这篇文章主要介绍pytorch如何加载自己的图像数据集,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
之前学习深度学习算法,都是使用网上现成的数据集,而且都有相应的代码。到了自己开始写论文做实验,用到自己的图像数据集的时候,才发现无从下手 ,相信很多新手都会遇到这样的问题。
下面代码实现了从文件夹内读取所有图片,进行归一化和标准化操作并将图片转化为tensor。最后读取第一张图片并显示。
# 数据处理
import os
import torch
from torch.utils import data
from PIL import Image
import numpy as np
from torchvision import transforms
transform = transforms.Compose([
transforms.ToTensor(), # 将图片转换为Tensor,归一化至[0,1]
# transforms.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5]) # 标准化至[-1,1]
])
#定义自己的数据集合
class FlameSet(data.Dataset):
def __init__(self,root):
# 所有图片的绝对路径
imgs=os.listdir(root)
self.imgs=[os.path.join(root,k) for k in imgs]
self.transforms=transform
def __getitem__(self, index):
img_path = self.imgs[index]
pil_img = Image.open(img_path)
if self.transforms:
data = self.transforms(pil_img)
else:
pil_img = np.asarray(pil_img)
data = torch.from_numpy(pil_img)
return data
def __len__(self):
return len(self.imgs)
if __name__ == '__main__':
dataSet=FlameSet('./test')
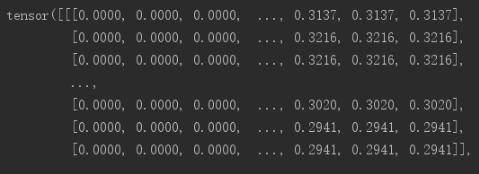
print(dataSet[0])显示结果:
补充知识:使用Pytorch进行读取本地的MINIST数据集并进行装载
pytorch中的torchvision.datasets中自带MINIST数据集,可直接调用模块进行获取,也可以进行自定义自己的Dataset类进行读取本地数据和初始化数据。
1. 直接使用pytorch自带的MNIST进行下载:
缺点: 下载速度较慢,而且如果中途下载失败一般得是重新进行执行代码进行下载:
# # 训练数据和测试数据的下载 # 训练数据和测试数据的下载 trainDataset = torchvision.datasets.MNIST( # torchvision可以实现数据集的训练集和测试集的下载 root="./data", # 下载数据,并且存放在data文件夹中 train=True, # train用于指定在数据集下载完成后需要载入哪部分数据,如果设置为True,则说明载入的是该数据集的训练集部分;如果设置为False,则说明载入的是该数据集的测试集部分。 transform=transforms.ToTensor(), # 数据的标准化等操作都在transforms中,此处是转换 download=True # 瞎子啊过程中如果中断,或者下载完成之后再次运行,则会出现报错 ) testDataset = torchvision.datasets.MNIST( root="./data", train=False, transform=transforms.ToTensor(), download=True )
2. 自定义dataset类进行数据的读取以及初始化。
其中自己下载的MINIST数据集的内容如下:
自己定义的dataset类需要继承: Dataset
需要实现必要的魔法方法:
__init__魔法方法里面进行读取数据文件
__getitem__魔法方法进行支持下标访问
__len__魔法方法返回自定义数据集的大小,方便后期遍历
示例如下:
class DealDataset(Dataset):
"""
读取数据、初始化数据
"""
def __init__(self, folder, data_name, label_name,transform=None):
(train_set, train_labels) = load_minist_data.load_data(folder, data_name, label_name) # 其实也可以直接使用torch.load(),读取之后的结果为torch.Tensor形式
self.train_set = train_set
self.train_labels = train_labels
self.transform = transform
def __getitem__(self, index):
img, target = self.train_set[index], int(self.train_labels[index])
if self.transform is not None:
img = self.transform(img)
return img, target
def __len__(self):
return len(self.train_set)其中load_minist_data.load_data也是我们自己写的读取数据文件的函数,即放在了load_minist_data.py中的load_data函数中。具体实现如下:
def load_data(data_folder, data_name, label_name):
"""
data_folder: 文件目录
data_name: 数据文件名
label_name:标签数据文件名
"""
with gzip.open(os.path.join(data_folder,label_name), 'rb') as lbpath: # rb表示的是读取二进制数据
y_train = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(os.path.join(data_folder,data_name), 'rb') as imgpath:
x_train = np.frombuffer(
imgpath.read(), np.uint8, offset=16).reshape(len(y_train), 28, 28)
return (x_train, y_train)编写完自定义的dataset就可以进行实例化该类并装载数据:
# 实例化这个类,然后我们就得到了Dataset类型的数据,记下来就将这个类传给DataLoader,就可以了。
trainDataset = DealDataset('MNIST_data/', "train-images-idx3-ubyte.gz","train-labels-idx1-ubyte.gz",transform=transforms.ToTensor())
testDataset = DealDataset('MNIST_data/', "t10k-images-idx3-ubyte.gz","t10k-labels-idx1-ubyte.gz",transform=transforms.ToTensor())
# 训练数据和测试数据的装载
train_loader = dataloader.DataLoader(
dataset=trainDataset,
batch_size=100, # 一个批次可以认为是一个包,每个包中含有100张图片
shuffle=False,
)
test_loader = dataloader.DataLoader(
dataset=testDataset,
batch_size=100,
shuffle=False,
)构建简单的神经网络并进行训练和测试:
class NeuralNet(nn.Module):
def __init__(self, input_num, hidden_num, output_num):
super(NeuralNet, self).__init__()
self.fc1 = nn.Linear(input_num, hidden_num)
self.fc2 = nn.Linear(hidden_num, output_num)
self.relu = nn.ReLU()
def forward(self,x):
x = self.fc1(x)
x = self.relu(x)
y = self.fc2(x)
return y
# 参数初始化
epoches = 5
lr = 0.001
input_num = 784
hidden_num = 500
output_num = 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 产生训练模型对象以及定义损失函数和优化函数
model = NeuralNet(input_num, hidden_num, output_num)
model.to(device)
criterion = nn.CrossEntropyLoss() # 使用交叉熵作为损失函数
optimizer = optim.Adam(model.parameters(), lr=lr)
# 开始循环训练
for epoch in range(epoches): # 一个epoch可以认为是一次训练循环
for i, data in enumerate(train_loader):
(images, labels) = data
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
output = model(images) # 经过模型对象就产生了输出
loss = criterion(output, labels.long()) # 传入的参数: 输出值(预测值), 实际值(标签)
optimizer.zero_grad() # 梯度清零
loss.backward()
optimizer.step()
if (i+1) % 100 == 0: # i表示样本的编号
print('Epoch [{}/{}], Loss: {:.4f}'
.format(epoch + 1, epoches, loss.item())) # {}里面是后面需要传入的变量
# loss.item
# 开始测试
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, 28*28).to(device) # 此处的-1一般是指自动匹配的意思, 即不知道有多少行,但是确定了列数为28 * 28
# 其实由于此处28 * 28本身就已经等于了原tensor的大小,所以,行数也就确定了,为1
labels = labels.to(device)
output = model(images)
_, predicted = torch.max(output, 1)
total += labels.size(0) # 此处的size()类似numpy的shape: np.shape(train_images)[0]
correct += (predicted == labels).sum().item()
print("The accuracy of total {} images: {}%".format(total, 100 * correct/total))以上是pytorch如何加载自己的图像数据集的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





