这是一种将海量的数据水平扩展的数据库集群系统数据分表存储在sharding 的各个节点
上使用者通过简单的配置就可以很方便地构建一个分布式MongoDB 集群。
MongoDB 的数据分块称为 chunk。每个 chunk 都是 Collection 中一段连续的数据记录通
常最大尺寸是 200MB超出则生成新的数据块。
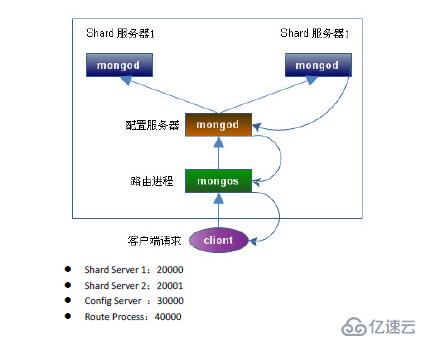
要构建一个 MongoDB Sharding Cluster需要三种角色
1、 Shard Server
即存储实际数据的分片每个Shard 可以是一个mongod 实例也可以是一组mongod 实例
构成的Replica Set。为了实现每个Shard 内部的auto-failoverMongoDB 官方建议每个Shard
为一组Replica Set。
2、 Config Server
为了将一个特定的collection 存储在多个shard 中需要为该collection 指定一个shard key
例如{age: 1} shard key 可以决定该条记录属于哪个chunk。Config Servers 就是用来存储
所有shard 节点的配置信息、每个chunk 的shard key 范围、chunk 在各shard 的分布情况、
该集群中所有DB 和collection 的sharding 配置信息。
3、Route Process
这是一个前端路由客户端由此接入然后询问Config Servers 需要到哪个Shard 上查询或
保存记录再连接相应的Shard 进行操作最后将结果返回给客户端。客户端只需要将原本
发给mongod 的查询或更新请求原封不动地发给Routing Process而不必关心所操作的记录
存储在哪个Shard 上。
下面我们在同一台物理机器上构建一个简单的 Sharding Cluster
架构图如下
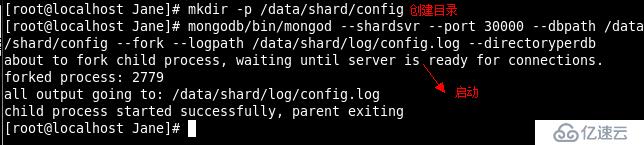
创建数据目录和日志目录

启动Shard Server 实例1和实例2


启动Config Server
启动Route Process
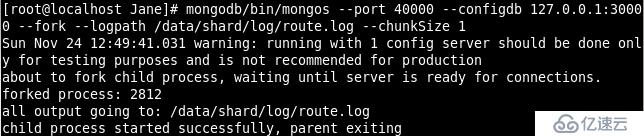
mongos 启动参数中chunkSize 这一项是用来指定chunk 的大小的单位是MB默认大小
为200MB为了方便测试Sharding 效果我们把chunkSize 指定为 1MB。
配置Sharding
接下来我们使用MongoDB Shell 登录到mongos添加Shard 节点
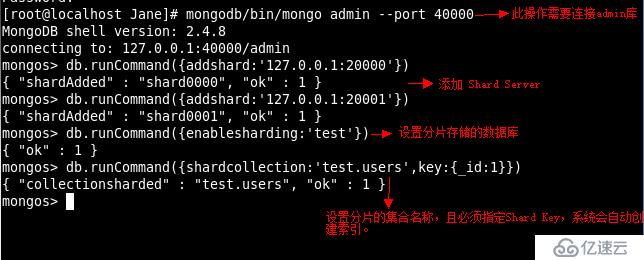
验证Sharding正常工作
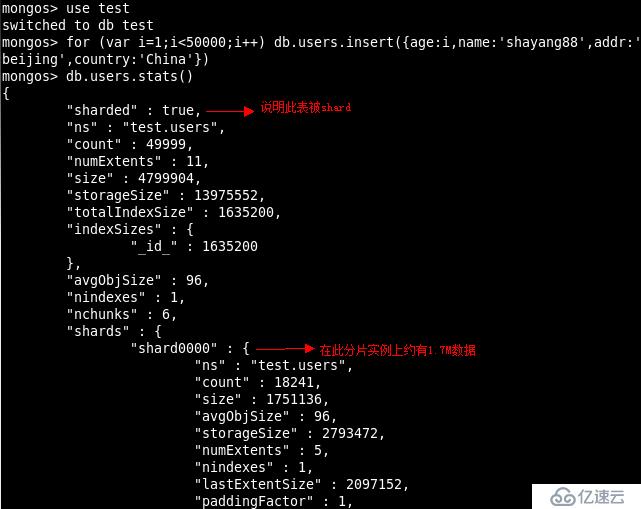
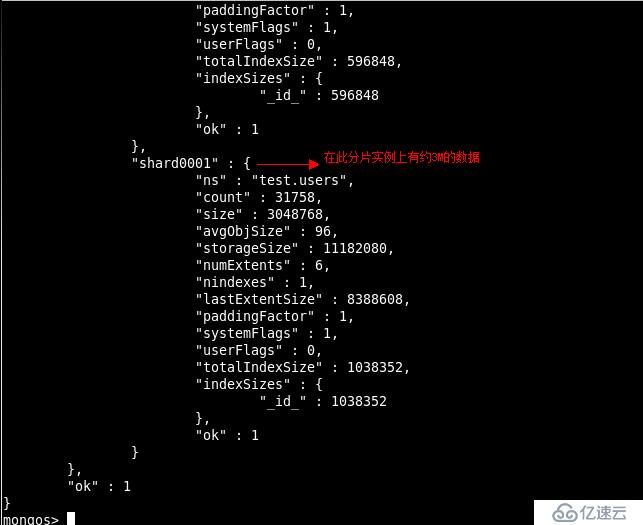
我们已经对test.users 表进行了分片的设置下面我们们插入一些数据看一下结果
我们看一下磁盘上的物理文件情况
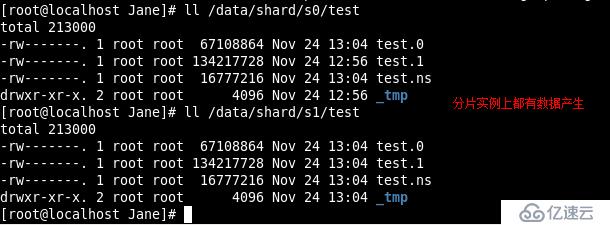
看上述结果表明test.users 集合已经被分片处理了但是通过mongos 路由我们并感觉
不到是数据存放在哪个shard 的chunk 上的这就是MongoDB 用户体验上的一个优势即
对用户是透明的。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



