什么是Python中的哈希表?相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
散列表(哈希表)
散列表:所有的元素之间没有任何关系。元素的存储位置,是利用元素的关键字通过某个函数直接计算出来的。这个一一对应的关系函数称为散列函数或Hash函数。
采用散列技术将记录存储在一块连续的存储空间中,称为散列表或哈希表(Hash Table)。关键字对应的存储位置,称为散列地址。
散列表是一种面向查找的存储结构。它最适合求解的问题是查找与给定值相等的记录。但是对于某个关键字能对应很多记录的情况就不适用,比如查找所有的“男”性。也不适合范围查找,比如查找年龄20~30之间的人。排序、最大、最小等也不合适。
因此,散列表通常用于关键字不重复的数据结构。比如python的字典数据类型。
设计出一个简单、均匀、存储利用率高的散列函数是散列技术中最关键的问题。
但是,一般散列函数都面临着冲突的问题。
冲突:两个不同的关键字,通过散列函数计算后结果却相同的现象。collision。
散列函数的构造方法
好的散列函数:计算简单、散列地址分布均匀
直接定址法
例如取关键字的某个线性函数为散列函数:
f(key) = a*key + b (a,b为常数)数字分析法
抽取关键字里的数字,根据数字的特点进行地址分配平方取中法
将关键字的数字求平方,再截取部分折叠法
将关键字的数字分割后分别计算,再合并计算,一种玩弄数字的手段。除留余数法
最为常见的方法之一。
对于表长为m的数据集合,散列公式为:
f(key) = key mod p (p<=m)
mod:取模(求余数)
该方法最关键的是p的选择,而且数据量较大的时候,冲突是必然的。一般会选择接近m的质数。随机数法
选择一个随机数,取关键字的随机函数值为它的散列地址。
f(key) = random(key)
总结,实际情况下根据不同的数据特性采用不同的散列方法,考虑下面一些主要问题:
计算散列地址所需的时间关键字的长度散列表的大小关键字的分布情况记录查找的频率
处理散列冲突
开放定址法
就是一旦发生冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
公式是:

这种简单的冲突解决办法被称为线性探测,无非就是自家的坑被占了,就逐个拜访后面的坑,有空的就进,也不管这个坑是不是后面有人预定了的。
线性探测带来的最大问题就是冲突的堆积,你把别人预定的坑占了,别人也就要像你一样去找坑。
改进的办法有二次方探测法和随机数探测法。
再散列函数法
发生冲突时就换一个散列函数计算,总会有一个可以把冲突解决掉,它能够使得关键字不产生聚集,但相应地增加了计算的时间。
链接地址法
碰到冲突时,不更换地址,而是将所有关键字为同义词的记录存储在一个链表里,在散列表中只存储同义词子表的头指针,如下图:
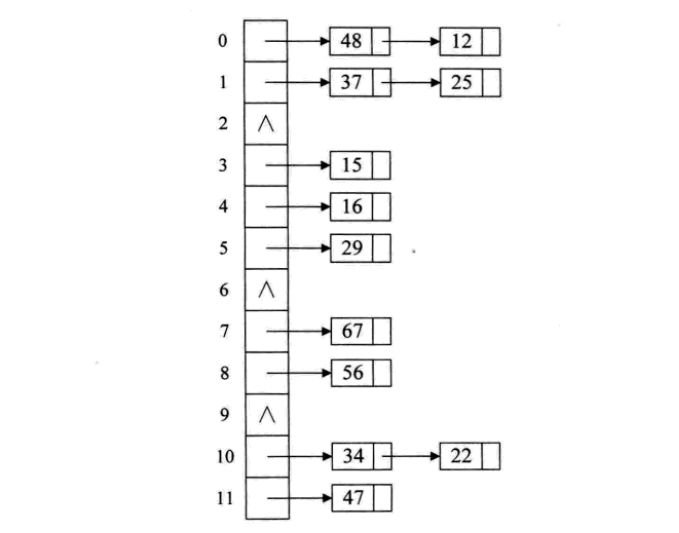
这样的好处是,不怕冲突多;缺点是降低了散列结构的随机存储性能。本质是用单链表结构辅助散列结构的不足。
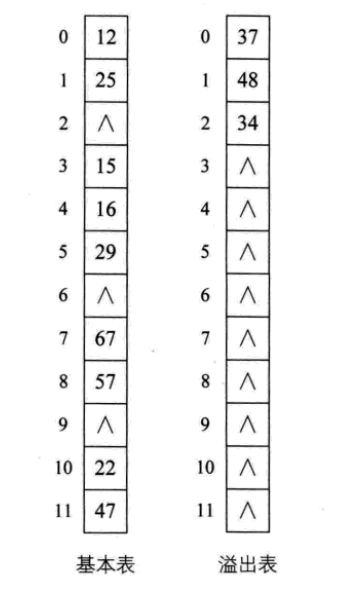
公共溢出区法
其实就是为所有的冲突,额外开辟一块存储空间。如果相对基本表而言,冲突的数据很少的时候,使用这种方法比较合适。
散列表查找实现
下面是一段简单的实现代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: Liu Jiang
# Python 3.5
# 忽略了对数据类型,元素溢出等问题的判断。
class HashTable:
def __init__(self, size):
self.elem = [None for i in range(size)] # 使用list数据结构作为哈希表元素保存方法
self.count = size # 最大表长
def hash(self, key):
return key % self.count # 散列函数采用除留余数法
def insert_hash(self, key):
"""插入关键字到哈希表内"""
address = self.hash(key) # 求散列地址
while self.elem[address]: # 当前位置已经有数据了,发生冲突。
address = (address+1) % self.count # 线性探测下一地址是否可用
self.elem[address] = key # 没有冲突则直接保存。
def search_hash(self, key):
"""查找关键字,返回布尔值"""
star = address = self.hash(key)
while self.elem[address] != key:
address = (address + 1) % self.count
if not self.elem[address] or address == star: # 说明没找到或者循环到了开始的位置
return False
return True
if __name__ == '__main__':
list_a = [12, 67, 56, 16, 25, 37, 22, 29, 15, 47, 48, 34]
hash_table = HashTable(12)
for i in list_a:
hash_table.insert_hash(i)
for i in hash_table.elem:
if i:
print((i, hash_table.elem.index(i)), end=" ")
print("\n")
print(hash_table.search_hash(15))
print(hash_table.search_hash(33))散列表查找性能分析
如果没发生冲突,则其查找时间复杂度为O(1),属于最极端的好了。
但是,现实中冲突可不可避免的,下面三个方面对查找性能影响较大:
散列函数是否均匀处理冲突的办法散列表的装填因子(表内数据装满的程度)
看完上述内容,你们掌握什么是Python中的哈希表的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





