heapster 已经 deprecated 了:https://github.com/kubernetes/heapster ,所以下面的演示主要针对 Kubernetes 1.10 之前的版本,我这里是新版本,所以是收集不到数据的。
Heapster 是容器集群监控和性能分析工具,天然的支持 Kubernetes 和 CoreOS。
Kubernetes 有个出名的监控 agent—cAdvisor。在每个 kubernetes Node 上都会运行 cAdvisor,它会收集本机以及容器的监控数据 (cpu,memory,filesystem,network,uptime)。在较新的版本中,K8S 已经将 cAdvisor 功能集成到 kubelet 组件中。每个 Node 节点可以直接进行
web 访问。
Heapster 是一个收集者,Heapster 可以收集 Node 节点上的 cAdvisor 数据,将每个 Node 上的 cAdvisor 的数据进行汇总,还可以按照 kubernetes 的资源类型来集合资源,比如 Pod、Namespace,可以分别获取它们的 CPU、内存、网络和磁盘的 metric。默认的 metric 数据聚合时间间隔是1分钟。还可以把数据导入到第三方工具(如 InfluxDB)。
Kubernetes 原生 dashboard 的监控图表信息来自 heapster。在 Horizontal Pod Autoscaling 中也用到了 Heapster,HPA 将 Heapster 作为 Resource Metrics API,向其获取 metric。
架构图 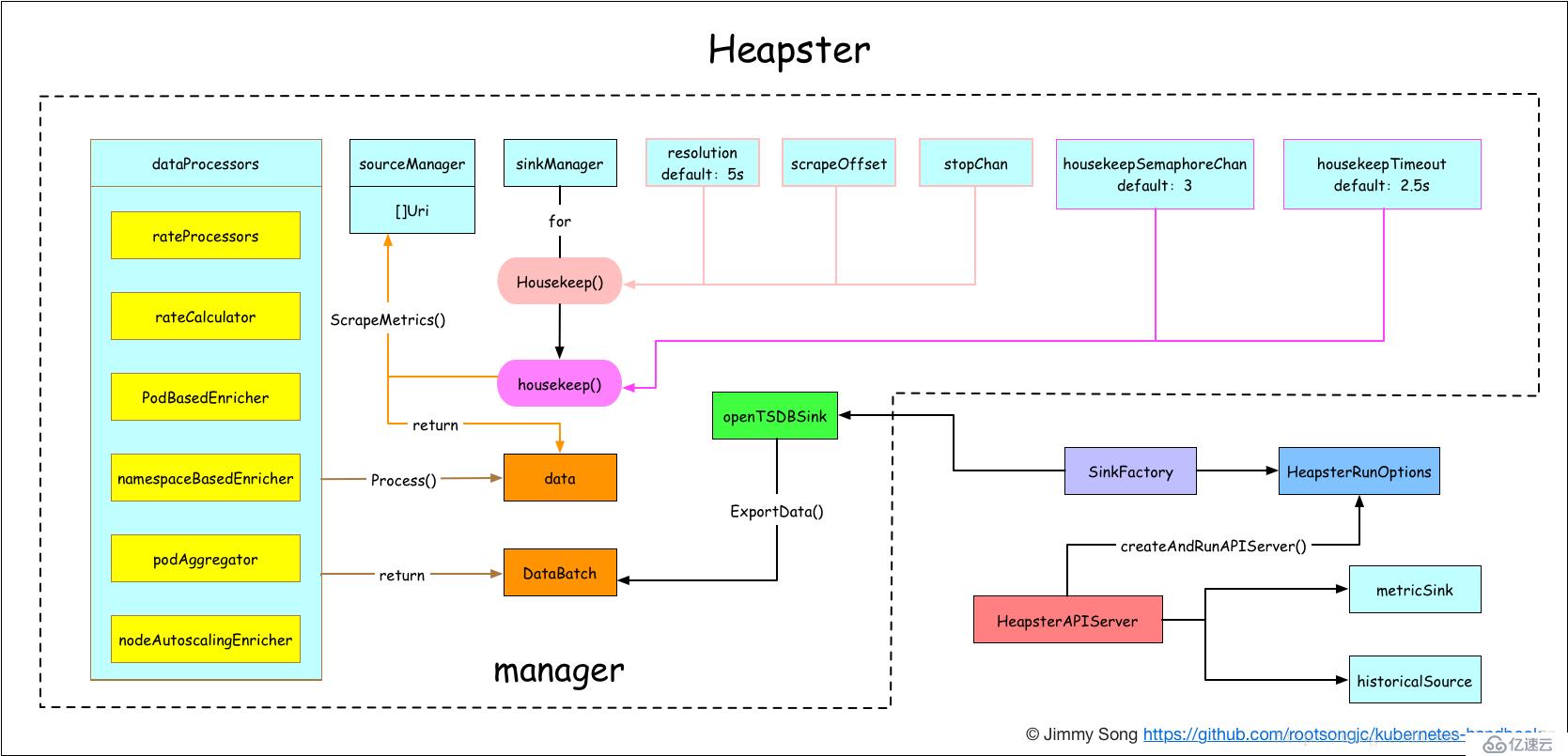
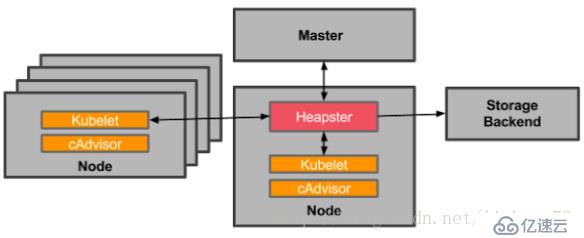
Heapster 首先从 apiserver 获取集群中所有 Node 的信息,然后通过这些 Node 上的 kubelet 获取有用数据,而 kubelet 本身的数据则是从 cAdvisor 得到。所有获取到的数据都被推到 Heapster 配置的后端存储中,并还支持数据的可视化。现在后端存储 + 可视化的方法,如InfluxDB + grafana。
Heapster 本身是一个 Kubernetes 应用,部署方法很简单,运行如下命令:
[root@master ~]# git clone https://github.com/kubernetes/heapster.git
[root@master ~]# kubectl apply -f heapster/deploy/kube-config/influxdb/
deployment.extensions/monitoring-grafana created
service/monitoring-grafana created
serviceaccount/heapster created
deployment.extensions/heapster created
service/heapster created
deployment.extensions/monitoring-influxdb created
service/monitoring-influxdb created
[root@master ~]# kubectl apply -f heapster/deploy/kube-config/rbac/heapster-rbac.yaml
clusterrolebinding.rbac.authorization.k8s.io/heapster created因为众所周知的原因,有些镜像我们是下载不下来,只能间接的获取,我们还是在阿里云的仓库里面找一下。
docker pull registry.cn-hangzhou.aliyuncs.com/k8s_grc_io/heapster-amd64:v1.5.4
docker tag registry.cn-hangzhou.aliyuncs.com/k8s_grc_io/heapster-amd64:v1.5.4 k8s.gcr.io/heapster-amd64:v1.5.4
docker image rm registry.cn-hangzhou.aliyuncs.com/k8s_grc_io/heapster-amd64:v1.5.4
docker pull registry.cn-hangzhou.aliyuncs.com/k8s-kernelsky/heapster-grafana-amd64:v5.0.4
docker tag registry.cn-hangzhou.aliyuncs.com/k8s-kernelsky/heapster-grafana-amd64:v5.0.4 k8s.gcr.io/heapster-grafana-amd64:v5.0.4
docker image rm registry.cn-hangzhou.aliyuncs.com/k8s-kernelsky/heapster-grafana-amd64:v5.0.4
docker pull registry.cn-hangzhou.aliyuncs.com/k8s-images1/heapster-influxdb-amd64:v1.5.2
docker tag registry.cn-hangzhou.aliyuncs.com/k8s-images1/heapster-influxdb-amd64:v1.5.2 k8s.gcr.io/heapster-influxdb-amd64:v1.5.2
docker image rm registry.cn-hangzhou.aliyuncs.com/k8s-images1/heapster-influxdb-amd64:v1.5.2Heapster 相关资源如下:
[root@master ~]# kubectl get pod -n kube-system |grep -e heapster -e monitor
heapster-f64999bc-8x7j7 1/1 Running 0 16m
monitoring-grafana-564f579fd4-jsx2r 1/1 Running 0 16m
monitoring-influxdb-8b7d57f5c-ntnxc 1/1 Running 0 16m
[root@master ~]# kubectl get deploy -n kube-system |grep -e heapster -e monitor
heapster 1/1 1 1 16m
monitoring-grafana 1/1 1 1 16m
monitoring-influxdb 1/1 1 1 16m
[root@master ~]# kubectl get svc -n kube-system |grep -e heapster -e monitor
heapster ClusterIP 10.101.170.222 <none> 80/TCP 16m
monitoring-grafana ClusterIP 10.104.60.71 <none> 80/TCP 16m
monitoring-influxdb ClusterIP 10.104.104.41 <none> 8086/TCP 16m为便与访问,可以通过 kubectl edit 将 Service monitoring-grafana的类型修改为 NodePort。
[root@master ~]# kubectl patch svc monitoring-grafana -p '{"spec":{"type":"NodePort"}}' -n kube-system
service/monitoring-grafana patched目前我们的 Pod heapster,是采集不到数据的,因为已经被废弃,大家可以通过下面的命令查看到错误信息。
kubectl logs heapster-f64999bc-8x7j7 -n kube-system浏览器打开 Grafana 的 Web UI:http://MASTER_IP:32314/
Heapster 已经预先配置好了 Grafana 的 DataSource 和 Dashboard。
Heapster 预定义的 Dashboard 很直观也很简单。如有必要,可以在 Grafana 中定义自己的 Dashboard 满足特定的业务需求。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



