这篇文章将为大家详细讲解有关MySQL中数据源管理和关系型分库分表以及列式库分布式计算分别指的是什么,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
随着业务发展,数据量的越来越大,业务系统越来越复杂,拆分的概念逻辑就应运而生。数据层面的拆分,主要解决部分表数据过大,导致处理时间过长,长期占用链接,甚至出现大量磁盘IO问题,严重影响性能;业务层面拆分,主要解决复杂的业务逻辑,业务间耦合度过高,容易引起雪崩效应,业务库拆分,微服务化分布式,也是当前架构的主流方向。
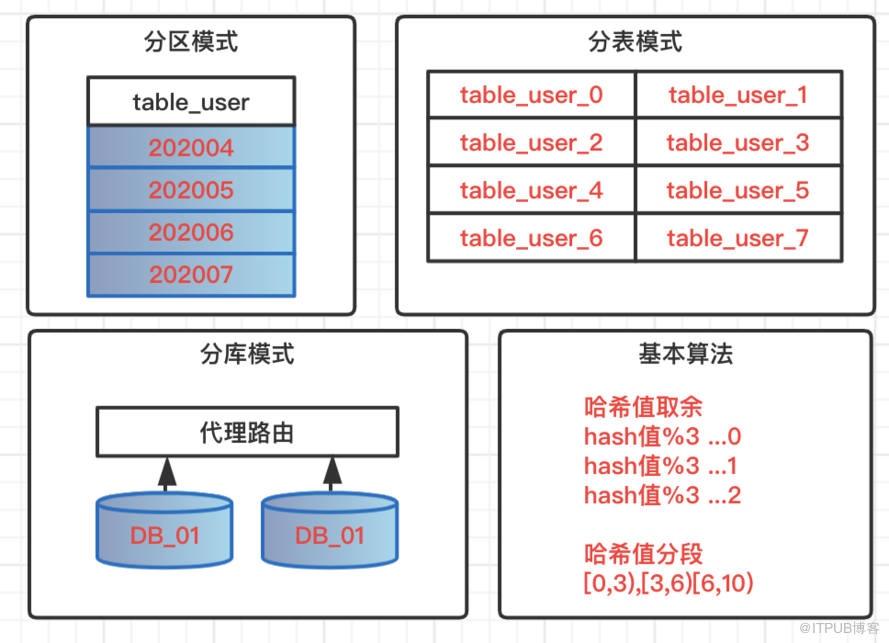
分区模式
针对数据表做分区模式,所有数据,逻辑上还存在一张表中,但是物理堆放不在一起,会根据一定的规则堆放在不同的文件中。查询数据的时候必须按照指定规则触发分区,才不会全表扫描。不可控因素过多,风险过大,一般开发规则中都是禁止使用表分区。
分表模式
单表数据量过大,一般情况下单表数据控制在300万,这里的常规情况是指字段个数,类型都不是极端类型,查询也不存在大量锁表的操作。超过该量级,这时候就需要分表操作,基于特定策略,把数据路由到不同表中,表结构相同,表名遵循路由规则。
分库模式
在系统不断升级,复杂化场景下,业务不好管理,个别数据量大业务影响整体性能,这时候可以考虑业务分库,大数据量场景分库分表,减少业务间耦合度,高并发大数据的资源占用情况,实现数据库层面的解耦。在架构层面也可以服务化管理,保证服务的高可用和高性能。
常用算法
哈希值取余:根据路由key的哈希值余数,把数据分布到不同库,不同表;
哈希值分段:根据路由key的哈希值分段区间,实现数据动态分布;
这两种方式在常规下都没有问题,但是一旦分库分表情况下数据库再次饱和,需要迁移,这时候影响是较大的。
基于一个代理层(这里使用Sharding-Jdbc中间件),指定分库策略,根据路由结果,找到不同的数据库,执行数据相关操作。
把需要分库的数据源统一管理起来。
@Configuration
public class DataSourceConfig {
// 省略数据源相关配置
/**
* 分库配置
*/
@Bean
public DataSource dataSource (@Autowired DruidDataSource dataZeroSource,
@Autowired DruidDataSource dataOneSource,
@Autowired DruidDataSource dataTwoSource) throws Exception {
ShardingRuleConfiguration shardJdbcConfig = new ShardingRuleConfiguration();
shardJdbcConfig.getTableRuleConfigs().add(getUserTableRule());
shardJdbcConfig.setDefaultDataSourceName("ds_0");
Map<String,DataSource> dataMap = new LinkedHashMap<>() ;
dataMap.put("ds_0",dataZeroSource) ;
dataMap.put("ds_1",dataOneSource) ;
dataMap.put("ds_2",dataTwoSource) ;
Properties prop = new Properties();
return ShardingDataSourceFactory.createDataSource(dataMap, shardJdbcConfig, new HashMap<>(), prop);
}
/**
* 分表配置
*/
private static TableRuleConfiguration getUserTableRule () {
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("user_info");
result.setActualDataNodes("ds_${1..2}.user_info_${0..2}");
result.setDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_phone", new DataSourceAlg()));
result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_phone", new TableSignAlg()));
return result;
}
}路由到库
根据分库策略的值,基于hash算法,判断路由到哪个库。has算法不同,不但影响库的操作,还会影响数据入表的规则,比如偶数和奇数,导致入表的奇偶性。
public class DataSourceAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(DataSourceAlg.class);
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
String dataName = "ds_" + ((hash % 2) + 1) ;
LOG.debug("分库算法信息:{},{},{}",names,value,dataName);
return dataName ;
}
}路由到表
根据分表策略的配置,基于hash算法,判断路由到哪张表。
public class TableSignAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(TableSignAlg.class);
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
String tableName = "user_info_" + (hash % 3) ;
LOG.debug("分表算法信息:{},{},{}",names,value,tableName);
return tableName ;
}
}上述就是基于ShardingJdbc分库分表的核心操作流程。
在相对庞大的数据分析时,通常会选择生成一张大宽表,并且存放到列式数据库中,为了保证高效率执行,可能会把数据分到不同的库和表中,结构一样,基于多线程去统计不同的表,然后合并统计结果。
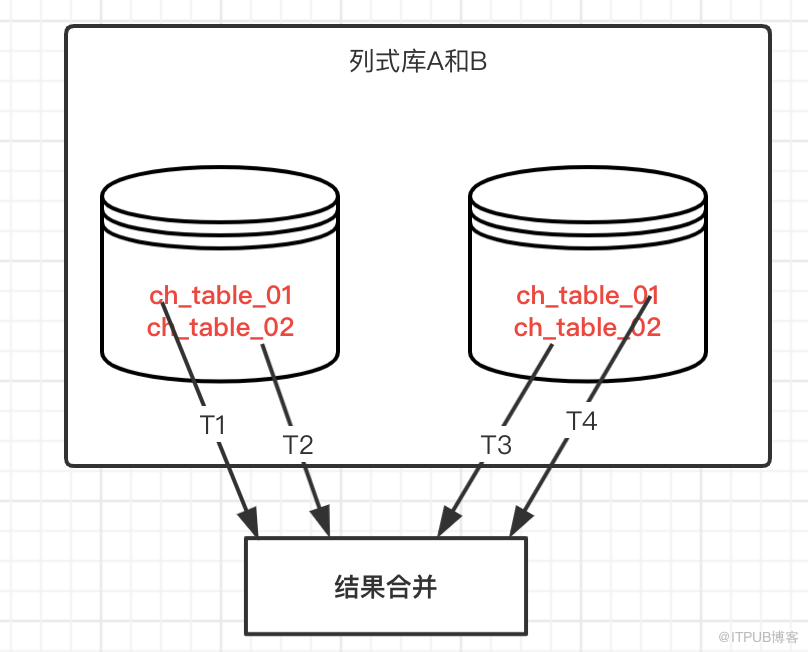
基本原理:多线程并发去执行不同的表的统计,然后汇总统计,相对而言统计操作不难,但是需要适配不同类型的统计,比如百分比,总数,分组等,编码逻辑相对要求较高。
基于ClickHouse数据源,演示案例操作的基本逻辑。这里管理和配置库表。
核心配置文件
spring: datasource: type: com.alibaba.druid.pool.DruidDataSource # ClickHouse数据01 ch-data01: driverClassName: ru.yandex.clickhouse.ClickHouseDriver url: jdbc:clickhouse://127.0.0.1:8123/query_data01 tables: ch_table_01,ch_table_02 # ClickHouse数据02 ch-data02: driverClassName: ru.yandex.clickhouse.ClickHouseDriver url: jdbc:clickhouse://127.0.0.1:8123/query_data02 tables: ch_table_01,ch_table_02
核心配置类
@Component
public class ChSourceConfig {
public volatile Map<String, String[]> chSourceMap = new HashMap<>();
public volatile Map<String, Connection> connectionMap = new HashMap<>();
@Value("${spring.datasource.ch-data01.url}")
private String dbUrl01;
@Value("${spring.datasource.ch-data01.tables}")
private String tables01 ;
@Value("${spring.datasource.ch-data02.url}")
private String dbUrl02;
@Value("${spring.datasource.ch-data02.tables}")
private String tables02 ;
@PostConstruct
public void init (){
try{
Connection connection01 = getConnection(dbUrl01);
if (connection01 != null){
chSourceMap.put(connection01.getCatalog(),tables01.split(","));
connectionMap.put(connection01.getCatalog(),connection01);
}
Connection connection02 = getConnection(dbUrl02);
if (connection02 != null){
chSourceMap.put(connection02.getCatalog(),tables02.split(","));
connectionMap.put(connection02.getCatalog(),connection02);
}
} catch (Exception e){e.printStackTrace();}
}
private synchronized Connection getConnection (String jdbcUrl) {
try {
DriverManager.setLoginTimeout(10);
return DriverManager.getConnection(jdbcUrl);
} catch (Exception e) {
e.printStackTrace();
}
return null ;
}
}既然基于多线程统计,自然需要一个线程任务类,这里演示count统计模式。输出单个线程统计结果。
public class CountTask implements Callable<Integer> {
private Connection connection ;
private String[] tableArray ;
public CountTask(Connection connection, String[] tableArray) {
this.connection = connection;
this.tableArray = tableArray;
}
@Override
public Integer call() throws Exception {
Integer taskRes = 0 ;
if (connection != null){
Statement stmt = connection.createStatement();
if (tableArray.length>0){
for (String table:tableArray){
String sql = "SELECT COUNT(*) AS countRes FROM "+table ;
ResultSet resultSet = stmt.executeQuery(sql) ;
if (resultSet.next()){
Integer countRes = resultSet.getInt("countRes") ;
taskRes = taskRes + countRes ;
}
}
}
}
return taskRes ;
}
}这里主要启动线程的执行,和最后把每个线程的处理结果进行汇总。
@RestController
public class ChSourceController {
@Resource
private ChSourceConfig chSourceConfig ;
@GetMapping("/countTable")
public String countTable (){
Set<String> keys = chSourceConfig.chSourceMap.keySet() ;
if (keys.size() > 0){
ExecutorService executor = Executors.newFixedThreadPool(keys.size());
List<CountTask> countTasks = new ArrayList<>() ;
for (String key:keys){
Connection connection = chSourceConfig.connectionMap.get(key) ;
String[] tables = chSourceConfig.chSourceMap.get(key) ;
CountTask countTask = new CountTask(connection,tables) ;
countTasks.add(countTask) ;
}
List<Future<Integer>> countList = Lists.newArrayList();
try {
if (countTasks.size() > 0){
countList = executor.invokeAll(countTasks) ;
}
} catch (InterruptedException e) {
e.printStackTrace();
}
Integer sumCount = 0 ;
for (Future<Integer> count : countList){
try {
Integer countRes = count.get();
sumCount = sumCount + countRes ;
} catch (Exception e) {e.printStackTrace();}
}
return "sumCount="+sumCount ;
}
return "No Result" ;
}
}关系型分库,还是列式统计,都是基于特定策略把数据分开,然后路由找到数据,执行操作,或者合并数据,或者直接返回数据。
GitHub·地址 https://github.com/cicadasmile/data-manage-parent GitEE·地址 https://gitee.com/cicadasmile/data-manage-parent
推荐阅读:数据管理
| 序号 | 标题 |
|---|---|
| 01 | 数据源管理:主从库动态路由,AOP模式读写分离 |
| 02 | 数据源管理:基于JDBC模式,适配和管理动态数据源 |
| 03 | 数据源管理:动态权限校验,表结构和数据迁移流程 |
关于MySQL中数据源管理和关系型分库分表以及列式库分布式计算分别指的是什么就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





