不懂如何实现keras训练浅层卷积网络并保存和加载模型?其实想解决这个问题也不难,下面让小编带着大家一起学习怎么去解决,希望大家阅读完这篇文章后大所收获。
这里我们使用keras定义简单的神经网络全连接层训练MNIST数据集和cifar10数据集:
keras_mnist.py
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from keras.models import Sequential
from keras.layers.core import Dense
from keras.optimizers import SGD
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
import argparse
# 命令行参数运行
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True, help="path to the output loss/accuracy plot")
args =vars(ap.parse_args())
# 加载数据MNIST,然后归一化到【0,1】,同时使用75%做训练,25%做测试
print("[INFO] loading MNIST (full) dataset")
dataset = datasets.fetch_mldata("MNIST Original", data_home="/home/king/test/python/train/pyimagesearch/nn/data/")
data = dataset.data.astype("float") / 255.0
(trainX, testX, trainY, testY) = train_test_split(data, dataset.target, test_size=0.25)
# 将label进行one-hot编码
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# keras定义网络结构784--256--128--10
model = Sequential()
model.add(Dense(256, input_shape=(784,), activation="relu"))
model.add(Dense(128, activation="relu"))
model.add(Dense(10, activation="softmax"))
# 开始训练
print("[INFO] training network...")
# 0.01的学习率
sgd = SGD(0.01)
# 交叉验证
model.compile(loss="categorical_crossentropy", optimizer=sgd, metrics=['accuracy'])
H = model.fit(trainX, trainY, validation_data=(testX, testY), epochs=100, batch_size=128)
# 测试模型和评估
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=128)
print(classification_report(testY.argmax(axis=1), predictions.argmax(axis=1),
target_names=[str(x) for x in lb.classes_]))
# 保存可视化训练结果
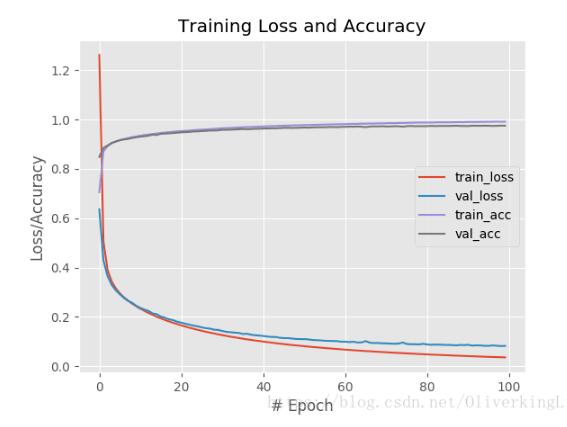
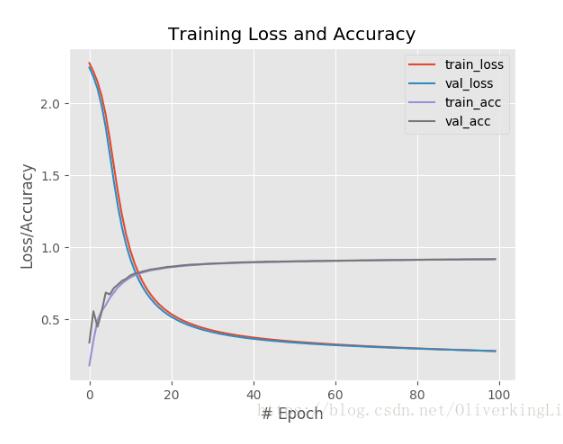
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 100), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 100), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 100), H.history["acc"], label="train_acc")
plt.plot(np.arange(0, 100), H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("# Epoch")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["output"])使用relu做激活函数:
使用sigmoid做激活函数:
接着我们自己定义一些modules去实现一个简单的卷基层去训练cifar10数据集:
imagetoarraypreprocessor.py
''' 该函数主要是实现keras的一个细节转换,因为训练的图像时RGB三颜色通道,读取进来的数据是有depth的,keras为了兼容一些后台,默认是按照(height, width, depth)读取,但有时候就要改变成(depth, height, width) ''' from keras.preprocessing.image import img_to_array class ImageToArrayPreprocessor: def __init__(self, dataFormat=None): self.dataFormat = dataFormat def preprocess(self, image): return img_to_array(image, data_format=self.dataFormat)
shallownet.py
'''
定义一个简单的卷基层:
input->conv->Relu->FC
'''
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.core import Activation, Flatten, Dense
from keras import backend as K
class ShallowNet:
@staticmethod
def build(width, height, depth, classes):
model = Sequential()
inputShape = (height, width, depth)
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
model.add(Conv2D(32, (3, 3), padding="same", input_shape=inputShape))
model.add(Activation("relu"))
model.add(Flatten())
model.add(Dense(classes))
model.add(Activation("softmax"))
return model然后就是训练代码:
keras_cifar10.py
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from shallownet import ShallowNet
from keras.optimizers import SGD
from keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
import argparse
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True, help="path to the output loss/accuracy plot")
args = vars(ap.parse_args())
print("[INFO] loading CIFAR-10 dataset")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# 标签0-9代表的类别string
labelNames = ['airplane', 'automobile', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
print("[INFO] compiling model...")
opt = SGD(lr=0.0001)
model = ShallowNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY), batch_size=32, epochs=1000, verbose=1)
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1), predictions.argmax(axis=1),
target_names=labelNames))
# 保存可视化训练结果
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 1000), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 1000), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 1000), H.history["acc"], label="train_acc")
plt.plot(np.arange(0, 1000), H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("# Epoch")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["output"]) 代码中可以对训练的learning rate进行微调,大概可以接近60%的准确率。
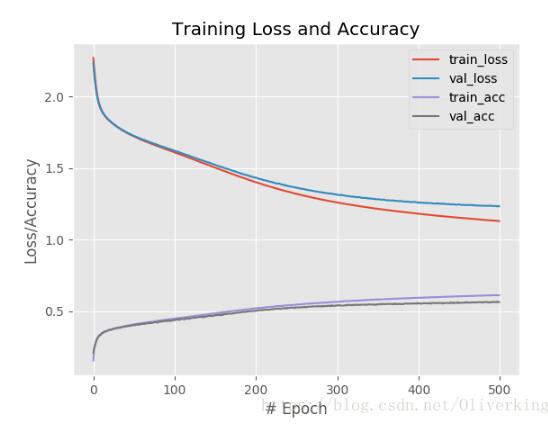
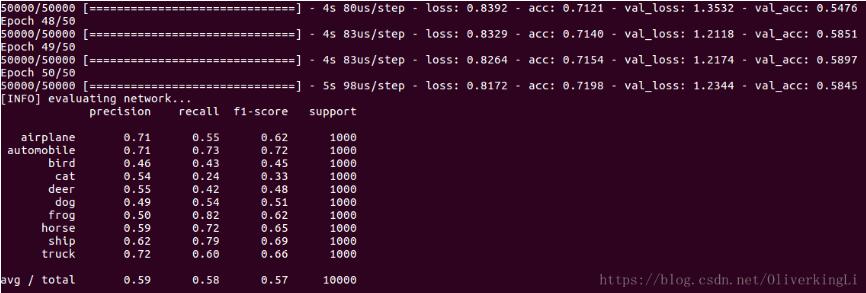
然后修改下代码可以保存训练模型:
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from shallownet import ShallowNet
from keras.optimizers import SGD
from keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
import argparse
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True, help="path to the output loss/accuracy plot")
ap.add_argument("-m", "--model", required=True, help="path to save train model")
args = vars(ap.parse_args())
print("[INFO] loading CIFAR-10 dataset")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# 标签0-9代表的类别string
labelNames = ['airplane', 'automobile', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
print("[INFO] compiling model...")
opt = SGD(lr=0.005)
model = ShallowNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY), batch_size=32, epochs=50, verbose=1)
model.save(args["model"])
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1), predictions.argmax(axis=1),
target_names=labelNames))
# 保存可视化训练结果
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 5), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 5), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 5), H.history["acc"], label="train_acc")
plt.plot(np.arange(0, 5), H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("# Epoch")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["output"]) 命令行运行:

我们使用另一个程序来加载上一次训练保存的模型,然后进行测试:
test.py
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from shallownet import ShallowNet
from keras.optimizers import SGD
from keras.datasets import cifar10
from keras.models import load_model
import matplotlib.pyplot as plt
import numpy as np
import argparse
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True, help="path to save train model")
args = vars(ap.parse_args())
# 标签0-9代表的类别string
labelNames = ['airplane', 'automobile', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
print("[INFO] loading CIFAR-10 dataset")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
idxs = np.random.randint(0, len(testX), size=(10,))
testX = testX[idxs]
testY = testY[idxs]
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
print("[INFO] loading pre-trained network...")
model = load_model(args["model"])
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32).argmax(axis=1)
print("predictions\n", predictions)
for i in range(len(testY)):
print("label:{}".format(labelNames[predictions[i]]))
trueLabel = []
for i in range(len(testY)):
for j in range(len(testY[i])):
if testY[i][j] != 0:
trueLabel.append(j)
print(trueLabel)
print("ground truth testY:")
for i in range(len(trueLabel)):
print("label:{}".format(labelNames[trueLabel[i]]))
print("TestY\n", testY)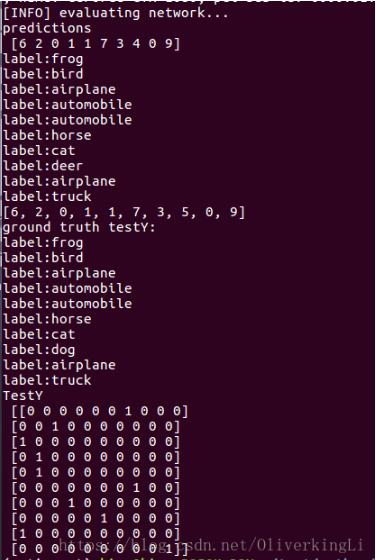
感谢你能够认真阅读完这篇文章,希望小编分享如何实现keras训练浅层卷积网络并保存和加载模型内容对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,遇到问题就找亿速云,详细的解决方法等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





