Oracle 面试宝典 - 等待事件篇
请问Oracle 数据库中等待事件的作用是什么 ?
一、等待事件由来
因为指标体系的发展,才导致等待事件的引入。总结一下,Oracle 的指标体系,大致经历了下面三个阶段:
(1) 以命中率为主要参考指标
以各种命中率为主要的优化入口依据,常见的有” library cache hit radio “等。但这种方式弊端很大,一个命中率为 99% 的系统,不一定就比 95% 的系统优化的更好。在老的 Oracle 版本中,往往采用这种方式,如 8i 、 9i 等。
命中率是近20 年前系统性能优化的一种观点,后来该观点被证明有一定的偏差而被同行逐渐弃用,不能说完全错,命中率只能说是一个参考指标。
20 年后的今天,性能优化的理论、实践和手段,相比之前都有了很大的积累和发展。现在,对性能问题进行分析和诊断,更注重各方面信息的综合分析,而不是单纯看某个指标。比较典型的,例如:系统的综合性能情况,可以通过查看 ash 、 awr 、 addm 或 osw 等各种报告进行分析和确定,单个 SQL 语句的性能也主要是结合具体 SQL 、执行计划及数据环境进行分析,获取执行计划的方法比较多,但大同小异,本质差不多。
至于性能分析诊断的思路和方法,一般是从整体到局部,逐渐细化的方法和步骤。
(2) 以等待事件为主要参考指标
以各种等待事件为优化入口依据,常见的有"db file sequential read" 等。可以较直观的了解,在一段时间内,数据库主要经历了那些等待。这些 " 瓶颈 " ,往往就是我们优化的着手点。在 10g 、 11g 版本中,广泛使用。
(3) 以时间模型为主要参考指标
以各种资源整体消耗为优化入口依据。可以从整体角度了解数据库在一段时间内的消耗情况。较等待事件的方式,更有概括性。常见的如"DB Time" 。 Oracle 在不断加强这个方面的工作。
从上面三个阶段可见,等待事件的引入,正是为了解决以命中率为指标的诸多弊端。与后面的时间模型相比,等待事件以更加直观、细粒度的方式观察Oracle 的行为,往往作为优化的重要入口。而时间模型,更侧重于整体、系统性的了解数据库运行状态。两者的侧重点不同。
请问Oracle 数据库有哪些类型的等待事件?
等待事件可分为空闲的、非空闲的两大部分。在非空闲的等待事件,又可进一步划分细的类别。
空闲等待:
空闲等待事件,是指Oracle 正等待某种工作,比如用 sqlplus 登录之后,但没有进一步发出任何命令,此时该 session 就处于 SQL*Net message from/to client 等待事件状态,等待用户发出命令,任何的在诊断和优化数据库的时候,一般不用过多注意这部分事件。
非空闲等待:
非空闲等待事件,专门针对Oracle 的活动,指数据库任务或应用运行过程中发生的等待,这些等待事件是调整数据库的时候应该关注与研究的。
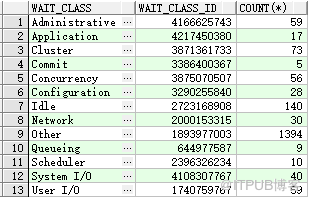
等待事件分类说明:
select wait_class , wait_class_id , count (*)
from v$event_name
group by wait_class , wait_class_id
order by 1 ;
--- 数据库版本 Oracle 19C, 等待事件数量 192 0 个 ( 在 Oracle 10g 等待事件有 872 个, 11g 等待事件 1116 个 ) 。
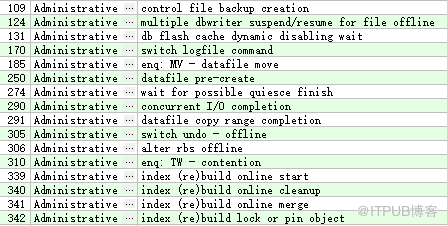
管理类-Administrative
此类等待事件是由于DBA 的管理命令引起的,这些命令要求用户处于等待状态(比如,重建索引) 。
例如:
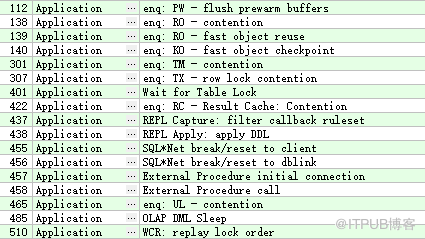
应用程序类-Application
此类等待事件是由于用户应用程序的代码引起的(比如,锁等待)。
例如:
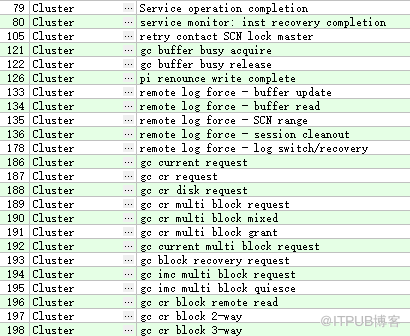
群集类-Cluster
此类等待事件和 Oracle RAC 的资源有关(比如, gc cr block busy 等待事件)。
例如:
提交确认类-Commit
此类等待事件只包含一种等待事件—— 在执行了一个 commit 命令后,等待一个重做日志写确认 。
例如:

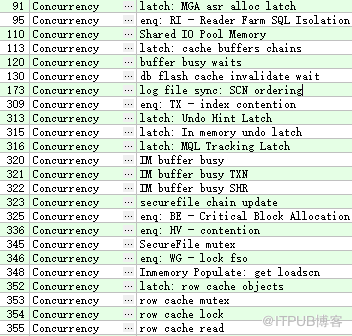
并发类-Concurrency
此类等待事件是由内部数据库资源引起的(比如闩锁) 。
例如:
配置类-Configuration
此类等待事件是由数据库或实例的不当配置造成的(比如,重做日志文件尺寸太小,共享池的大小等)。
例如:

空闲类-Idle
此类等待事件意味着会话不活跃,等待工作(比如,sql * net messages from client )。
例如:

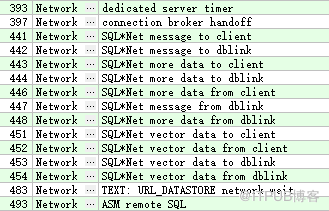
网络类-Network
和网络环境相关的一些等待事件(比如sql* net more data to dblink )。
例如:
其它类-Other
此类等待事件通常比较少见。
例如:

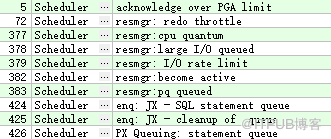
调度类-Scheduler
此类等待事件和资源管理相关。
例如:
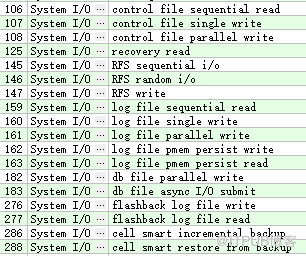
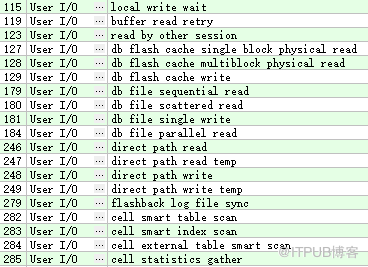
系统I/O 类 -System I/O
此类等待事件通过是由后台进程的I/O 操作引起的(比如 DBWR 等待 -db file paralle write )。
例如:
用户I/O 类 -User I/O
此类等待事件通常是由用户I/O 操作引起的(比如 db file sequential read ) 。
例如:
请描述下你经常遇到的10 个等待事件?
一:buffer busy wait
类型:并发类
发生原因:
当一个会话将数据块从磁盘读到内存中时,它需要到内存中找到空闲的内存空间来存放这些数据块,当内存中没有空闲的空间时,就会产生这个等待。除此之外,还有一种情况就是会话在做一致性读时,需要构造数据块在某个时刻的前映像。此时需要申请内存块来存放这些新构造的数据块,如果内存中无法找到这样的内存块,也会发生这个等待事件。
优化方向:
根据产生此等待事件的类别不同,优化方向也不太一样。
如何找出产生此等待事件的对象和对象类型?
在出现 buffer busy waits 时查询V$SESSION 中的 ROW_WAIT_OBJ# 值。例如 :
SELECT row_wait_obj# FROM V$SESSION WHERE EVENT = 'buffer busy waits' ;
要识别争用的对象和对象类型,可以使用从V$SESSION 返回的 ROW_WAIT_OBJ# 的值来查询 DBA_OBJECTS 。例如 :
SELECT owner , object_name , subobject_name , object_type
FROM DBA_OBJECTS
WHERE data_object_id = &row_wait_obj ;
或者通过SID 查找对应块号,文件号,类型
select event, sid, p1, p2, p3
from v$session_wait
where sid in (69, 75)
and event like '%buffer busy waits%';
---
P1: File ID
P2: Block ID
P3: Class ID
p1 、 p2 参数和 dba_extents 进行联合查询得到 block 所在的 segment 名称和 segment 类型
对象类型: 数据块
某一或某些数据块被多个进程同时读写,成为热点块,可以通过如下这些办法来解决这个问题:
(1) 降低程序的并发度,如果程序中使用了 parallel 查询,降低 parallel degree ,以免多个 parallel slave 同时访问同样的数据对象而形成等待降低性能;
(2) 调整应用程序使之能读取较少的数据块就能获取所需的数据,减少 buffer gets 和 physical reads ;
(3) 减少同一个 block 中的记录数,使记录分布于更多的数据块中,这可以通过若干途径实现:可以调整 segment 对象的 pctfree 值,可以将 segment 重建到 block size 较小的表空间中,还可以用 alter table minimize records_per_block 语句减少每块中的记录数;
(4) 若热点块对象是类似自增 id 字段的索引,则可以将索引转换为反转索引,打散数据分布,分散热点块 。
优化方向: 一般优化方向是优化SQL ,减少逻辑读、物理读;或者是减少单块的存储数据规模。
对象类型: 数据段头
进程经常性的访问 data segment header 通常有两个原因
(1) 获取或修改 process freelists 信息
进程频繁访问process freelists 信息导致 freelist 争用,我们可以增大相应的 segment 对象的存储参数 freelist 或者 freelist groups ;若由于数据块频繁进出 freelist 而导致进程经常要修改 freelist ,则可以将 pctfree 值和 pctused 值设置较大的差距,从而避免数据块频繁进出 freelist ;
(2) 扩展高水位标记
由于该segment 空间消耗很快,而设置的 next extent 过小,导致频繁扩展高水位标记,解决的办法是增大 segment 对象的存储参数 next extent 或者直接在创建表空间的时候设置 extent size uniform ;
优化方向 : 增加FREELISTS 和 FREELIST GROUPS 。确保 FCTFREE 和 PCTUSED 之间的间隙不是太小,从而可以最小化 FREELIST 的块循环。
对象类型: 撤销块
undo block 争用是由于应用程序中存在对数据的读和写同时进行,读进程需要到 undo segment 中去获得一致性数据,解决办法是错开应用程序修改数据和大量查询数据的时间 。
优化方向: 应用程序,错峰使用数据对象。
对象类型: 撤销段头
undo segment header 争用是因为系统中 undo segment 不够,需要增加足够的 undo segment ,根据 undo segment 的 管理 方法,若是手工管理模式,需要修改rollback_segments 初始化参数来增加 rollback segment ,若是自动管理模式,可以减小 transactions_per_rollback_segment 初始化参数的值来使 oracle 自动增多 rollback segment 的数量 。
优化方向: 如果是数据库系统管理UNDO 段,一般不需要干预。如果是自行管理的,可以减少每个回滚段的事务个数 。
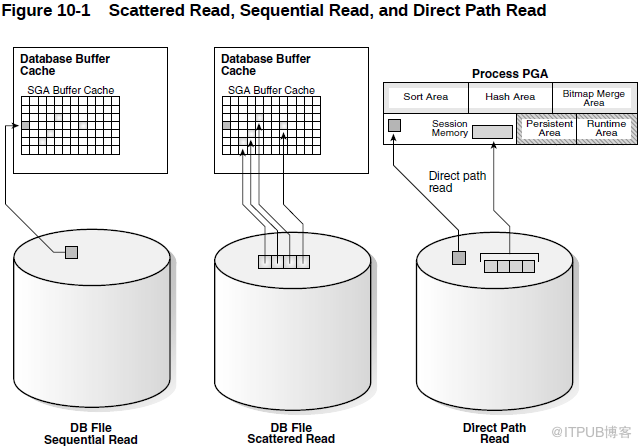
二:db file sequential read
类型: 用户I/O 类
发生原因: db file sequential read 事件和 Single Block I/O 有关。
该等待事件是将数据读到连续的内存( 这里指的是读到相连的内存,不是说读取的是连续的数据块 ) 。大多数情况下读取一个索引块或者通过索引读取一个数据块,会记录这个等待。可能显示表的连接顺序不佳,或者不加选择地进行索引。对于大量事务处理、调整良好的系统,这一数值大多是很正常的,但在某些情况下,它可能暗示着系统中存在问题。应当将这一等待统计量与性能报告中的已知问题(如效率较低的 SQL )联系起来。检查索引扫描,以保证每个扫描都是必要的,并检查多表连接的连接顺序。
参数含义:
file# : 代表oracle 要读取的文件的绝对文件号
block# : 从这个文件中开始读取的起始数据块块号
Blocks : 读取的block 数量。通常是 1 ,表示单个 block 读取。
优化方向:
这个等待事件,不一定代表一定有问题。如果能确定是有问题,可以按照下面优化思路。
1 修改应用,避免出现大量IO 的 sql ,或者减少其频率 或优化SQL 。
2 增加data buffer ,提高命中率。
3 采用更好的磁盘子系统,减少单个IO 的响应时间,防止物理瓶颈的出现。
三: db file scattered read
类型: 用户I/O 类
发生原因: Oracle 在执行全表扫描 ( Full Table Scan,FTS) 、索引快速全扫描 ( Index Fast Full Scan) 时,为保障性能,尽量一次性读取多个块,这称为 Multi Block I/O 。 每次执行 Multi Block I/O ,都会等待物理 I/O 结束,此时等待 db file scattered read 事件。这里 scattered 指的是读取的数据块在内存中的存放方式。它们被读取到内存中后,是以分散的方式存放在内存中,而不是连续的。
参数含义:
file# : 代表oracle 要读取的文件的绝对文件号。
block# : 从这个文件中开始读取的起始数据块块号。
Blocks : 读取的block 数量。
优化方向:
这种情况通常显示与全表扫描相关的等待。当全表扫描被限制在内存时,它们很少会进入连续的缓冲区内,而是分散于整个缓冲存储器中。如果这个数目很大,就表明该表找不到索引,或者只能找到有限的索引。尽管在特定条件下执行全表扫描可能比索引扫描更有效,但如果出现这种等待时,最好检查一下这些全表扫描是否必要。如果是某些SQL 引起的,例如统计信息不准确,没有索引或使用低效的索引等,可以通过优化 SQL ,降低 db file scattered read 。
四 :direct path read
类型: 用户I/O 类
发生原因:
这个等待事件发生在会话将数据块直接读取到PGA 当中而不是 SGA 中的情况,这些被读取的数据通常是这个会话私有的数据,所以不需要放到 SGA 作为共享数据,因为这样做没有意义。这些数据通常是来自于临时段上的数据,比如一个会话中 SQL 的排序数据,并行执行过程中间产生的数据,以及 Hash join 、 Merge join 产生的排序数据,因为这些数据只对当前会话的 SQL 操作有意义,所以不需要放到 SGA 当中。 当发生direct path read 等待事件时,意味着磁盘上有大量的临时数据产生,比如排序、并行执行等操作,或者意味着 PGA 中空闲空间不足 。
在11g 中,全表扫描可能使用 direct path read 方式,绕过 buffer cache ,这样的全表扫描就是物理读了。在 10g 中,都是通过 buffer cache 来读的,所以不存在direct path read 的问题。
参数含义:
file# : 文件号
first block# : 读取的起始块号
block count : 以first block 为起点,连续读取的物理块数
优化方向:
有了这个等待事件,需要区分几种情况。一个方向是增大排序区等手段,一个方向是减少读取IO 量或判断是否通过缓冲区读的方式更加高效。
direct path read 可能出现的问题:
在Oracle 11g 中有一个新特性,为了保护已经缓存在 buffer cache 的数据,当出现全表扫的查询时会判断该表的大小。如果该表过大,则使用直接路径读( Direct Path Read )来获取数据。避免大量冷数据对 Buffer Cache 的冲击。通过直接路径读的方式绕过 SGA 从存储上获取数据。由于没有 SGA 的缓存,每一次查询都需要从存储读取产生了大量的物理读,可能会导致 I/O 负载过高。
新特性中如何判断全表扫的大小呢?
下面看一个隐含参数:_small_table_threshold
该参数默认为Buffer Cache 的 2% ,如果表大于 5 倍 _small_table_threshold 就触发该特性。自动会使用 DPR 替代 FTS 。
可以通过设置10949 事件屏蔽这个特性,返回到 Oracle 11g 之前的模式上:
alter session set events '10949 trace name context forever, level 1';
小表受到隐含参数:_small_table_threshold 影响。如果表大于 5 倍的小表限制,则自动会使用 DPR 替代 FTS 。 可以设置初始化参数: _serial_direct_read 来禁用串行直接路径读。
五: db file single write
类型: 用户I/O 类
发生原因: 其中一种情况,Oracle 更新数据文件头信息时(比如发生 CheckPoint )会出现这种等待事件。要考虑数据库中的数据文件数量太大,导致 Oracle 需要花较长的时间来做所有文件头的更新操作( CheckPoint )。
这个等待事件包含三个参数:
file# :要读取的数据块所在数据文件的文件号。
block# :读取的起始数据块号。
blocks :需要读取的数据块数目。(通常来说在这里应该等于 1 )
六:direct path write
类型: 用户I/O 类
发生原因: 这个等待事件和direct path read 正好相反, 发生在oracle 直接从 PGA 写数据到数据文件或临时文件,这个操作可以绕过 SGA 。 可以执行 direct path writes 的操作包括 磁盘排序、并行DML 操作、直接路径插入、并行 create table as select 操作以及一些LOB 操作 。 对于这种情况应该找到操作最为频繁的数据文件( 如果是排序,很有可能是临时文件 ) ,分散负载。
参数含义:
file# :文件号
first block# :读取的起始块号
block count :以 first block 为起点,连续写入的物理块数
优化方向:减少IO 写入规模。
七:log file sync
类型: 提交类
发生原因:
这是一个用户会话行为导致的等待事件。当一个会话发出一个commit 命令时, LGWR 进程会将这个事务产生的 redo log 从 redo log buffer 里写到 redo log file 磁盘上,以保证用户提交的信息被安全地记录到数据库中。会话发出 commit 指令后,需要等待 LGWR 将这个事务产生的 redo 成功写入到磁盘之后,才可以继续进行后续的操作,这个等待事件就叫做 log file sync 。当系统中出现大量的 log file sync 等待事件时,应该检查数据库中是否有用户在做频繁的提交操作。这种等待事件通常发生在 OLTP 系统上。 OLTP 系统中存在很多小的事务,如果这些事务频繁被提交,可能引起大量 log file sync 的等待事件。
优化方向:
下面优化建议,有助于减少log file sync 等待:
(1) 优化 LGWR 速度,以获得良好的磁盘吞吐量。例如: redo log file 不要放在 RAID 5 上 ( 可以考虑 RAID 0 或 RAID 1+0) ;
(2) 如果有大量小事物,最好可以批量提交,减少提交次数;
( 3 ) 特定场景可以考虑使用 NOLOGGING / UNRECOVERABLE 选项 ( 谨慎使用 ) ;
( 4 ) 保证 redolog 足够大,确保日志切换间隔在 15-20 分钟;
( 5 ) 使用稳定版本数据库避免 bug ,具体 bug 修复的版本参考文档;
( 6 ) 在 11.2.0.3 版本中, Oracle 默认启用 _use_adaptive_log_file_sync 参数,使得 LGWR 进程写日志的方式能自动在 post/wait 和 polling 两种方式之间进行取舍,可能会导致比较严重的写日志等待( log file sync 的平均单次等待时间较高) , 建议关闭此功能。
参考命令:alter system set "_use_adaptive_log_file_sync"=FALSE;
八: Log File Parallel Write
类型: 系统I/O
发生原因:
1 、 Log File Sync 是从提交开始到提交结束的时间。 Log File Parallel Write 是 LGWR 开始写 Redo File 到 Redo File 写 结束的时间。明确了这一点,可以知道,Log file sync 包含了 log file parallel write 。所以, log file sync 等待时间一出,必先看 log file parallel write 。如果 log file sync 平均等待时间(也可称为提交响应时间)为 20ms , log file parallel write 为 19ms ,那么问题就很明显了, Redo file I/O 缓慢,拖慢了提交的过程。 2 、 Log File Sync 的时间不止 log file parallel write 。服务器进程开始提交,到通知 LGWR 写 Redo , LGWR 写完 Redo 通知进程提交完毕,来回通知也是要消耗 CPU 的。除去来回通知外, Commit 还有增加 SCN 等等操作,如果 log file sync 和 log file parallel write 差距很大,证明 I/O 没有问题,但有可能是 CPU 资源紧张,导致进程和 LGWR 来回通知或其他的需要 CPU 的操作,得不到足够的 CPU ,因而产生延迟 。
优化方向 : 考 虑的是如何在单个LGWR 进程的前提下让写的日志量不超过当前的 LGWR 写能力。这个可以从两个方面来考虑 :
1 : 考虑是否在应用中产生了太多无意义的重做日志,导致日志产生量太大,从而使日志的产生量超出了LGWR 的写能力,如果是这样,那么考虑通过一些方法限制重做日志的产生。
2 : 考虑如果日志产生量确定的情况下,如何让LGWR 进程写日志能够写得更多更快,这主要取决于两个方面,一个是 LGWR 在写日志的时候是否发生了 I/O 竞争,另一方面是重做日志文件所在的磁盘速度是否过低,如果是竞争引起的,移动重做日志文件到其他的磁盘上,如果是磁盘速度引起的,那么选择高速磁盘存放重做日志。
九 :library cache lock
类型: 并发类
发生原因:
这个等待事件发生在不同用户在共享池中由于并发操作同一个数据库对象导致的资源争用的时候。比如当一个用户正在对一个表做DDL 操作时,其他的用户如果要访问这张表,就会发生 library cache lock 等待事件,它要一直等到 DDL 操作完毕后,才能继续操作。
参数含义:
Handle address : 被加载的对象的地址。
Lock address : 锁的地址。
Mode : 被加载对象的数据片段。
Namespace : 被加载对象在v$db_object_cache 视图中的 namespace 的名称。
优化方向:优化方向是查看锁定对象,减少争用。
十: SQL*Net Events
类型:
应用类:
SQL*Net break/reset to client
如果运行的代码中包含某种可能的错误,且在调用中触发了的话,服务器端本地的服务进程有义务对远程客户端告知该信息,这个告知的过程中服务进程就处于 SQL*Net break/reset to client 等待中,直到客户端收到问题信息为止。
SQL*Net break/reset to dblink
这个等待事件和SQL*Net more data to client 等待事件基本相同,只不过等待发生在分布式事务中,即本地数据库需要将更多的数据通过 dblink 发送给远程数据库。由于发送的数据太多或者网络性能问题,就会产生 SQL*Net more data to dblink 等待事件。
空闲类:
SQL*Net vector message from dblink
SQL*Net vector message from client
SQL*Net message from client
表示服务端等待着Cilent 发来请求让它处理,这时就会产生 SQL*Net message from client 等待事件。
网络类:
SQL*Net more data from dblink
SQL*Net vector data to client
SQL*Net vector data from client
SQL*Net vector data to dblink
SQL*Net vector data from dblink
SQL*Net message from dblink
SQL*Net more data from client
服务器端等待用户端发出更多的数据以便完成操作,比如一个大的SQL 文本,导致一个 SQL*Net 数据包无法完成传输,这样服务器端会等待客户端把整个 SQL 文本发过来在做处理。
SQL*Net more data to dblink
这个等待事件和SQL*Net more data to client 等待事件基本相同,只不过等待发生在分布式事务中,即本地数据库需要将更多的数据通过 dblink 发生给远程数据库。由于发送的数据太多或者网络性能问题导致的等待。
SQL*Net more data to client
这说明数据库在向客户端不停发送 太多 的数据。如果网络状况不好,或者网络流量过大,都可能导致这一等待非常显著 。
SQL*Net message to client
这个等待事件发生在服务 端 向客户端发送消息或数据的时候,一般意味着网络瓶颈或不正确的TCP 连接配置。当然它不能做为对网络延迟的准确评估或量化。
SQL*Net message to dblink
这个等待事件发生在会话在等待一个远程数据库一个确认信息,确认其发送的数据远程数据库是否收到,该数据通过dblink 发送,一般是由于目标服务器无法及时接受信息。
参考:
https://dbaplus.cn/news-10-777-1.html
http://www.itpub.net/thread-2102514-1-1.html
http://www.askmaclean.com/archives/db-file-sequential-read-wait-event.html
http://www.itpub.net/thread-1777234-1-1.html
https://www.linuxidc.com/Linux/2015-09/122732.htm
欢迎关注我的微信公众号"IT小Chen",共同学习,共同成长!!!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。






