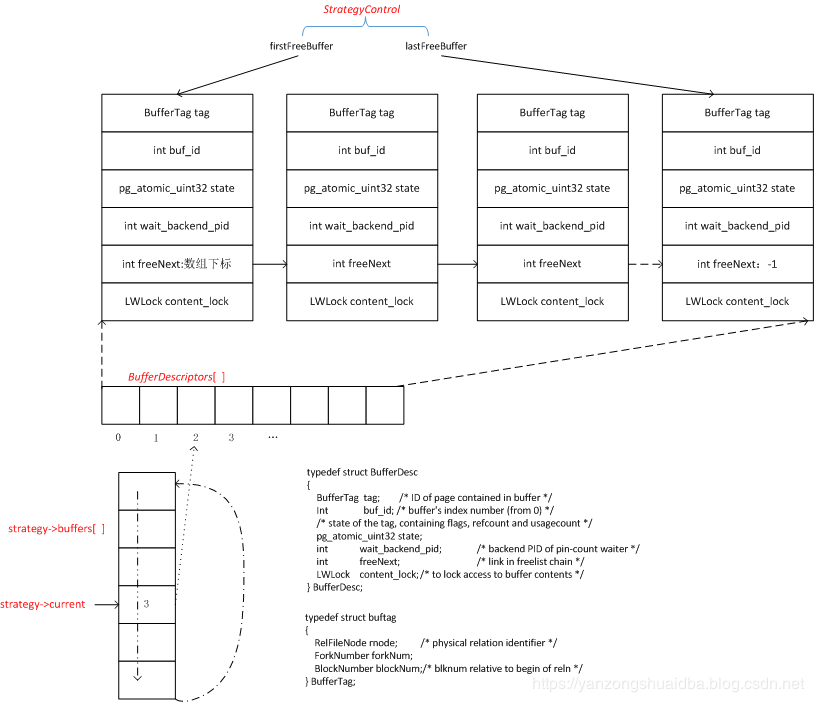
1、Buffer由数组BufferDescriptor[]数组进行管理。该数组由函数InitBufferPool创建,大小为NBuffers个成员即BufferDesc。该数组创建后由StrategyControl进行管理,firstFreeBuffer为链表头,指向链表第一个成员;lastFreeBuffer指向链表尾;所有free list中成员由freeNext串起来,该值为数组下标。
BufferDescriptor数组是共享内存中申请,所有进程共享。可以看到两个进程的BufferDescriptors地址相同:
进程1:
(gdb) p BufferDescriptors
$1 = (BufferDescPadded *) 0xa615fb80
(gdb) p *BufferDescriptors
$2 = {bufferdesc = {tag = {rnode = {spcNode = 1664, dbNode = 0,
relNode = 1262}, forkNum = MAIN_FORKNUM, blockNum = 0}, buf_id = 0,
state = {value = 2199126016}, wait_backend_pid = 0, freeNext = -2,
content_lock = {tranche = 53, state = {value = 536870912}, waiters = {
head = 2147483647, tail = 2147483647}}}, pad = "\200"}
进程2:
(gdb) p BufferDescriptors
$1 = (BufferDescPadded *) 0xa615fb80
(gdb) p *BufferDescriptors
$2 = {bufferdesc = {tag = {rnode = {spcNode = 1664, dbNode = 0,
relNode = 1262}, forkNum = MAIN_FORKNUM, blockNum = 0}, buf_id = 0,
state = {value = 2199126016}, wait_backend_pid = 0, freeNext = -2,
content_lock = {tranche = 53, state = {value = 536870912}, waiters = {
head = 2147483647, tail = 2147483647}}}, pad = "\200"}
2、同时还会通过一个环形区进行管理这些数组成员。当进行大表扫描时使用。由strategy->buffers[]数组管理,该数组存储的是BufferDescriptors[]数组的下标+1后的值,而每次取buf描述符时,从strategy->current值开始进行选择。选出的不可用后,依次向后进行遍历,遍历到头后从头再来进行选择,即形成一个环。是否可用的标准后文详述。
下面说下BufferDesc成员变量:
BufferTag tag为一个描述符对应磁盘物理页的映射。即space ID+database ID+文件ID -- forkNum(表文件还是fsm文件或者vm文件)-- 页号
buf_id为buffer数组BufferBlocks[]的下标
state为状态标记,包括该buffer的refcount和usagecount以及是否合法valid等待
wait_backend_pid:若进程A需要删除的元组所在缓冲块有其他进程访问,即refcount>0时,进程A不能物理上删除元组。系统将该进程的ID记录在wait_backend_id上,然后对缓冲块加pin,并阻塞自己。当refcount为1时最后一个使用该缓冲块的进程释放缓冲区时,会向wait_backend_id进程发送消息。
FreeNext为链表的下一个节点的下标
content_lock为buffer锁,当进程访问缓冲块时加锁,读加LW_SHARE锁,写加LW_EXCLUSIVE锁
二、共享buffer分配机制
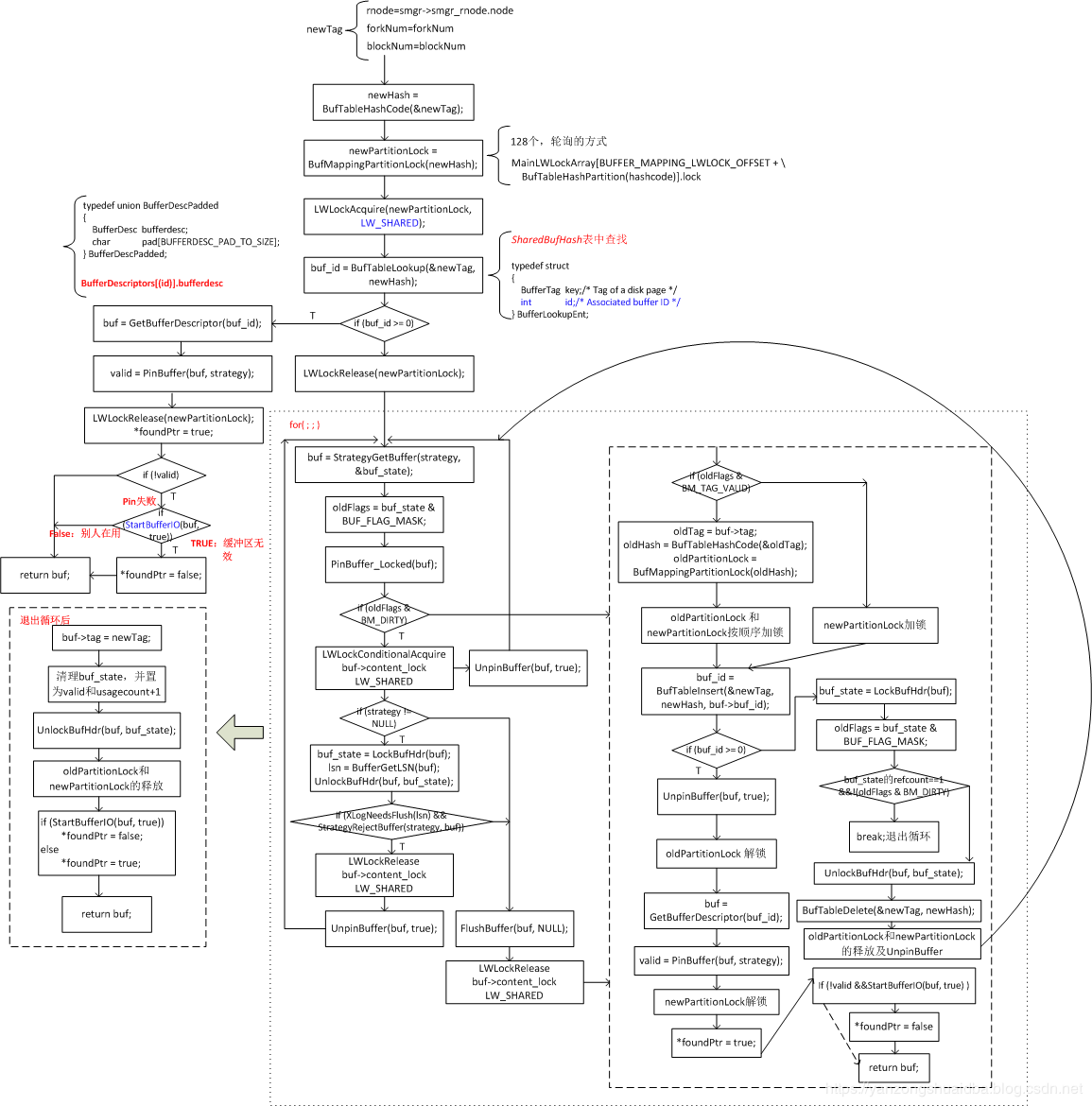
1、前期准备:
1)该buffer分配有4种情况:从hash表SharedBufHash中查找;从环形缓冲区查找;从free list查找以及驱逐策略进行分配。
2)hash表SharedBufHash同样是共享内存全局的,所有进程公有。下面分别是两个会话连接的server端进程打印出的hash表。
(gdb) p SharedBufHash $1 = (HTAB *) 0x87f5b04 (gdb) p SharedBufHash $1 = (HTAB *) 0x87f5b04
3)该hash表同样在InitBufferPool中进行创建:
StrategyInitialize->InitBufTable(NBuffers + NUM_BUFFER_PARTITIONS)-> SharedBufHash = ShmemInitHash
4)该hash表中条目为:[BufferTag,id]即key值为物理磁盘页的标志,id为对应buffer的ID
5)首先需要创建一个newTag,对应物理文件的一个页
6)通过newTag到函数BufTableHashCode中计算hash表的key值newHash
7)共有128个buffer partition锁,通过hash的key值以轮询的方式取锁
8)此时对key值对应的buffer partition加LW_SHARED锁
2、此时进入第一种获取buffer描述符的方法:所有进程共享的SharedBufHash
1)根据newTag从hash表SharedBufHash中查找对应的buffer
2)buf_id>0则表示数据页在hash表中找到,即对应数据页以加载到内存
3)根据buf_id获取buffer的描述符BufferDescriptors[buf_id)].bufferdesc
4)通过函数PinBuffer将对应buffer pin住,然后就可以将buffer的partition锁释放
即,将buf的state的refcount+1,usagecount根据情况+1,具体流程下文分析。
5)pin失败,通过StartBufferIO判断,返回TRUE,缓冲区无效,此时foundPtr为false,并返回对应buf;返回false,表示别人正在使用,直接返回对应buf。foundPtr表示是否在缓冲区命中
3、若hash表中不存在,则需要从磁盘读取。首先释放buf的partition锁,进入循环。
1)StrategyGetBuffer取出一个buf描述符,具体原理见下文。
2)PinBuffer_Locked将buf的refcount+1
3)此时该buf为脏块BM_DIRTY,则对buf->content_lock加LW_SHARED锁,加锁失败释放pin,返回1)。加锁成功根据strategy是否为空处理。
4)使用环形缓冲区,即strategy不为空:BM_LOCKED锁内获取buf脏页的lsn,根据lsn判断其日志是否已经刷写到磁盘,若未则将该buf从环形缓冲区删除;释放buf->content_lock锁及pin,返回1)重新循环进行选择。
5)使用环形缓冲区且日志已刷或者未使用环形缓冲区,则调用FlushBuffer将脏数据刷写磁盘,最后释放buf->content_lock锁。
6)接着进入4,当该页不为脏时也进入4
4、替换为自己的tag
1)先获取buf的oldTag,是谁用过。其oldPartitionLock和newTag的newPartitionLock按顺序加锁,若同一个则只加一个锁。LW_EXCUSIVE
2)将newTag对应的条目插入到hash表SharedBufHash
3)buf_id>=0,表示该条目已在hash表,那么unpin、oldPartitionLock锁释放后,获取老buf,pin后释放newPartitionLock
4)pin失败,通过StartBufferIO判断,返回TRUE,缓冲区无效,此时foundPtr为false,并返回对应buf;返回false,表示别人正在使用,直接返回对应buf。foundPtr表示是否在缓冲区命中 5)buf_id<0,即未在hash表SharedBufHash:buf_state的refcount==1且不为BM_DIRTY,表示无人使用该buf,退出循环,将buf->tag=newTag,最后释放相关锁
6)否则,需要释放相关锁,并将newTag对应的条目从hash表删除后,重新回到3进行选择。
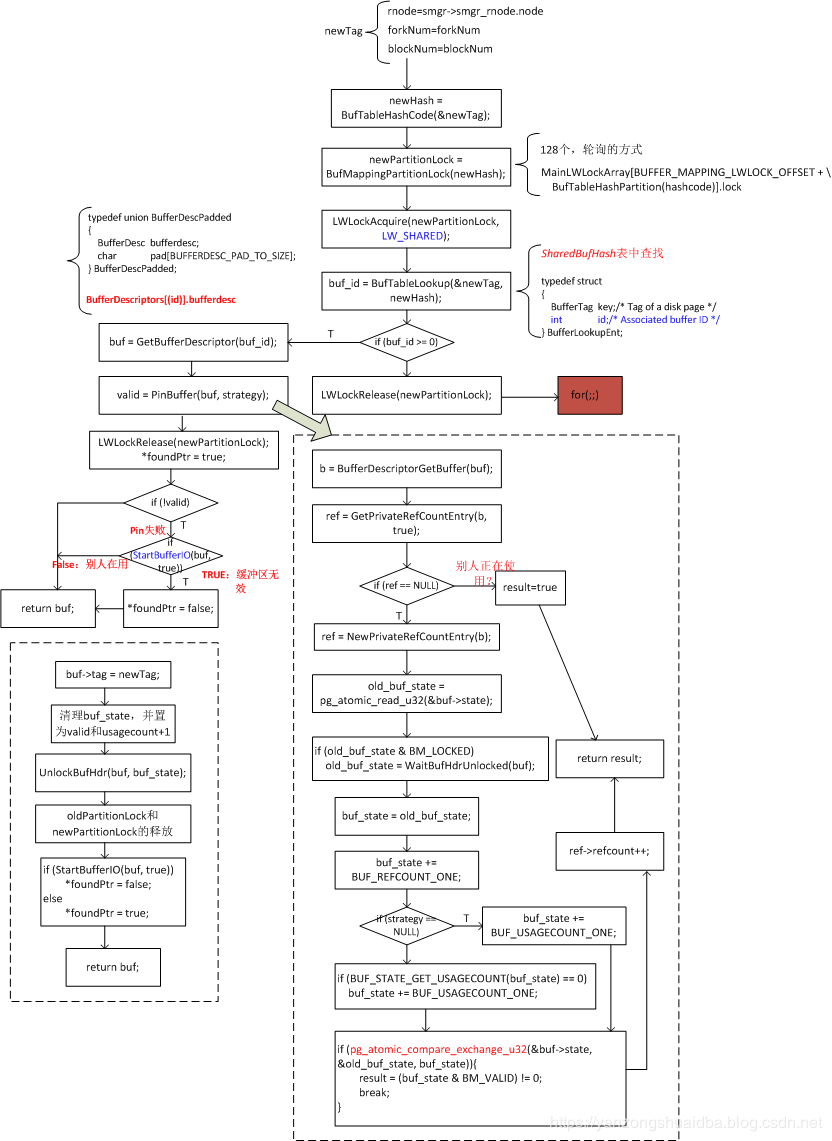
1、若buffer的state已为BM_LOCKED即已加锁,则需等待,该锁是pin锁
2、GetPrivateRefCountEntry获取ref,若ref不为NULL,则表示别人在使用,然后TRUE。是这样理解吗?需要理解这个函数
3、原子操作读取state值old_buf_state,并将之保存为buf_state
4、buf_state的refcount+1
5、默认策略下,即从free list中选择空闲描述符,buf_state的usagecount+1;环形缓冲区策略下,buf_state的usagecount保持为1
6、通过CAS操作将buf->state的值替换为buf_state的值
7、函数返回TRUE表示该buffer的数据有效,即合法的数据已经加载到内存;返回false表示数据无效,即数据未加载到内存
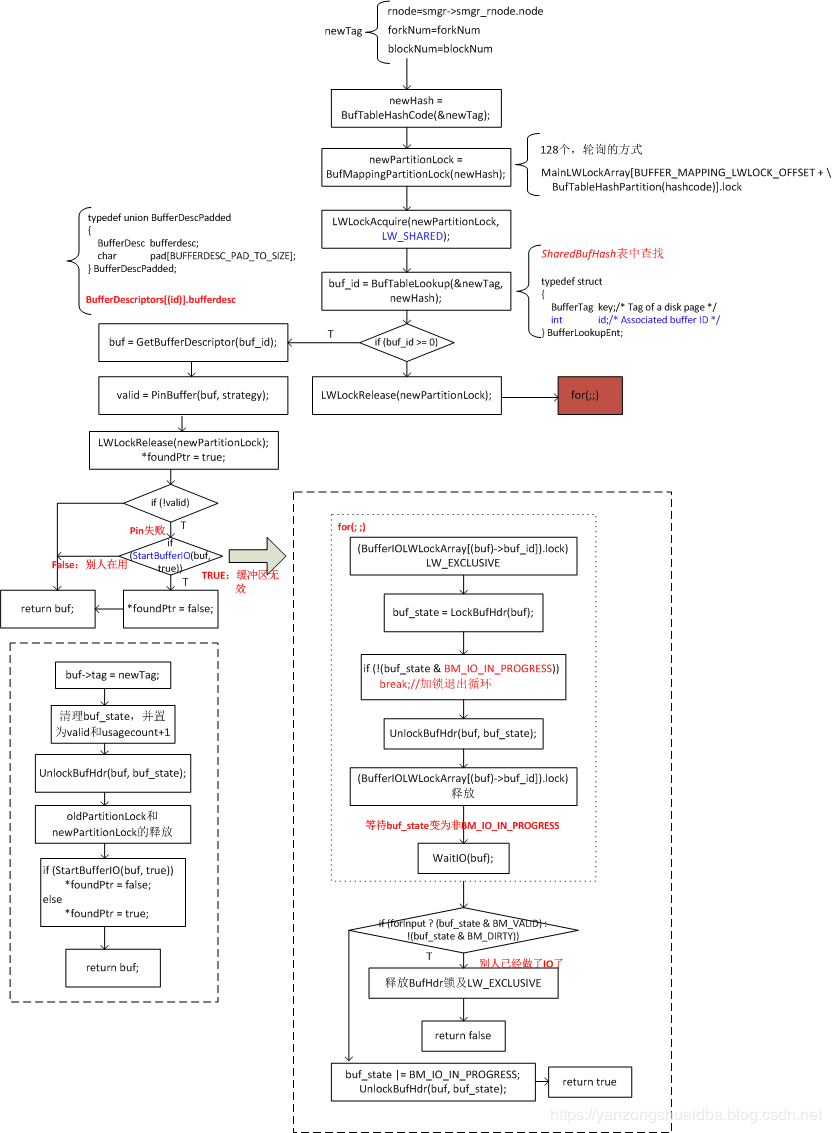
1、每个buffer都有一个IO锁(BufferIOLWLockArray[(bdesc)->buf_id]).lock
2、获取buf_state状态,需要先将其置为BM_LOCKED
3、该buf此时已为BM_IO_IN_PROGRESS,即正在读写,需要将上面两个锁释放后WaitIO等待状态变化
4、forInput为TRUE:要向里面写,需要其为!BM_VALID,若是BM_VALID表示有人已经向里写了合法数据;FALSE:需要向外读,若为!BM_DIRTY表示已有人刷写了。释放两个锁返回
5、将buf_state置为BM_IO_IN_PROGRESS。
6、返回TRUE,表示buf中数据无效,可以使用。False,表示别人正在使用
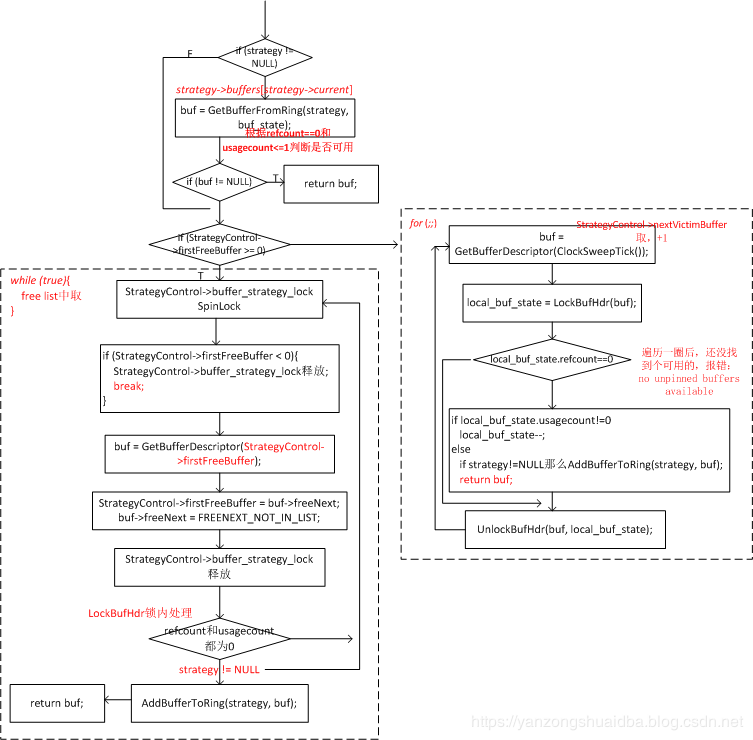
1、如果使用strategy,则从环形缓冲区取一个空闲的描述符:bufnum=strategy->buffers[strategy->current];buf = GetBufferDescriptor(bufnum - 1);,若没有可用的则GetBufferFromRing返回NULL,否则直接返回该buf。
2、环形缓冲区取buffer失败,则去free list取
3、StrategyControl->firstFreeBuffer>0,此时list不为空,
4、则先申请spin锁StrategyControl->buffer_strategy_lock,再次判断链表情况,若StrategyControl->firstFreeBuffer<0链表空了,则释放锁后退出循环,进入第8步
5、获取StrategyControl->firstFreeBuffer指向的buffer描述符,并将该节点从free list删除
6、释放StrategyControl->buffer_strategy_lock锁
7、该buf的refcount和usagecount都为0,则表示我们可以用,若strategy不为NULL,则现将该buf放到环形缓冲区,返回该buffer描述符;否则再次到第4步循环
8、此时free list都取了一遍,但是没有可用的,通过时钟算法,即循环StrategyControl->nextVictimBuffer取该buf,看其是否可用。同样如果找到后,根据strategy是否为NULL,将其放到环形缓冲区。将所有buf都取了一遍后,仍没有可用的话就报错:no unpinned buffers available
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





