elcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 34
Server version: 8.0.17 Source distribution
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.Server version: 8.0.17 Source distribution
编译安装脚本
yum -y install gcc gcc-c++ ncurses-devel libtirpc-devel libaio-devel openssl openssl-devel
增加mysql用户
groupadd -g 1101 mysql ; useradd -u 1101 -g mysql mysql ;
mkdir -p /opt/mysql
mkdir -p /data/mysqldata
mkdir -p /log/mysql
chown -R mysql.mysql /opt/mysql
chown -R mysql.mysql /data/mysqldata
chown -R mysql.mysql /log/mysql
下载mysql和rpcsvc
cd /tmp
wget https://github.com/thkukuk/rpcsvc-proto/releases/download/v1.4/rpcsvc-proto-1.4.tar.gz
tar zxvf rpcsvc-proto-1.4.tar.gz
cd rpcsvc-proto-1.4
./configure
make
make install
cd /tmp
wget https://cdn.mysql.com//Downloads/MySQL-8.0/mysql-boost-8.0.17.tar.gz
安装mysql
tar zxvf mysql-boost-8.0.17.tar.gz
cd mysql-8.0.17
cmake -DCMAKE_INSTALL_PREFIX=/opt/mysql \
-DINSTALL_PLUGINDIR=/opt/mysql/lib/plugin \
-DMYSQL_DATADIR=/data/mysqldata \
-DWITH_MYISAM_STORAGE_ENGINE=1 \
-DWITH_INNOBASE_STORAGE_ENGINE=1 \
-DDEFAULT_CHARSET=utf8mb4 \
-DDEFAULT_COLLATION=utf8mb4_general_ci \
-DBUILD_CONFIG=mysql_release \
-DWITH_SSL=system \
-DWITH_ZLIB=system \
-DCMAKE_BUILD_TYPE=RelWithDebInfo \
-DWITH_BOOST=/tmp/mysql-8.0.17/boost/boost_1_69_0 \
-DFORCE_INSOURCE_BUILD=1
make -j 4
make install
设置配置文件
mkdir -p /opt/mysql/etc
cat >/opt/mysql/etc/my.cnf <<EOF
[client]
port = 3306
socket = /data/mysqldata/mysql.sock
[mysqld]
port = 3306
socket = /data/mysqldata/mysql.sock
datadir=/data/mysqldata/
basedir=/opt/mysql
mysqlx=0
#innodb
innodb_data_home_dir = /data/mysqldata
innodb_data_file_path = ibdata1:128M:autoextend
innodb_buffer_pool_size = 1000M
innodb_buffer_pool_instances=1
innodb_file_per_table=on
#innodb log
innodb_log_group_home_dir = /data/mysqldata
innodb_log_file_size = 256M
innodb_log_buffer_size = 64M
innodb_log_files_in_group=4
#innodb zero data lost variables
innodb_flush_log_at_trx_commit = 1
innodb_doublewrite=on
sync_binlog=1
master-info-repository=table
relay-log-info-repository=table
#tx commit action is heavy action
autocommit=on
transaction_isolation=READ-COMMITTED
lower_case_table_names=1
bind-address = 0.0.0.0
#character
init_connect = 'SET NAMES utf8mb4'
character_set_server=utf8mb4
#collation_server=utf8mb4_general_ci
open_files_limit = 65535
#gtid
server_id=791
gtid_mode=on
enforce_gtid_consistency=on
master_info_repository=table
relay_log_info_repository=table
#connect
max_connections = 2000
max_connect_errors=9999999
#sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
#memory
#query_cache_size = 0M
#query_cache_type=0
#mysql log
binlog_format=row
log_bin = binlog
log_timestamps=system
log_output='file,table'
log_error=/log/mysql/error.log
general_log=off
general_log_file=/log/mysql/general_.log
relay_log = /log/mysql/mysql-relay-bin.log
relay_log_purge =off
max_binlog_size = 256M
log_slave_updates=on
binlog_expire_logs_seconds = 604800
slow_query_log_file=/log/mysql/slow.log
slow_query_log=on
long_query_time=1
skip_name_resolve=on
#slave
#skip_slave_start
slave-skip-errors=1062
replicate_ignore_db=mysql
replicate_wild_ignore_table=mysql.%
#resource
max_allowed_packet = 128M
innodb_lock_wait_timeout = 50
#use audit
binlog_rows_query_log_events=on
EOF
修改目录权限和初始化mysql
chown -R mysql.mysql /opt/mysql
chown -R mysql.mysql /data/mysqldata
chown -R mysql.mysql /log/mysql
/opt/mysql/bin/mysqld --defaults-file=/opt/mysql/etc/my.cnf --initialize --user=mysql
将mysql设置为开机自动启动
cp /opt/mysql/support-files/mysql.server /etc/init.d/mysqld
chmod +x /etc/init.d/mysqld
systemctl enable mysqld.service
#chkconfig --add mysqld
重启mysql
systemctl restart mysqld.service使用了mysql的分区,觉得最不爽的是mysql partition 限制:
A UNIQUE INDEX must include all columns in the table's partitioning function
A PRIMARY KEY must include all columns in the table's partitioning function
意思就是:用于分区的column 必须是主键列,或者主键的其中几个列,或者是唯一键列。无论创建何种类型的分区,如果表中存在主键或唯一索引时,分区列必须是唯一索引的一个组成部分。也不清楚作者这样设计的初衷是什么。比如以下的写法就是有语法错误:
CREATE TABLE t1 (
col1 INT NOT NULL,
col2 DATE NOT NULL,
col3 INT NOT NULL,
col4 INT NOT NULL,
UNIQUE KEY (col1, col2)
)
PARTITION BY HASH(col3)
PARTITIONS 4;
CREATE TABLE t2 (
col1 INT NOT NULL,
col2 DATE NOT NULL,
col3 INT NOT NULL,
col4 INT NOT NULL,
UNIQUE KEY (col1),
UNIQUE KEY (col3)
)
PARTITION BY HASH(col1 + col3)
PARTITIONS 4;这样会大大限制mysql分区使用范围。
1.range 分区,频繁使用。 基于属于一个给定连续区间的列值,把多行分配给分区。
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN (21)
);2. list 分区,比较少使用。类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LIST(store_id) (
PARTITION pNorth VALUES IN (3,5,6,9,17),
PARTITION pEast VALUES IN (1,2,10,11,19,20),
PARTITION pWest VALUES IN (4,12,13,14,18),
PARTITION pCentral VALUES IN (7,8,15,16)
);注意看上面,都是没有主键,没有唯一键的。
3.HASH分区,频繁使用:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY HASH( YEAR(hired) )
PARTITIONS 4;4.KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
CREATE TABLE k1 (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(20)
)
PARTITION BY KEY()
PARTITIONS 2;
CREATE TABLE k1 (
id INT NOT NULL,
name VARCHAR(20),
UNIQUE KEY (id)
)PARTITION BY KEY()
PARTITIONS 2;上面两个例子你会觉得很奇怪,都没有指定分区列。mysql默认就使用了唯一键来做了分区。
1)当数据量很大(过T)时,肯定不能把数据再如到内存中,这样查询一个或一定范围的item是很耗时。另外一般这情况下,历史数据或不常访问的数据占很大部分,最新或热点数据占的比例不是很大。这时可以根据有些条件进行表分区。
2)分区表的更易管理,比如删除过去某一时间的历史数据,直接执行truncate,或者狠点drop整个分区,这比detele删除效率更高
3)当数据量很大,或者将来很大的,但单块磁盘的容量不够,或者想提升IO效率的时候,可以把没分区中的子分区挂载到不同的磁盘上。
4)使用分区表可避免某些特殊的瓶颈,例如Innodb的单个索引的互斥访问..
5)单个分区表的备份很恢复会更有效率,在某些场景下
6)涉及到例如SUM()和COUNT()这样聚合函数的查询,可以很容易地进行并行处理。
这种查询的一个简单例子如
“SELECT salesperson_id, COUNT (orders) as order_total FROM sales GROUP BY salesperson_id;”。
通过“并行”,这意味着该查询可以在每个分区上同时进行,最终结果只需通过总计所有分区得到的结果。
表分区了,查询where必须带上分区键,否则使用不到分区的好处了。我们来看下例子:
CREATE TABLE part_tab
(c1 int default NULL, c2 varchar(30) default NULL, c3 date not null)
PARTITION BY RANGE(year(c3))
(PARTITION p0 VALUES LESS THAN (1995),
PARTITION p1 VALUES LESS THAN (1996) ,
PARTITION p2 VALUES LESS THAN (1997) ,
PARTITION p3 VALUES LESS THAN (1998) ,
PARTITION p4 VALUES LESS THAN (1999) ,
PARTITION p5 VALUES LESS THAN (2000) ,
PARTITION p6 VALUES LESS THAN (2001) ,
PARTITION p7 VALUES LESS THAN (2002) ,
PARTITION p8 VALUES LESS THAN (2003) ,
PARTITION p9 VALUES LESS THAN (2004) ,
PARTITION p10 VALUES LESS THAN (2010),
PARTITION p11 VALUES LESS THAN (MAXVALUE) );
CREATE TABLE no_part_tab(c1 int default NULL, c2 varchar(30) default NULL, c3 date not null);
drop procedure load_part_tab;
delimiter $$
CREATE PROCEDURE load_part_tab()
begin
declare v int default 0;
while v < 8000000
do
insert into part_tab
values (v,'testingpartitions',adddate('1995-01-01',(rand(v)*36520)mod 3652));
set v = v + 1;
end while;
end;$$
delimiter ;
call load_part_tab();
//从 part_tab 导入数据到 no_part_tab
insert into no_part_tab select * from part_tab;创建了2个表,数据都是800万。
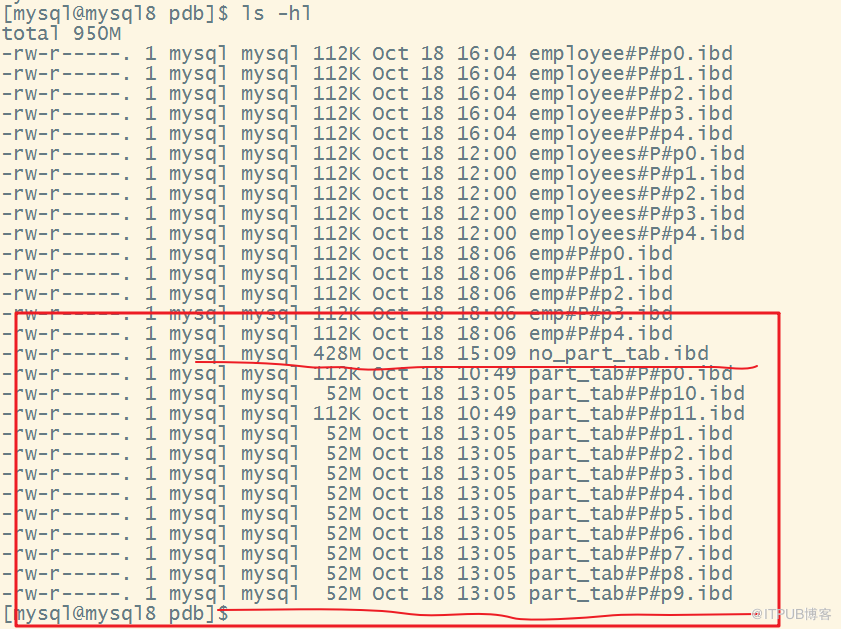
一个表no_part_tab的大小是428M。在这里另外
mysql> explain select count(*) from part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | part_tab | p1 | ALL | NULL | NULL | NULL | NULL | 796215 | 11.11 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select count(*) from no_part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
+----+-------------+-------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | no_part_tab | NULL | ALL | NULL | NULL | NULL | NULL | 7773613 | 11.11 | Using where |
+----+-------------+-------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
mysql> select count(*) from part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
+----------+
| count(*) |
+----------+
| 795181 |
+----------+
1 row in set (0.39 sec)
mysql> select count(*) from no_part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
+----------+
| count(*) |
+----------+
| 795181 |
+----------+
1 row in set (2.94 sec)查询时间和扫描的行数,高下可判。
| 序号 | 常见操作 | 举例 | 备注 |
| 1 | 删除分区 | 1) aher table emp drop partition p1;
2) 一次性删除各个区:alter table emp drop partition p1,p2; 3) 删除表的所有分区:Alter table emp remove partitioning; |
1)不可以删除hash或者kev分区。
2)删除分区会删除数据,但是删除表的所有分区--不会丢失数据(验证ok) |
| 2 | 增加分区 | alter table emp add partition (partition p1 values less than (24));
alter table emp add partition partition p3 values in (40)); |
1)增加分区的值只能增加,不能比现在所拥有的分区值低 |
| 3 | 分解分区 | alter table emp reorganize partition p2 into
(partition p1 values less than (6), partition p2 values less than (16)); |
reorganize partition关键字可以对表的部分分区或全部分区进行修
改,并且不会丢失数据。分解前后分区的整体范围应该一致。 |
| 4 | 合并分区 | alter table emp reorganize partition p1,p3 into (partition p1 values less than (1000)); | 不会丢失数据 |
| 5 | 重新定义分区 | 重新定义Hash分区:Alter table emp partition by hash(salary) partitions 7;
重新定义Range分区: Alter table emp partition by range(id) (partition p1 values less than (2000), partition p2 values less than (4000)); |
相当于删除重建。 |

亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/30393770/viewspace-2660571/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



