本篇内容介绍了“PG体系结构是怎样的”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
##pg 结构
--逻辑结构
--数据库实例通常指数据库集簇(database cluster),单个实例管理数据库集合
--一个数据库集簇包含用户、数据库,可为每个数据库指定单独的用户,每个数据库下面包含schemas(命名空间),默认为public,每个schemas下面包含表、索引、视图、序列等。
--物理结构
--数据文件、参数文件、控制文件、数据库运行日志及预写日志
--可通过以下命令查看目录文件,具体作用可参考《Postgresql实战》98页
tree -L 1 -d /pgdata/10/data
--控制文件位置
[postgres@pgtest global]$ pwd
/pgdata/data/global
[postgres@pgtest global]$ ls -l pg_control
-rw------- 1 postgres postgres 8192 Dec 7 04:56 pg_control
--数据文件布局
--oid,所有数据库对象都有各自的对象标识符(oid)进行内部管理,它们是无符号的4字节整数,例如
select oid,datname from pg_database;
select oid,relname,relkind from pg_class;
--表空间,最大的逻辑存储单位
--默认两个表空间,pg_global表空间,目录为global,保存系统表;pg_default表空间的物理文件位置在base目录,是template0和template1数据库的默认表空间,
--创建表空间需要先创建目录,表空间可以解决以后磁盘空不足问题、分配性能不同的磁盘上,提高数据库性能
mkdir -p /pgdata/10/mytblspc
create tablespace myspc location '/pgdata/10/mytblspc';
create table t(id int4) tablespace myspc;
--数据文件命名,对于表大小超出1g,pg会自动切分多个文件,oid.顺序号,真正管理表文件的是pg_class的relfilenode
--查看表的大小
select pg_size_pretty(pg_relation_size('tb1'::regclass));
--表文件内部结构
--pg中,保存在磁盘中的块称为Page,内存中的块称为Buffer,表和索引称为Relation,行称为Tuple。数据读写以Page为最小单位,Page默认8KB
##进程结构
--守护进程与服务进程
--postmaster进程主要职责
数据库的启停
监听客户端连接
为每个客户端连接fork单独的postgres服务进程
当服务进程出错时进行修复
管理数据文件
管理与数据库运行相关的辅助进程
--辅助进程
background writer:bgwriter进程,搜索共享缓冲池找到被修改的页,并将它们从共享缓冲池刷出
autovacuum launcher: 自动清理回收垃圾进程
WAL writer: 定期将WAL缓冲区上的WAL数据写入磁盘
statistics collector: 统计信息收集进程
logging collector: 日志进程,将消息或者错误信息写入日志
archiver:WAL归档进程
checkpointer:检查点进程
##内存结构
--本地内存主要给后端进程使用,主要三部分
work_mem: 当使用order by 或distinct会使用到
maintenance_work_mem: 维护操作,例如VACUUM REINDEX CREATE INDEX等操作
temp_buffers: 临时表相关操作使用
--共享内存,在服务器启动时分配,由所有后端进程共同使用
shared buffer pool :PostgreSQL将表和索引页面从持久存储装载到这里,并直接操作它们
WAL buffer: WAL文件持久化之前的缓冲区
CommitLog buffer:PostgreSQL 在Commit Log中保存事务的状态,并将这些状态保留在共享内存缓冲区中,在整个事务处理过程中使用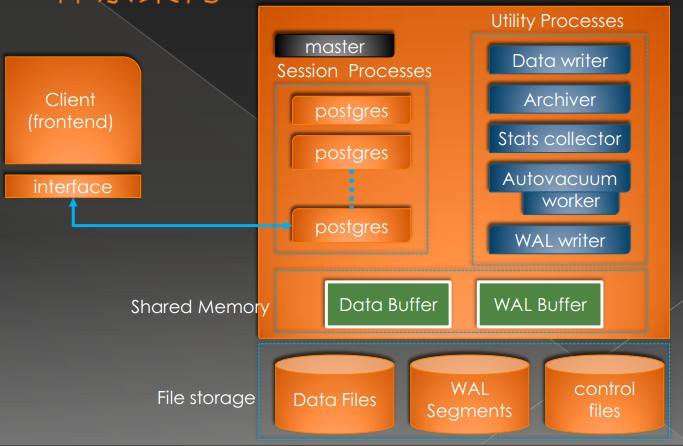
“PG体系结构是怎样的”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/29487349/viewspace-2374750/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



