\x6f\x69\x6e", ""
]
_ = [i.encode('utf-8').decode('utf-8') for i in _]
print(_)
# ['.port', 'each', 'html', 'indexOf', '*', 'attr', 'class', 'split', ' ', '', 'length', 'push', 'ABCDEFGHIZ',
'parseInt', 'join', '']然后把这个列表里的元素添加到上面的JS函数中,可以得到如下结果:
$(function() {
$(".port")["each"](function() {
var a = $(this)["html"]();
if (a["indexOf"]("*") != -0x1) {
return;
}
var b = $(this)["attr"]("class");
try {
b = b["split"](" ")[0x1];
var c = b["split"]("");
var d = c["length"];
var f = [];
for (var g = 0x0; g < d; g++) {
f["push"]("ABCDEFGHIZ"["indexOf"](c[g]));
}
$(this)["html"](window["parseInt"](f["join"]("")) >> 0x3);
} catch (e) {}
});
});可以看到这段JS代码就是先找到每个端口节点,然后把端口的class值提取出来,再进行拆分字符串,然后获取每个字母在”ABCDEFGHIZ“中的下标值,并把这些值拼接成字符串,再转为整型数据,最后把这个整型数据向右移3位。比如”GEA“对应的下标组成的字符串是”640“,转为整型数据后向右移3位的结果就是80,也就是真实的端口值了。最后附上用Python解密端口号的代码:
et = etree.HTML(html)
port_list = et.xpath('//*[contains(@class,"port")]/@class')
for port in port_list:
port = port.split(' ')[1]
num = ""
for i in port:
num += str("ABCDEFGHIZ".index(i))
print(int(num) >> 3)二、用图片代替文字
之前就有人评论说有的网站使用图片代替文字以实现反爬虫,然后我这次就找到了一个网站--新蛋网,随意点击一个商品查看一下:
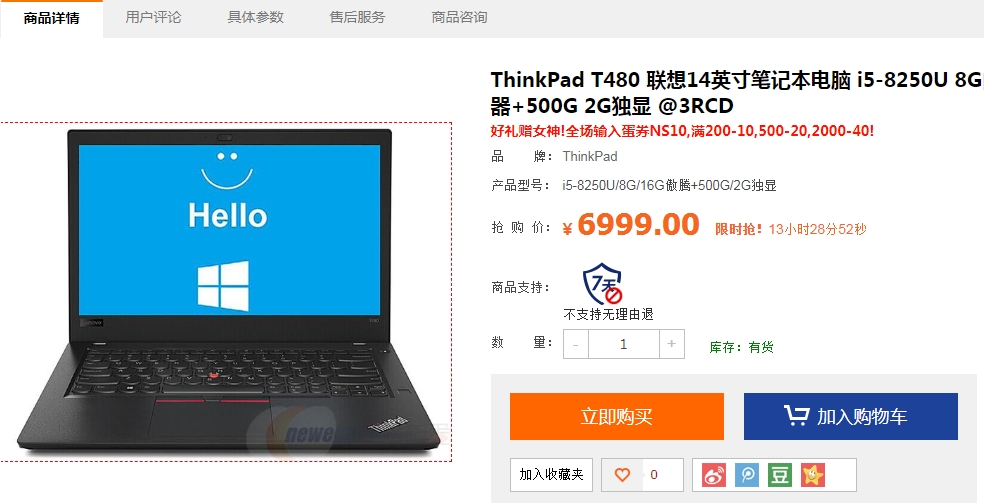
打开开发者工具,然后点击查看价格,想不到价格居然是通过图片来显示的:
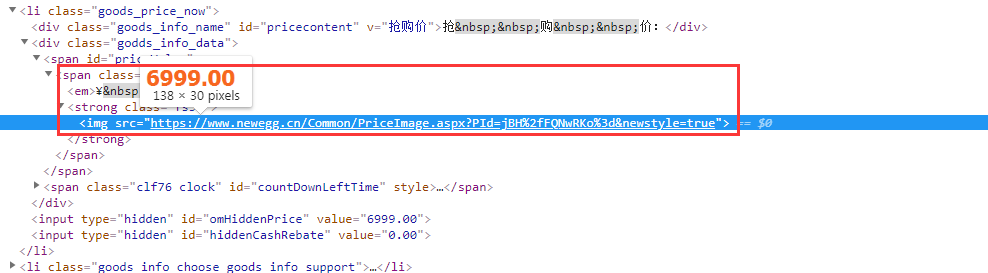
解决办法:
我找到两个可以得到价格的办法,一个简单的,一个难一点的。简单的方法是用正则表达式,因为在源码中的其他地方是包含商品的基本信息的,比如名称和价格,所以我们可以使用正则表达式进行匹配,代码如下:
import re
import requests
url = "https://www.newegg.cn/Product/A36-125-E5L.htm?neg_sp=Home-_-A36-125-E5L-_-CountdownV1"
res = requests.get(url)
result = re.findall("name:'(.+?)', price:'(.+?)'", res.text)
print(result)难一点的方法是把图片下载到本地之后进行识别,由于这个图片的清晰度很高,也没有扭曲或者加入干扰线什么的,所以可以直接使用OCR进行识别。但是用这种方法的话需要安装好Tesseract-OCR,这个工具的安装过程还是比较麻烦的。用这种方法破解的代码如下:
import requests
import pytesseract
from PIL import Image
from lxml import etree
url = "https://www.newegg.cn/Product/A36-125-E5L.htm?neg_sp=Home-_-A36-125-E5L-_-CountdownV1"
res = requests.get(url)
et = etree.HTML(res.text)
img_url = et.xpath('//*[@id="priceValue"]/span/strong/img/@src')[0]
with open('price.png','wb') as f:
f.write(requests.get(img_url).content)
pytesseract.pytesseract.tesseract_cmd = 'E:/Python/Tesseract-OCR/tesseract.exe'
text = pytesseract.image_to_string(Image.open('price.png'))
print(text)
# 6999.00感谢你能够认真阅读完这篇文章,希望小编分享Python之常用反爬虫措施和解决办法有哪些内容对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,遇到问题就找亿速云,详细的解决方法等着你来学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



