如何理解gh-ost,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
公司内部一直使用的online ddl工具是pt-online-schema-change,今天准备尝试一下另外一个工具gh-ost。
gh-ost 是 gitHub,s Online Schema Transmogrifier/Transfigurator/Transformer/Thingy 的缩写,意思是 GitHub 的在线表定义转换器。
我对gh-ost的感兴趣的原因是gh-ost可随时暂停。如果变更过程发现主库性能受影响,可以立刻停止拉binlog,停止应用 binlog,停止移动行数据,等性能稳定之后再继续;另外,gh-ost不依赖触发器,这是和pt-osc的最大区别。
只以主库模式介绍:
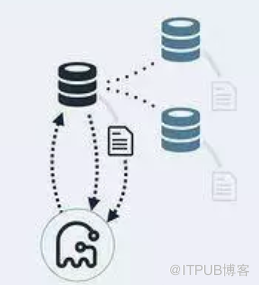
1、 gh-ost 首先连接到主库上,根据 alter 语句创建幽灵表_tablename_gho;
2、 然后gh-ost作为一个备库连接到主库上,一边在主库上拷贝已有的数据到幽灵表,
一边从主库上拉取增量数据的 binlog,然后不断的把 binlog 应用回主库幽灵表;
3、 等待全部数据同步完成,进行cut-over,即进行幽灵表和原表切换。cut-over是最后一步,
锁住主库的源表,等待binlog应用完毕,然后替换gh-ost幽灵表为源表。gh-ost在执行中,
会在原本的binlog event里面增加hint和心跳包,用来控制整个流程的进度,检测状态等。从 github 发布地址下载最新的 binary 包:https://github.com/github/gh-ost/releases
解压后就一个 gh-ost 二进制文件。
tar -xvf gh-ost-binary-linux-20190214020851.tar.gz
cp gh-ost /usr/bin只以主库模式介绍,上生产可以直接用:
gh-ost \
--max-load=Threads_running=50 \
--critical-load=Threads_running=80 \
--critical-load-interval-millis=5000 \
--max-lag-millis=1500 \
--chunk-size=1000 \
--ok-to-drop-table \
--initially-drop-ghost-table \
--initially-drop-socket-file \
--host=172.18.6.2 \
--port=3306 \
--user="chenzhixin" \
--password="123456"\
--database="test" \
--table="user100w" \
--verbose \
--alter="add column test_field6 varchar(256) default '';" \
--cut-over-lock-timeout-seconds=1 \
--dml-batch-size=10 \
--exact-rowcount \
--serve-socket-file=/tmp/ghost.sock \
--panic-flag-file=/tmp/ghost.panic.flag \
--allow-on-master \
--execute
########## 特别提醒!!!!!!############################
下面这个参数有需要再加,加了它就不会自动切换源表和幽灵表,需要手工删除/tmp/ghost.postpone.flag
文件后,才会发生自动切换,请理解该参数含义。
--postpone-cut-over-flag-file=/tmp/ghost.postpone.flag操作过程中会生成两个中间状态的表 _tablename_ghc和_tablename_gho,其中 _tablename_ghc 是记录gh-ost 执行过程的表,_tablename_gho 是目标表,也即应用ddl语句的幽灵表_tablename_gho。
执行上述的gh-ost命令过程中,会看到如下的_user100w_ghc的执行过程表,和_user100w_gho幽灵表、
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| _user100w_ghc |
| _user100w_gho |
| fruits |
| test_timestamp |
| user100w |
+----------------+
5 rows in set (0.00 sec)解释:
--max-load=Threads_running=50
表面如果在执行gh-ost的过程中出现Threads_running=50则暂停gh-ost的执行
--critical-load=Threads_running=80
表明执行过程中出现Threads_running达到80则终止gh-ost的执行
--critical-load-interval-millis 当值为0时,当达到-critical-load,gh-ost立即退出。当值不为0时,当达到-critical-load,gh-ost会在-critical-load-interval-millis秒数后,再次进行检查,再次检查依旧达到-critical-load,gh-ost将会退出
--max-lag-millis
会监控从库的主从延迟情况,如果延迟秒数超过这个阀值,row copy不会退出,等待延迟秒数低于这个阀值继续迁移。
--ok-to-drop-table
go-ost 执行完以后是否删除老表,加上此参数会自动删除老表。默认不删除老表,会存在_tablename_del表
--initially-drop-ghost-table
gh-ost 执行前会创建两张 xx_ghc 和 xx_gho 表,如果这两张表存在,且加上了这个参数,那么会自动删除原 gh 表,从新创建,否则退出。xx_gho 表相当于老表的全量备份,xx_ghc 表数据是数据更改日志,理解成增量备份。
--initially-drop-socket-file
gh-ost 执行时会创建 socket 文件,退出时不会删除,下次执行 gh-ost 时会报错,加上这个参数会删除老的 socket 文件,重新创建。
--throttle-flag-file
此文件存在时操作暂停,删除文件操作会继续。
--verbose
执行过程输出日志
--chunk-size
迁移过程是一步步分批次完成的,这个参数是指事务每次提交的行数,默认是 1000。
--max-lag-millis
会监控从库的主从延迟情况,如果延迟秒数超过这个阀值,迁移不会退出,等待延迟秒数低于这个阀值继续迁移。
--max-lag-millis
会监控从库的主从延迟情况,如果延迟秒数超过这个阀值,迁移不会退出,等待延迟秒数低于这个阀值继续迁移
--throttle-control-replica
和--max-lag-millis 参数相结合,这个参数指定主从延迟的数据库实例。
--cut-over-lock-timeout-seconds
gh-ost在cut-over阶段最大的锁等待时间,当锁超时时,gh-ost的cut-over将重试。(默认值:3)
--allow-on-master
整个迁移所有操作在主库上执行
--dml-batch-size
在单个事务中应用DML事件的批量大小(范围1-100)(默认值为10)
--exact-rowcount
准确统计表行数(使用select count(*)的方式),得到更准确的预估时间。
--postpone-cut-over-flag-file
当这个文件存在的时候,gh-ost的cut-over阶段将会被推迟,数据仍然在复制,直到该文件被删除。
--throttle-flag-file string
当该文件被创建后,gh-ost操作立即停止。该参数适合控制单个gh-ost操作。-throttle-additional-flag-file string适合控制多个gh-ost操作。 执行gh-ost中,会有输出信息,具体解释如下:
Copy: 27000/58707 46.0%;58707指需要迁移总行数,27000指已经迁移的行数,46%指迁移完成的百分比。
Applied: 0,指在二进制日志中处理的event数量。在上面的例子中,迁移表没有流量,因此没有被处理日志event。
Backlog: 0/1000,表示我们在读取二进制日志方面表现良好,在二进制日志队列中没有任何积压(Backlog)事件。
Backlog: 7/1000,当复制行时,在二进制日志中积压了一些事件,并且需要应用。
Backlog: 1000/1000,表示我们的1000个事件的缓冲区已满(程序写死的1000个事件缓冲区,低版本是100个),此时就注意binlog写入量非常大,gh-ost处理不过来event了,可能需要暂停binlog读取,需要优先应用缓冲区的事件。
streamer: shvm-5-39.000040:338912890;表示当前已经应用到binlog文件位置#首先要安装socat工具
yum install socat -y
注意:上面gh-ost里面配置的--serve-socket-file=/tmp/ghost.sock,下面就用到了。
gh-ost 可以通过 unix socket 文件的方式来监听请求,DBA 可以在gh-ost命令运行后更改相应的参数进行限流操作等。
#暂停
echo throttle | socat - /tmp/ghost.sock#恢复
echo no-throttle | socat - /tmp/ghost.sock#终止
对应panic-flag-file参数文件,当tmp目录存在该文件立即停止
touch /tmp/ghost.panic.flag#延迟切换(cut-over阶段)
--postpone-cut-over-flag-file=/tmp/ghost.postpone.flag
当设置该参数时cut-over一直延迟源表和幽灵表的切换,直到你删除该文件才进行切换。适用场景:
你发起了一次修改操作,然后估计完成时间是凌晨 2 点钟,可是你又非常关心最后的切换操作,
非常想看着它切换,这可怎么办?只需要一个标志位文件就可以告诉 gh-ost 推迟切换了,
这样 gh-ost 会只做完拷贝数据的操作,但不会切换表。它还会仍然继续同步数据,
保持幽灵表的数据处于同步状态。等第二天早上你回到办公室之后,
删除标志位文件或者向gh-ost发送命令echo unpostpone,它就会做切换了。
我们不希望软件强迫我们看着它做事情,它应该把我们解放出来,让人去做人该做的事。#在线修改限速参数
echo max-load=Threads_connected=200 | socat - /tmp/ghost.sock
echo max-load=Thread_running=3 | socat - /tmp/ghost.sock
echo chunk-size=100 | socat - /tmp/ghost.sock
echo max-lag-millis=200 | socat - /tmp/ghost.sock适用场景:
当你执行了 gh-ost 之后,也许你会看见主库的负载变高了,那你可以发出暂停命令。
用 echo throttle 命令生成一个文件,看看主库的负载会不会又变得正常。试一下这些命令,
你就可以知道你可以怎样控制它的行为,你的心里就会安定许多。 凡事有利必有弊,人不可能把所有好事都占有,下面是gh-ost的几个限制:
1、不支持没有主键或者唯一索引的表
2、不支持有外键约束的表(主表和子表都不支持)
3、不支持表上有触发器
5、表上存在大量写入的时候,gh-ost可能永远也完成不了
经过测试:当写入QPS 5000以上,gh-ost无法完成任务,其原因是apply binlog是单线程,可以理解为slave,当原表写入量巨大时(QPS=5000以上),一直在应用日志,而gh-ost设计是binlog应用优先级高于row copy,所以我们看到row copy进度一直没变,这样如果原表一直压力这么大,那么gh-ost DDL将无法完成。经过在s3710机器上测试如果原表写入的QPS大于5000将大概率出现此情况,小于5000的话没问题。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/28916011/viewspace-2670103/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



