如果你的系统需要在一张很大的表上创建一个索引,你会考虑哪些因素?
1)关于大表创建索引,如果从综合考虑多个维度来看,我会考虑:
1. 为什么需要创建索引,即索引创建的之后的性能是否能够提升
2. 创建什么样的索引,即索引的类型
3. 创建索引的影响,此时需要了解索引的创建过程,以及如果优化索引的创建效率以减少对业务的影响
4. 什么时候创建索引
5. 有没有其他方式来替代这个过程
2)以下关于几种考虑因素的分析过程: 1.为什么需要创建索引
A. 结合应用查询场景,比如是否存在相应关键业务的SQL需要使用到索引相关字段的条件,其SQL执行频繁是否较大;该部分业务SQL根据索引所返回的结果集大小,比如一个表有一个亿,每次根据相应条件返回了几千万的结果集,那创建该索引是否真正有效
B. 结合表数据分布情况,第一个是列数据选择性问题,如果选择性不高,有时索引回表的cost比全表扫描大,优化器选择执行计划路径是可能不选择索引。第二个列数据较为无序,导致创建索引后集群因子较高,增加索引回表成本等。
C. 结合表数据变化情况,,增加一个索引便需要多维护一个索引,对一张数据变化频率较高的表,索引太多会增加dml操作特别是insert时的索引维护成本,影响执行效率
2.创建什么样的索引
A.如果使用多个条件便可以创建复合索引
B.如果业务sql条件存在函数,那就要考虑函数索引
C.如果一个列基数较低,那是否考虑选择位图索引,前提是其列数据很少更新
D.分区表是否创建本地索引
3.创建索引的影响
我们都知道创建索引会与dml操作相互影响以及还有大量的IO操作等。
首先,是了解创建索引的过程,才能解决创建索引带来的问题,我做了个创建索引的实验,并通过10046追踪,创建索引的主要过程如下:
A. 开始读取数据字典如统计信息,对象信息等
B. 使用share mode nowait将表锁住,此时其他会话只可读该表但无法修改该表。
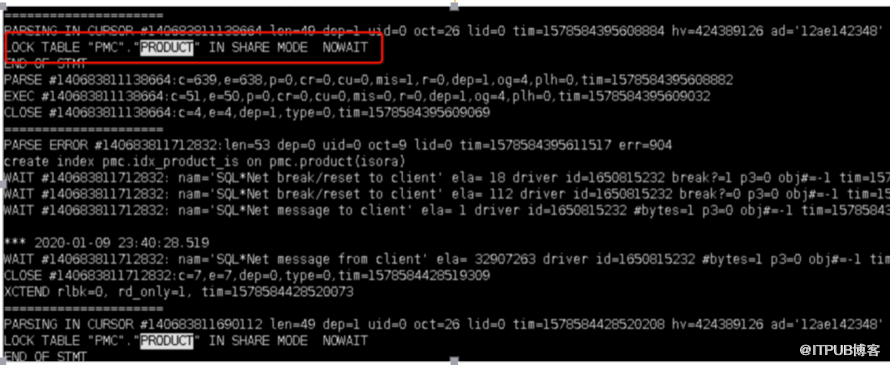
C. 读取一些信息等判断后在obj$初始化索引对象信息
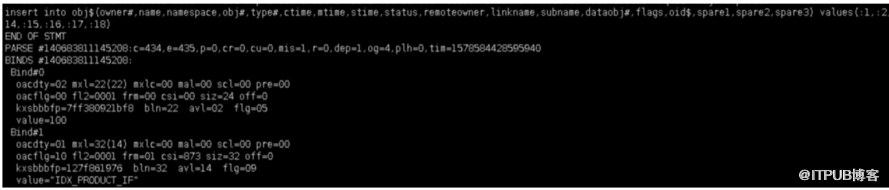
D.开始抓取表数据等一系列大量IO操作,该过程时间相对较长:
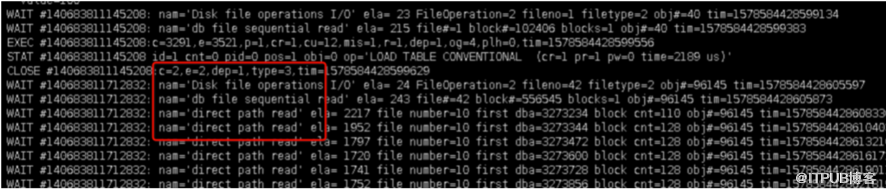
E.往seg$,icol$,ind$等信息表中插入相应信息
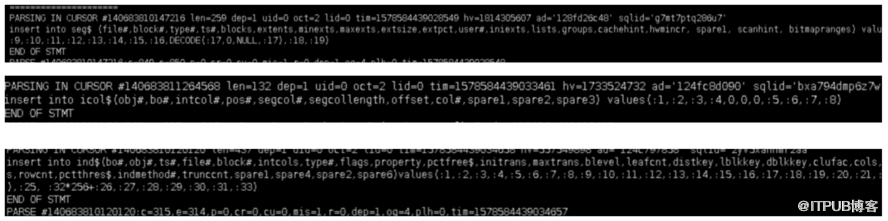
完成整个索引排序创建索引,扫描表

从以上索引的创建过程,我们可以考虑的问题点总结是:
A.此过程会加共享锁以至于阻塞dml操作,因此创建索引尽量选择业务空闲期进行,同时也可以考虑online方式创建。
B.此过程需要大量读取表数据并排序操作,以及insert update操作,此时需要考虑存储IO性能
C.此过程会产生大量redo,可以考虑nologing模式
D.同时需要考虑索引的空间大小,关注表空间和临时表空间
E.同时可以使用并行加快操作,这也是我们常做的。
4. 什么时候创建索引
不用考虑,业务空闲期
5. 有没有其他方式来替代这个过程
可以考虑数据迁移方式,创建一张新表添加索引,在线迁入数据后 rename表
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





