本篇内容介绍了“Uber用Go重写Schemaless数据库的分片层分析”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
摘要: 2014 年,Uber 构建了可扩展的容错数据库 Schemaless,但随着业务的增长,原实现方式对资源消耗更多,同时请求延迟也在增加,为了保持 Schemaless 的性能,Uber 在不影响生产服务的情况下用 Go 重写了 Schemaless 数据库的分片层,完成了将产品系统从旧实现迁移到新实现的 Frontless 项目。
2014 年,Uber 工程构建了可扩展的容错数据库 Schemaless ,为公司的快速发展提供了便利。我们仅在 2016 年就部署了 40 多个 Schemaless 实例和数千个存储节点。
随着业务的增长,我们的资源消耗和延迟也在增长;为了保持 Schemaless 的性能,我们需要一个能够很好的支持大规模应用的解决方案。在明确了假如将现有 Schemaless“集群”的 Python 工作节点用 Go (一种支持轻量级并发特性的语言) 重写的话,我们的数据库可以获得显著的性能提升后,我们在不影响正常生产的情况下,完成了将产品系统从旧实现迁移到新实现的任务。这一任务被称为 Frontless 项目,它证明了我们可以在不影响生产服务的情况下重写大型数据库的前端。
在本文中, 我们会讨论如何将 Schemaless 分片层从 Python 迁移到 Go,这一改变可以使我们用更少的资源来处理更多的流量,从而改善用户对我们服务的体验。
作为 Mezzanine 项目 ,Schemaless 于 2014 年 10 月首次推出,当初计划将 Uber 的核心 trip 数据库从一个独立的 Postgres 实例迁移到一个高可用的数据库中。
包含核心 trip 数据的 Mezzanine 数据库被构建为第一个 Schemaless 实例。从那时算起,目前已经部署了 40 多个 Schemaless 实例用于众多客户端服务。(关于我们内部数据库的完整历史演进过程,请参阅我们的三篇系列文章,Schemaless 的 设计 、 架构 和 triggers 概述)。
在 2016 年中,有数千个工作节点在 Schemaless 实例中运行,每个工作节点都消耗大量的资源。工作节点最初是使用 Python 和由 NGINX 交付的 uWSGI 应用程序服务器进程中的一个 Flask 微框架构建的,每个 uWSGI 进程一次处理一个请求。
该模型简单易行,易于建立,但不能有效地满足我们的需求。为了处理额外的同步请求,我们必须增加更多的 uWSGI 进程,每个进程都作为一个需要额外开销的新的 Linux 进程,因而这从根本上限制了并发线程的数量。在 Go 中,goroutines 被用来构建并发程序。goroutine 采用轻量级设计,是由 Go 的运行时系统管理的线程。
为了研究重写 Schemaless 分片层的优化增益,我们创建了一个实验性的工作节点,该节点实现了一个使用频率较高、资源消耗也比较高的端点。重写的结果显示,延迟减少了 85%,资源消耗减少的甚至更多。
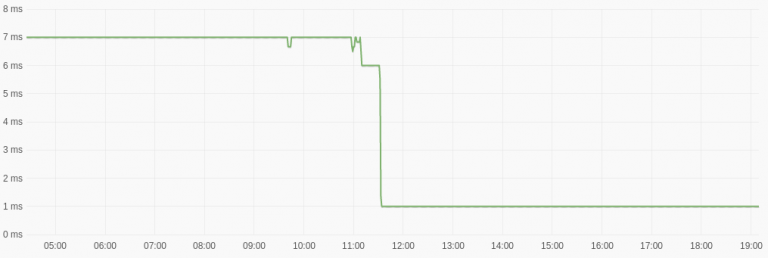
图 1:该图描述了 Frontless 形式实现的端点中值请求延迟情况
在进行了这个实验之后,我们明确了重写将使 Schemaless 通过释放 CPU 和内存来支持其所有实例中的依赖服务和工作节点。有了这些知识基础,我们启动了这个 Frontless 项目,用 Go 重写整个 Schemaless 分片层。
为了成功地重写 Uber 技术堆栈 的这个重要部分,我们需要确保我们的重新实现 100% 与现有的工作节点兼容。我们做了一个关键的决定,以验证新实现与原始代码的关系,这意味着每个对新 Go 工作节点的请求都要得到跟之前对 Python 工作节点请求相同的结果。
我们估计一个完整的重写会花费我们六个月的时间。在此期间,在 Uber 的生产系统中实现的新功能和 bug 修复将在 Schemaless 的情况下进行,所以我们的迁移有了一个动态的目标。我们选择了迭代开发形式,这样我们就可以一次性在一个端点上不断的从遗留的 Python 代码库中迁移出功能,并同时在新的 Go 代码库中验证。
最初,Frontless 工作节点只是在现有的 uWSGI Schemaless 工作节点前面的一个代理,所有请求都通过该节点。迭代将从重新实现一个端点开始,然后在生产中进行验证;当不再有错误出现后,新的实现才会正式上线。
从部署的角度来看,Frontless 和 uWSGI Schemaless 的工作是一起构建和部署的,这使得在所有实例中都可以实现统一的 Frontless,并同时支持所有生产场景的验证。
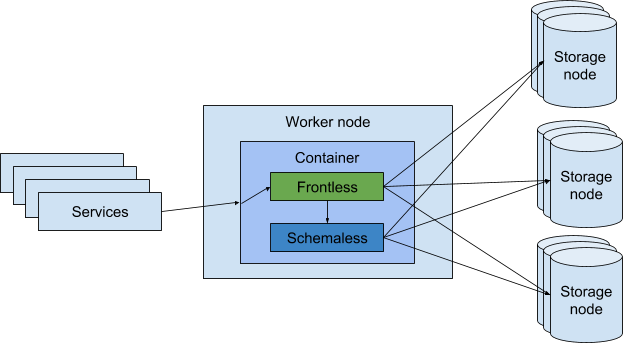
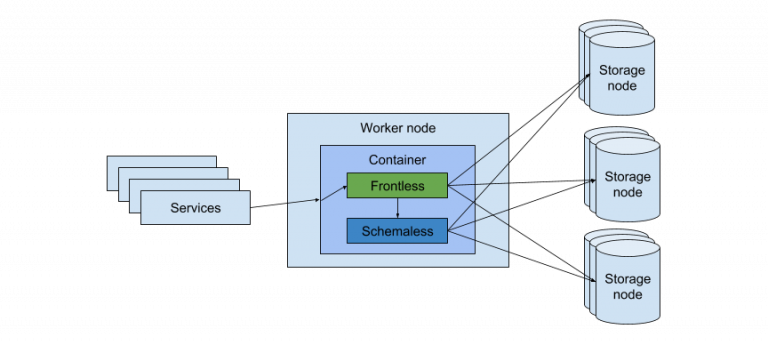
图 2:在我们的迁移过程中,一个名为 worker 节点的服务,其中 Frontless 和 Schemaless 在同一个容器中运行。Frontless 随后收到请求,并决定是否应该将其转发给 Schemaless,或者由 Frontless 处理。最后,Schemaless 或 Frontless 从存储节点获取结果,并将其返回给服务。
我们首先聚焦在用 Go 重新实现读取端点上。在我们最初的实现中,Schemaless 实例上读取端点处理平均占用 90% 的流量,并且它也是最消耗资源的。
当一个端点用 Frontless 实现后,将会启动验证进程,检测与 Python 实现的差异性。Frontless 和 Schemaless 执行请求操作时便会触发验证并对比响应结果。
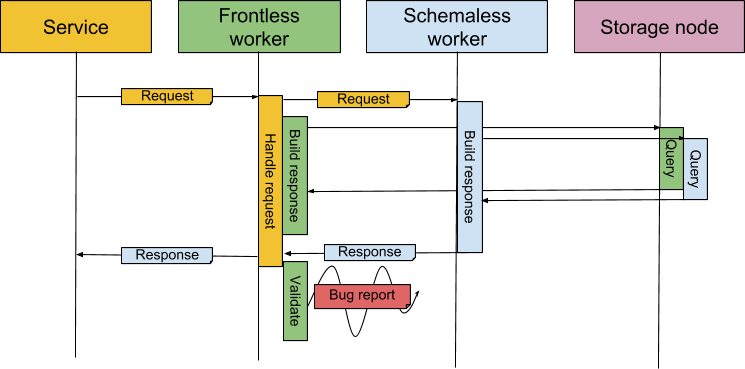
图 3:当一个服务发送请求到 Frontless 时,它会将请求转发给 Schemaless,该请求将通过查询存储节点生成响应。然后,由 Schemaless 做出的响应将返回到 Frontless,并将其转发给服务。Frontless 还将通过查询存储节点来创建响应。这两种响应是由 Frontless 和 Schemaless 构建的,如果出现任何差异,结果将作为 bug 报告发送给 Schemaless 开发团队。
使用此方法验证,将使发送到存储工作节点的请求数量增加一倍;为了使请求数量增加后工作正常,我们添加了配置标志来激活每个端点的验证,并调整请求验证的百分比阈值。这样便可以在几秒内启动或禁用对指定端点任意部分的验证功能。
Schemaless 的写入请求只能一次性成功,所以为了验证这些我们不能再使用以前的策略了。然而,由于与读取端点相比,在 Schemaless 中写入端点要简单得多,因此我们决定通过自动化集成测试来测试它们。
我们建立起了集成测试环境,这样 Schemaless Python 和 Frontless Go 就可以运行相同的测试场景了。测试是自动化的,可以在本地执行,也可以在几分钟内通过持续的集成来执行,这可以加快开发周期。
为了规模化测试我们的实现,我们设置了一个 Schemaless 测试实例,其中流量测试模拟了生产流量。在这个测试实例中,我们将 Schemaless 的 Python 流量写入实现迁移到了 Frontless 上,并运行验证来确保写入的正确性。
最后,一旦所有实现都满足生产环境时,我们就可以通过运行时配置将 Schemaless 的 Python 实现的流量写入功能缓慢地迁移到 Frontless 上,这样便可以在几秒钟内将部分流量写入工作移动到新的实现中。
到 2016 年 12 月为止,所有的 Mezzanine 数据库都是由 Frontless 处理的。如图 4 所示,所有请求的中值延迟降低了 85%,p99 请求延迟降低了 70%:
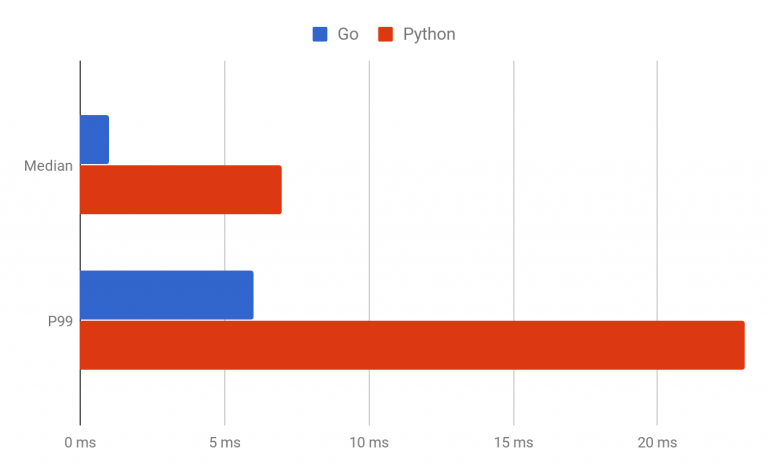
图 4:上图展示了由 Python(Schemaless 的工作语言,用红色表示) 和 Go(Frontless 的工作语言,用蓝色表示) 实现时数据库请求处理的时间。
随着我们 Go 的实现,Schemaless 的 CPU 使用率下降了 85% 以上。这种效率的增加让我们减少了在所有 Schemaless 实例中使用工作节点的数量,这些节点也是基于与以前相同的 QPS,这从而提高了节点利用率。
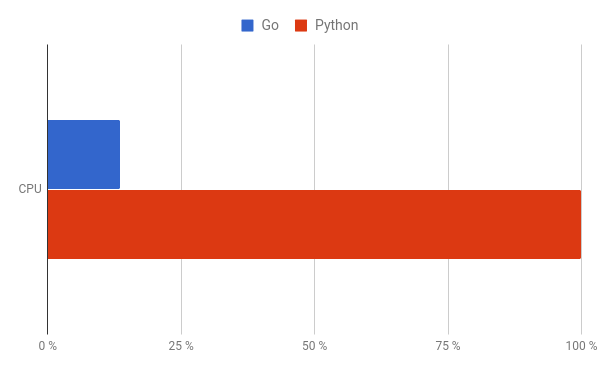
图 5:上面的图展示了在我们的数据库中由 Python(Schemaless 工作语言,红色的) 和 Go(Frontless 的工作语言,蓝色的) 处理的一个稳定的请求流中的 CPU 使用情况。
Frontless 项目表明,我们有可能在零停机的情况下,用一种全新的语言重写一个关键系统。通过重新实现服务而不改变 Schemaless 的现有客户端,我们能够在几天内而不是数周或几个月内实现、验证和启用端点。重点是,验证过程 (新的端点实现与现有生产中的实现进行比较) 给了我们信心,因为 Frontless 和 Schemaless 可以得到相同的结果。
然而,最重要的是,我们在生产中重写关键系统的能力证明了 Uber 迭代开发过程的可伸缩性。
“Uber用Go重写Schemaless数据库的分片层分析”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





