本篇文章为大家展示了MySQL MHA集群方案是怎样的,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
MySQL MHA集群方案调研
MHA是由日本Mysql专家用Perl写的一套Mysql故障切换方案以保障数据库的高可用性,它的功能是能在0-30s之内实现主Mysql故障转移(failover),
MHA故障转移可以很好的帮我们解决从库数据的一致性问题,同时最大化挽回故障发生后的数据。MHA里有两个角色一个是node节点 一个是manager节点,要实现这个MHA,必须最少要三台数据库服务器,一主多备,即一台充当master,一台充当master的备份机,另外一台是从属机。
官方资料网站:
https://code.google.com/p/mysql-master-ha/w/list
https://code.google.com/p/mysql-master-ha/wiki/Tutorial
在基于MySQL复制的MHA集群架构中,当Master发生故障时,MHA 通过如下步骤来保证数据的一致性:
(1) 找出同步最成功的一台从服务器(也就是与主服务器数据最接近的那台从服务器)。
(2) 如果主机还能够访问,从主服务器上找回最新从机与主机间的数据差异。
(3) 在每一台从服务器上操作,确定他们缺少哪些events,并分别进行补充。
(4) 将最新的一台从服务器提升为主服务器后。
(5) 将其它从服务器重新指向新的主服务器。
虽然MHA试图从宕机的主服务器上保存二进制日志,但并不是总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失最新数据。
结合半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来,如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此他们彼此保持一致性。
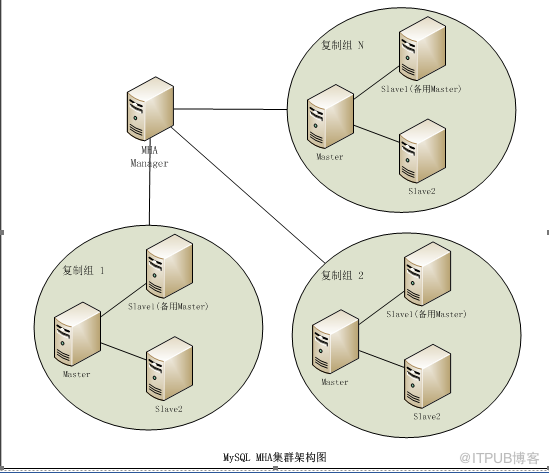
1.3.2 MHA组内架构图
复制组内使用Keepalived + LVS :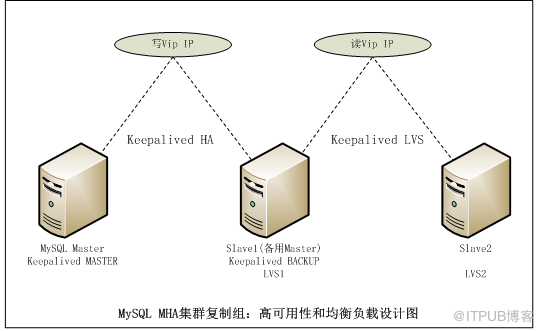
在当前已存在的主从复制环境中,MHA可以监控master主机故障,并且故障自动转移。即使有一些slave没有接受新的relay log events,MHA也会从最新的slave自动识别差异的relay log events,并apply差异的event到其他slaves。因此所有的slave都是一致的。 MHA秒级别故障转移, 另外,在配置文件里可以配置一个slave优先成为Master。
当迁移新的master之后,并行恢复其他slave。即使有成千上万的slave,也不会影响恢复master时间,slave也很快完成。整个过程无需DBA干预。
在很多情况下,有必要将master转移到其他主机上(如替换raid控制器,提升master机器硬件等等)。这并不是master崩溃,但是计划维护必须去做。计划维护导致downtime,必须尽可能快的恢复。快速的master切换和优雅的阻塞写操作是必需的,MHA提供了这种方式。优雅的master切换, 0.5-2秒内阻塞写操作。在很多情况下0.5-2秒的downtime是可以接受的,并且即使不在计划维护窗口。这意味着当需要更换更快机器,升级高版本时,dba可以很容易采取动作。
当master 宕后,MHA自动识别slave间relay logevents的不同,然后应用与不同的slave,最终所有slave都同步。结合通过半同步一起使用,几乎没有任何数据丢失。
MHA最重要的一个设计理念就是尽可能使用简单。其只要是在主从环境下,MHA集群无需改变现有部署便可部署,无论是在同步和半同步环境都可以用。启动/停止/升级/降级/安装/卸载 MHA都不用改变mysql主从(如启动/停止)。而它集群方案需要改变mysql部署设置。
当需要升级MHA到新版本时,不需要停止mysql,仅仅更新HMA版本,然后重新启动MHAmanger即可。
MHA 包含MHA Manager和MHA node。一个MHA Manager可以管理多个MHA node集群组。增加集群组时,对新增的集群组配置复制,并且更新MHA Manager的配置即可。对现有的集群组基本无影响。增加集群组数量也不会对MHA Manager有太大负担。Manager可以单独部署一台机器,也可以运行在slaves中的一台机器上。
MHA监控Master不发送大的查询,主从复制性能不受影响。本案例通过自定义脚本,定期尝试登陆Master 如果登陆失败,即实施故障切换。这么监控办法,对性能基本没什么影响。
Mysql不仅仅适用于事务安全的innodb引擎,在主从中适用的引擎,MHA都可以适用。即使用遗留环境的mysiam引擎,不进行迁移,也可以用MHA。
MHA可通常有两种方式实现业务层面的透明故障转移:一种是虚拟IP地址,MHA结合Keepalived 和LVS,当群集内的数据库进行故障转移时,对外提供服务的虚拟IP也进行转移;第二种是全局配置文件,通过配置MHA的master_ip_failover_script 、master_ip_online_change_script参数来实现。
MHA的Master为可读写,而备用Master和Slave都可用于查询,分担读压力。
Master down掉后,如需重新加入集群,需要手工执行命令切换。
备用的Master 默认是可写的,如果不设置为read only,存在数据不一致性的风险。并且read-only对super用户不起作用。
由于使用了MySQL的复制,而MySQL的复制是存在延迟的。MySQL的复制延迟主要是因为Master多线程对Slave单线程的迟延。
为了实现更好的效果,本实验使用四台机器。使用MySQL的半同步复制,保证数据的完整性。结合Keepalived和LVS 实现IP故障透明转移和读写分离。需要说明的是一旦主服务器宕机,备份机即开始充当master提供服务,如果主服务器上线也不会再成为master了,因为如果这样数据库的一致性就被改变了。
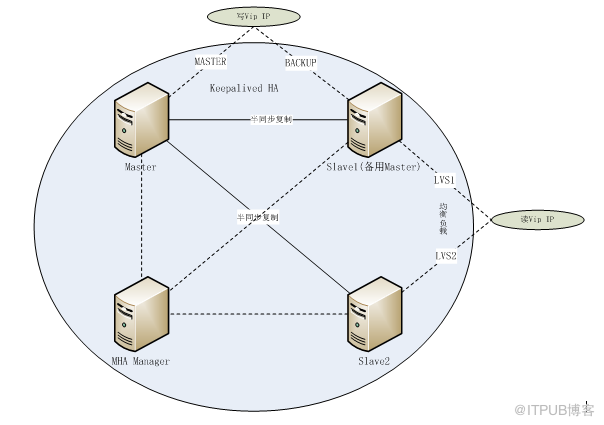
IP | 主机 | 用途说明 |
192.168.0.11 | Master | Master,Keepalived HA的Master |
192.168.0.12 | Slave1(备用Master) | 备用Master,Keepalived HA的BACKUP,LVS均衡负载主机 |
192.168.0.13 | Slave2 | Slave,LVS均衡负载主机 |
192.168.0.14 | MHA Manager | MHA集群的管理主机 |
192.168.0.20 | 虚拟IP地址 | MHA集群写VIP地址 |
192.168.0.21 | 虚拟IP地址 | MHA集群读VIP地址 |
(1)首先用ssh-keygen实现四台主机之间相互免密钥登录
(2)安装MHAmha4mysql-node,mha4mysql-manager 软件包
(3)建立master,slave1,slave2之间主从复制
(4)管理机manager上配置MHA文件
(5)masterha_check_ssh工具验证ssh信任登录是否成功
(6)masterha_check_repl工具验证mysql复制是否成功
(7)启动MHA manager,并监控日志文件
(8)测试master(156)宕机后,是否会自动切换
在MHA所有主机中生成rsa加密认证,并配置为相互访问无需密码
ssh-keygen -t rsa
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.0.11
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.0.12
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.0.13
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.0.14
在3个MySQL主从节点上安装MySQL软件。
rpm -qa mysql
rpm -e mysql-devel
rpm -e mysql
cd /media/RHEL_6.4\ x86_64\ Disc\ 1/Packages/
rpm -ivh cmake-2.6.4-5.el6.x86_64.rpm
cd /root
tar zxvf mysql-5.6.19.tar.gz
cd /root/mysql-5.6.19
mkdir -p /usr/local/mysql/data
cmake -DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DMYSQL_DATADIR=/usr/local/mysql/data
make && make install
groupadd mysql
useradd -r -g mysql mysql
(5)初始化MySQL
cd /usr/local/mysql
chown -R mysql .
chgrp -R mysql .
scripts/mysql_install_db --user=mysql
chown -R root .
chown -R mysql data
./bin/mysqld_safe --user=mysql &
cp support-files/mysql.server /etc/init.d/mysql.server
vi ~/.bash_profile
PATH加上:
:/usr/local/mysql/bin
source ~/.bash_profile
cp /usr/local/mysql/my.cnf /etc/
vi /etc/my.cnf
log_bin # mha3 不会是master,因此不用该参数
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
port = 3306
server_id = 1 #主从同步需要
socket = /tmp/mysql.sock
重启MySQL :service mysql.server restart
GRANT ALL ON *.* TO root@localhost IDENTIFIED BY 'revenco123' WITH GRANT OPTION;
GRANT ALL PRIVILEGES ON *.* TO root@'%' IDENTIFIED BY 'revenco123' WITH GRANT OPTION;
GRANT ALL PRIVILEGES ON *.* TO root@mha1 IDENTIFIED BY 'revenco123' WITH GRANT OPTION;
FLUSH PRIVILEGES;
(1)修改MASTER上的/etc/my.cnf,加入:
server_id=1
log_bin
(2)修改SLAVE1(备用MASTER)上的/etc/my.cnf,加入:
server_id=2
log_bin
(3)修改SLAVE2上的/etc/my.cnf,加入:
server_id=3
(1)在master上授权
mysql> grant replication slave on *.* to repl@'192.168.0.%' identified by 'repl';
(2)在备选master上授权:
mysql> grant replication slave on *.* to repl@'192.168.0.%' identified by 'repl';
(1)在Master查看当前使用的二进制日志名称和位置
mysql> show master status;
记录下 “File”和“Position”即当前主库使用的二进制日志名称和位置。
(2)切换到从库模式
在Slave1(备用Master)和Slave2 上切换到从库模式
mysql> change master to master_host="mha1",master_user="repl",master_password="repl",master_log_file="mha1-bin.000005",master_log_pos=120;
master_log_file 和 master_log_pos 是上面记下的东西。
(3)启动复制
在Slave1(备用Master)和slave2上启用复制:
mysql>start slave;
(6)在slave2上设置为只读
mysql>set global read_only=1
注意:read-only对super权限的用户不起作用
(1)查看出库的状态
mysql>show master status\G;
(2)查看从库的状态
mysql>show slave status\G;
# 如果 Slave_IO_Running: Yes 和 Slave_SQL_Running: Yes 则说明主从配置成功。
# 还可以到master上执行 Mysql>show global status like “rpl%”;
如果Rpl_semi_sync_master_clients 是2说明半同步复制正常
日志的同步格式有3种:
(1)基于SQL语句的复制(statement-based replication, SBR)
(2)基于行的复制(row-based replication, RBR)
(3)混合模式复制(mixed-based replication, MBR)
相应地,binlog的格式也有三种:STATEMENT,ROW,MIXED。 MBR 模式中,SBR 模式是默认的。为了数据的一致性,建议选择ROW或MIXED模式。
比如,有函数:
CREATE DEFINER = 'root'@'%' FUNCTION f_test2
(
pid int
)
RETURNS int(11)
BEGIN
insert into t1 values (pid,sysdate());
RETURN 1;
END
在主库执行 select f_test2(8)后,在主库和各个从库上,插入的sysdate()的值是不同的;
配置MySQL半同步复制的前提是已经配置了MySQL的复制。半同步复制工作的机制处于同步和异步之间,Master的事务提交阻塞,只要一个Slave已收到该事务的事件且已记录。它不会等待所有的Slave都告知已收到,且它只是接收,并不用等其完全执行且提交。
在故障切换的时候,Master和Slave1(备用Master)都有可能成为Master或Slave,因此这两个服务器上都要安装'semisync_master.so'和'semisync_slave.so'。
(1)安装半同步插件
(作为Master时需要安装的插件)
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
(作为Slave时需要安装的插件)
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
(2)设置参数
(作为Master时需要设置的参数)
mysql> set global rpl_semi_sync_master_enabled=1;
mysql> set global rpl_semi_sync_master_timeout=1000;
mysql> show global status like 'rpl%';
(作为Slave时需要设置的参数)
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
mysql> set global rpl_semi_sync_slave_enabled=1;
(3)修改配置文件
为了让mysql在重启时自动加载该功能,在/etc/my.cnf 加入:
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=1000
rpl_semi_sync_slave_enabled=1
(1)安装半同步插件
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
(2)设置参数
mysql> set global rpl_semi_sync_slave_enabled=1;
(3)修改配置文件
在/etc/my.cnf中加入:
rpl_semi_sync_slave_enabled=1
可以到master上执行 Mysql>show global status like 'rpl%';
如果Rpl_semi_sync_master_clients 是2.说明半同步复制正常
MHA有个不方便的地方是,无论宕机导致的master切换还是手动切换master, 原来的master都不在MHA架构内了,重新启动也不会加入,必须手动加入。手动加入的步骤类似,先把当前master数据复制到要加入的机器,然后change master,再start slave, 关键在做这一过程中,系统不能写入,这点要人命。
一个MHA主机可以管理多个MySQL复制组,安装MHA需要先安装DBD-MySQL,为了安装DBD-MySQL方便,先安装yum工具。
vim /etc/yum.repos.d/rhel-source.repo
[rhel-source]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
#baseurl=ftp://ftp.redhat.com/pub/redhat/linux/enterprise/$releasever/en/os/SRPMS/
baseurl=file:///mnt
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
[rhel-source-beta]
name=Red Hat Enterprise Linux $releasever Beta - $basearch - Source
#baseurl=ftp://ftp.redhat.com/pub/redhat/linux/beta/$releasever/en/os/SRPMS/
baseurl=file:///mnt
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-beta,file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
umount /dev/cdrom
mount /dev/cdrom /mnt
yum clean all
yum list
yum install perl-DBD-MySQL
cd /root
tar zxvf mha4mysql-node-0.54.tar.gz
cd mha4mysql-node-0.54
perl Makefile.PL
make
make install
(1)下载和安装必要的包
下载地址:http://apt.sw.be/redhat/el6/en/i386/extras/RPMS/perl-Config-Tiny-2.12-1.el6.rfx.noarch.rpm
http://apt.sw.be/redhat/el6/en/x86_64/rpmforge/RPMS/perl-Log-Dispatch-2.26-1.el6.rf.noarch.rpm
http://apt.sw.be/redhat/el6/en/x86_64/rpmforge/RPMS/perl-Parallel-ForkManager-0.7.5-2.2.el6.rf.noarch.rpm
(2)安装必要的包
rpm -ivh perl-Params-Validate-0.92-3.el6.x86_64.rpm
rpm –ivh perl-Config-Tiny-2.12-1.el6.rfx.noarch.rpm
rpm –ivh perl-Log-Dispatch-2.26-1.el6.rf.noarch.rpm
rpm –ivh perl-Parallel-ForkManager-0.7.5-2.2.el6.rf.noarch.rpm
(3)安装MHA manager软件
cd /mnt/Packages
cd /root
tar zxvf mha4mysql-manager-0.55.tar.gz
cd mha4mysql-manager-0.55
perl Makefile.PL
make
make install
在MHA Manager上创建MHA配置
[root@mha4 ~]# more /etc/masterha/app1.cnf
[server default]
# mysql user and password
user=root
password=revenco123
ssh_user=root
repl_user=repl
repl_password=repl
ping_interval=1
shutdown_script=""
# working directory on the manager
manager_workdir=/var/log/masterha/app1
manager_log=/var/log/masterha/app1/manager.log
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=mha1
master_binlog_dir=/usr/local/mysql/data
candidate_master=1
[server2]
hostname=mha2
master_binlog_dir=/usr/local/mysql/data
candidate_master=1
[server3]
hostname=mha3
master_binlog_dir=/usr/local/mysql/data
no_master=1
注释:具体的参数请查看官方文档
https://code.google.com/p/mysql-master-ha/wiki/Parameters
在MHA Manager上执行
masterha_check_ssh --conf=/etc/masterha/app1.cnf
masterha_check_repl --conf=/etc/masterha/app1.cnf
如果报错,请检查配置。
问题1 :
Can't exec "mysqlbinlog": No such file or directory at /usr/local/share/perl/5.10.1/MHA/BinlogManager.pm line 99.
mysqlbinlog version not found!
解决办法:
#vi ~/.bashrc或vi /etc/bashrc,然后在文件末尾添加
PATH="$PATH:/usr/local/mysql/bin"
export PATH
source /etc/bashrc
问题2:
Testing mysql connection and privileges..Warning: Using a password on the command line interface can be insecure.
ERROR 1045 (28000): Access denied for user 'root'@'mha2' (using password: YES)
解决办法: 查看用户表。
RANT ALL PRIVILEGES ON *.* TO root@mha1 IDENTIFIED BY 'revenco123' WITH GRANT OPTION;
启动管理节点进程
masterha_manager --conf=/etc/masterha/app1.cnf &
注:停止和启动MHA服务,不影响MySQL对外提供服务。
当MHA群集内的数据库进行故障转移时,对外提供服务的虚拟IP也进行转移;本实验案例通过使用Keepalived + LVS的方法,实现读写分离,IP故障透明转移。
写分离,Master和Slave1(备用Master)共用一个写虚拟IP,任何时刻,只能有一台机可写,正常情况下,写操作在Master执行,当Master down机后,MHA把Slave1(备用Master)提升为Master,此后,Slave1(备用Master)可写,当Master修复起来后,它成为Slave,仍然是Slave1(备用Master)可写。除非人工干预,将修复后的Master提升为Master。
读分离,Slave1(备用Master)和Slave2 共用一个读虚拟IP。采用LVS的轮询算法,轮流访问Slave1(备用Master)和Slave2,如果其中一台不可访问,则访问另外一台服务器。
注意:一旦主服务器宕机,备份机即开始充当master提供服务,如果主服务器上线也不会再成为master了,因为如果这样数据库的一致性就被改变了。

在Master和Slave1(备份Master)上安装Keepalived
rpm -ivh openssl-devel-1.0.0-27.el6.x86_64
tar zxvf keepalived-1.2.13.tar.gz
cd keepalived-1.2.13
./configure --prefix=/usr/local/keepalived
编译后看到三个yes才算成功如果出现两个yes或者一个应该要检查下内核软连接做对了没有:
Use IPVS Framework : Yes #必须为YES
IPVS sync daemon support : Yes #必须为YES
IPVS use libnl : No
fwmark socket support : Yes
Use VRRP Framework : Yes #必须为YES
Use VRRP VMAC : Yes
make
make install
cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/
cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
mkdir -pv /etc/keepalived
cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/
ln -s /usr/local/keepalived/sbin/keepalived /sbin/
service keepalived restart
整个MHA使用keepalived 的"HA + LVS"模式,在mha1和mha2 上配置 Keepalived HA 模式,即下面代码的“vrrp_instance VI_1”实例组;在mha2和mha3 上配置 Keepalived LVS 模式,即下面代码的“vrrp_instance VI_2”实例组。两个主机配置的都是“state BACKUP”,但优先级priority 不同。配置如下:
[root@mha1 ~]# more /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id mha1
}
vrrp_script check_mysql {
script "/usr/local/keepalived/bin/keepalived_check_mysql.sh"
interval 3
}
vrrp_sync_group VG1 {
group {
VI_1
}
}
vrrp_sync_group VG2 {
group {
VI_2
}
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 150
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass revenco123
}
track_script {
check_mysql
}
virtual_ipaddress {
192.168.0.20
}
}
vrrp_instance VI_2 {
state BACKUP
interface eth0
virtual_router_id 52
priority 100
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass revenco1234
}
track_script {
check_mysql
}
virtual_ipaddress {
192.168.0.21
}
}
virtual_server 192.168.0.21 80 {
delay_loop 6
lb_algo rr
lb_kind DR
protocol TCP
real_server 192.168.0.12 80 {
weight 3
TCP_CHECK {
connect_timeout 3
}
}
real_server 192.168.0.13 80 {
weight 3
TCP_CHECK {
connect_timeout 3
}
}
}
}
[root@mha2 ~]# more /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id mha2
}
vrrp_script check_mysql {
script "/usr/local/keepalived/bin/keepalived_check_mysql.sh"
interval 3
}
vrrp_sync_group VG1 {
group {
VI_1
}
}
vrrp_sync_group VG2 {
group {
VI_2
}
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 100
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass revenco123
}
track_script {
check_mysql
}
virtual_ipaddress {
192.168.0.20
}
}
vrrp_instance VI_2 {
state BACKUP
interface eth0
virtual_router_id 52
priority 150
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass revenco1234
}
track_script {
check_mysql
}
virtual_ipaddress {
192.168.0.21
}
}
virtual_server 192.168.0.21 3306 {
delay_loop 6
lb_algo rr
lb_kind DR
protocol TCP
real_server 192.168.0.12 3306 {
weight 3
TCP_CHECK {
connect_timeout 3
}
}
real_server 192.168.0.13 3306 {
weight 3
TCP_CHECK {
connect_timeout 3
}
}
}
在两台Keepalived主机上,配置检测mysql状态脚本(两台mysql一样的配置),脚本文件要实现的功能大体为:只要检测到mysql服务停止keepalived服务也停止 ,因为keepalived是通过组播方式告诉本网段自己还活着当mysql服务停止后keepalived还依然运行 这时就需要停止keepalived让另一个主机获得虚拟IP,可以在后台运行这个脚本 也可以在keepalived配置文件加入这个脚本,本实验把该脚本配置在keepalived配置文件中。
脚本文件名: /usr/local/keepalived/bin/keepalived_check_mysql.sh
#!/bin/bash
MYSQL=/usr/local/mysql/bin/mysql
MYSQL_HOST=localhost
MYSQL_USER=root
MYSQL_PASSWORD=revenco123
CHECK_TIME=3
#mysql is working MYSQL_OK is 1 , mysql down MYSQL_OK is 0
MYSQL_OK=1
function check_mysql_helth (){
$MYSQL -h $MYSQL_HOST -u$MYSQL_USER -p$MYSQL_PASSWORD -e "show status;" >/dev/null 2>&1
if [ $? = 0 ] ;then
MYSQL_OK=1
else
MYSQL_OK=0
fi
return $MYSQL_OK
}
while [ $CHECK_TIME -ne 0 ]
do
let "CHECK_TIME -= 1"
check_mysql_helth
if [ $MYSQL_OK = 1 ] ; then
CHECK_TIME=0
exit 0
fi
if [ $MYSQL_OK -eq 0 ] && [ $CHECK_TIME -eq 0 ]
then
/etc/init.d/keepalived stop
exit 1
fi
sleep 1
done
使用LVS技术要达到的目标是:通过LVS提供的负载均衡技术和Linux操作系统实现一个高性能、高可用的服务器群集,它具有良好可靠性、可扩展性和可操作性。从而以低廉的成本实现最优的服务性能。本实验通过使用LVS软件,在Slave1(备用Master)和Slave2上实现读负载均衡。
Keepalived 附带了LVS的功能,因此LVS服务器端的配置是直接在Keepalived的配置文件中配置的,Keepalived的配置文件的“virtual_server”部分的配置,便是LVS的配置。具体请查看Keepalived的配置文件的“virtual_server”部分。
在本实验案例中,LVS的真实机是Slave1(备用Master)和Slave2
在lvs的DR和TUn模式下,用户的访问请求到达真实服务器后,是直接返回给用户的,而不再经过前端的Director Server,因此,就需要在每个Real server节点上增加虚拟的VIP地址,这样数据才能直接返回给用户,增加VIP地址的操作可以通过创建脚本的方式来实现,创建文件/etc/init.d/lvsrs,脚本内容如下
[root@mha3 ~]# more /etc/init.d/lvsrs
#!/bin/bash
#description : Start Real Server
VIP=192.168.0.21
. /etc/rc.d/init.d/functions
case "$1" in
start)
echo " Start LVS of Real Server"
/sbin/ifconfig lo:0 $VIP broadcast $VIP netmask 255.255.255.255 up
echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce
;;
stop)
/sbin/ifconfig lo:0 down
echo "close LVS Director server"
echo "0" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "0" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/all/arp_announce
;;
*)
echo "Usage: $0 {start|stop}"
exit 1
esac
vim /etc/iptables
/etc/init.d/iptables restart
# 允许vrrp协议通过
(1). 启动mha1,mha2的keepalived,访问两个VIP所访问的主机。
测试结果:对于VIP1,访问mha1;对于VIP2,轮流访问mha2和mha3。
(2). 关闭mha1的keepalived
测试结果:对于VIP1,访问mha2;对于VIP2,轮流访问mha2和mha3。
(3). 再启动mha1的keepalived
测试结果:对于VIP1,访问mha2;对于VIP2,轮流访问mha2和mha3。
(4). 关闭mha2的keepalived
测试结果:对于VIP1,访问mha1;对于VIP2,轮流访问mha2和mha3。
(5). 再启动mha2的keepalived
测试结果:对于VIP1,访问mha1;对于VIP2,轮流访问mha2和mha3。
(6). 重复一次“1--5”步骤。
测试结果:测试结果相同。
(7). 同时关闭mha1,mha2的keepalived
测试结果:两个VIP都不能访问。
测试的服务为httpd:
(没有加脚本,让httpd服务器停止,keepalived服务也停止。如果是Mysql服务器是有相应的脚本的)
(1). 启动mha1,mha2的keepalived 和httpd服务,访问两个VIP所访问的主机。
测试结果:对于VIP1,访问mha1;对于VIP2,轮流访问mha2和mha3。
(2). 关闭mha1的httpd
测试结果:对于VIP1,访问mha2;对于VIP2,轮流访问mha2和mha3。
(3). 再启动mha1的httpd
测试结果:对于VIP1,访问mha2;对于VIP2,轮流访问mha2和mha3。
(4). 关闭mha2的httpd
测试结果:对于VIP1,无法访问;对于VIP2,访问mha3。
(应该在keepalive中定期检测httpd服务,httpd服务停止,那么keepalived服务也停止,让mha1作为Master,那样VIP1就可以访问mha1,而不是现在的“无法访问”)
(5). 再启动mha2的httpd
测试结果:对于VIP1,恢复访问mha2;对于VIP2,轮流访问mha2和mha3。
(6). 关闭mha3的httpd
测试结果:对于VIP1 无任何影响;对于VIP2,访问mha2。
(7). 再启动mha3的httpd
测试结果:对于VIP1 无任何影响;对于VIP2,轮流访问mha2和mha3。
(8). 同时关闭mha1,mha2的httpd
测试结果:两个VIP都不能访问。
(1)先使用mha-w-vip 连接到mha集群,查看所连接的数据库主机信息。
mysql -uroot -ptest123 -h 172.20.52.252
use mysql
select host,user,password from user;
(2)关闭当前的master 的mysql服务。
(3)查看mha-w-vip(写VIP) 连接是否可连接到mha集群,当前连接是否断掉。
(4)测试结果:停止master上的mysql服务后,3秒内进行切换 "写VIP"。当master上的mysql服务down后,备用master成为master,集群可用。当原master恢复后,需要手工把它切换到复制状态。
只能做到连接的高可用性,做不到会话级别的高可用性。即,down后,原有的会话将断开,然后马上重新连接。
轮流停止备用master和、slave,然后使用读vip连接后,查看当前所连接的库的主机信息。
(1)先使用mha-r-vip (读VIP)连接到mha集群,查看所连接的数据库主机信息。
mysql -uroot -ptest -h 172.20.52.253
use mysql
select host,user,password from user;
(2)打开多个会话,重复上一步。
(3)查看各个会话是连接到哪个主机上。
(4)测试结果:备用master、slave都在线时,轮流访问。
(1)先使用mha-r-vip (读VIP)连接到mha集群,查看所连接的数据库主机信息。
mysql -uroot -ptest123 -h mha1-r-vip
use mysql
select host,user,password from user;
(2)轮流停止备用master和slave,然后使用读vip连接后,查看当前所连接的库的主机信息。
(3)测试结果:备用master、slave任何一台的mysql服务down掉,集群都可读。
在主库上执行创建库、表、并插入数据,查看备用master和slave的数据同步情况。
(1)在主库上执行创建库、表、并插入数据
mysql> create database test;
Query OK, 1 row affected (0.00 sec)
mysql> create table t1 (id int ,name varchar(20));
ERROR 1046 (3D000): No database selected
mysql> use test;
Database changed
mysql> create table t1 (id int ,name varchar(20));
Query OK, 0 rows affected (0.04 sec)
mysql> insert into t1 values (1,'a');
Query OK, 1 row affected (0.02 sec)
mysql> insert into t1 values (2,'b');
(2)登录备库,查看数据
Use test
Select * from t1;
(3)测试结果:
备用master slave都能马上自动同步数据。(后台在毫秒级别上完成同步)
测试把备用master和slave设置为read_only后,效果如何
(1)设置为只读
set global read_only=1;
(2)登录并插入数据
Mysql –uroot –prtest123 –D test
Insert into t1 values(1,’a’);
插入成功
(3)创建普通用户
GRANT ALL ON test.* TO test@'%' IDENTIFIED BY 'test' WITH GRANT OPTION;
GRANT ALL ON test* TO test@localhost IDENTIFIED BY 'test' WITH GRANT OPTION;
(3)登录并插入数据
Mysql –utest–ptest–D test
Insert into t1 values(1,’a’);
插入失败
(4)测试结果:read_only对super用户无影响,对普通用户能起到限制作用。
主库
mysql -utest-ptest-D test
insert into t1 values(3,'c');
备用master、slave查询:
select * from t1;
测试
备用master、slave插入:
mysql -utest -ptest -D test
insert into t1 values(4,'d');
ERROR 1290 (HY000): The MySQL server is running with the --read-only option so it cannot execute this statement
结论:在备用master、slave设置只读,可限制备用master、slave的写功能,并且不影响主从复制功能。
原master恢复后,如果想让原master(mha1)一直为slave,需要做以下:
1). 需要更改mha manager文件中mha1的顺序。
2). 删除 rm /var/log/masterha/app1/app1.failover.complete
3). 再次启动mha manager进程
4). 让mha2的keepalived为HA 的Master,mha1为"BACKUP"状态,保证“写vip”是关联到Master上的。
5). 修改读VIP。读VIP为mha1、mha3(原mha2、mha3)
6). 设置原master(mha1)为read_only
7). 检查 show slave status \G; show master status;
原master恢复后,如果想让原master(mha1)重新成为Master,需要做以下:
1). 在mha manager上,手工把mha1切换为Master。
2). 设置备用master(mha2)为read_only.
3). 删除 rm /var/log/masterha/app1/app1.failover.complete
4). 重新启动mha manager进程。
5). 让mha1的keepalived为HA 的Master,mha2为"BACKUP"状态,保证“写vip”是关联到Master上的。
6). 检查 show slave status \G; show master status;
(1).停止master_manager进程:masterha_stop --conf=/etc/app1.cnf
(2).执行切换命令,可根据需要执行使用不同的参数。
主库down的情况
masterha_master_switch --master_state=dead --conf=/etc/conf/masterha/app1.cnf --dead_master_host=mha2
非交互式故障转移
masterha_master_switch --master_state=dead --conf=/etc/conf/masterha/app1.cnf --dead_master_host=mha2 --new_master_host=mha1 --interactive=0
在线切换,切换后原来的主库不要
masterha_master_switch --master_state=alive --conf=/etc/masterha/app1.cnf --new_master_host=mha1
在线切换,切换后原来的主库变成从库
masterha_master_switch --master_state=alive --conf=/etc/masterha/app1.cnf --new_master_host=mha1 --orig_master_is_new_slave
导出:
mysqldump -uroot -p123456 test > test_20140704.sql
导入:
mysql -uroot -ptest123 test< test_20140704.sql
测试结果:在主库执行导入,从库自动同步数据。
在Master上创建存储过程`f_test`,然后在备用master和slave上创建,如果提示存储过程已存在,则说明创建存储过程也会同步到备用master和slave。
DELIMITER $$
CREATE DEFINER=`root`@`%` PROCEDURE `f_test`(
IN p_id int,
IN p_name varchar(20)
)
begin
insert into t1 values(p_id,p_name);
END;
$$
DELIMITER ;
测试结果:创建存储过程也会同步到备用master和slave。
在master上执行
call f_test(4,'d');(f_test的功能是插入一条记录到t1)
查询select * from t1;
在备用master和slave查询select * from t1;
数据与Master上一致,存储过程内修改数据会同步。
测试结果:存储过程内修改数据会同步。
mysql主从复制,经常会遇到错误而导致slave端复制中断,这个时候一般就需要人工干预,跳过错误才能继续。跳过错误有两种方式:
mysql> stop slave;
mysql>SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1 #跳过一个事务
mysql>slave start
通过slave_skip_errors参数来跳所有错误或指定类型的错误
vi /etc/my.cnf
[mysqld]
#slave-skip-errors=1062,1053,1146 #跳过指定error no类型的错误
#slave-skip-errors=all #跳过所有错误
Mysql 对函数的同步有限制。只有被明确声明为DETERMINISTIC或NO SQL 或READS SQL DATA的函数,才可以创建,并可自动同步到从库,否则创建函数会失败。可以通过设置参数“set global log_bin_trust_function_creators = 1”,使得函数能创建成功,并同步到从库。此参数只有在开启log-bin的情况下才有用。log_bin_trust_function_creators=0的情况下,需要有SUPER权限,并且不包含修改数据的SQL,才能创建函数。
(1)测试正常主从复制情况下,函数的创建
mysql> set global log_bin_trust_function_creators = 1;
CREATE DEFINER = 'root'@'%' FUNCTION f_test2
(
pid int
)
RETURNS int(11)
BEGIN
insert into t1 values (pid,sysdate());
RETURN 1;
END
测试结果:在主从环境下,如果函数没有声明DETERMINISTIC或NO SQL 或READS SQL DATA,创建函数失败。
(2)强行声明为DETERMINISTIC或NO SQL 或READS SQL DATA的函数测试
CREATE DEFINER = 'root'@'%' FUNCTION f_test2
(
pid int
)
RETURNS int(11)
DETERMINISTIC
BEGIN
insert into t1 values (pid,sysdate());
RETURN 1;
END
测试结果:可以创建成功,并且可同步到从库。但无法执行该函数,执行时报错。
(3)把global log_bin_trust_function_creators = 1后,不声明函数的为DETERMINISTIC或NO SQL 或READS SQL DATA属性。
mysql> set global log_bin_trust_function_creators = 0;
创建函数成功,也可以同步到从库(开启bin-log的从库必须做同样的参数配置)。
在主库执行函数
mysql> select f_test2(7);
mysql> select * from t1;
在主库的t1表有插入记录,并且有同步到从库。
binlog_format = STATEMEN 的情况下:
创建存储过程p_test1,自动同步到从库,并不需要“set global log_bin_trust_function_creators = 1;”,由此看出,存储过程的复制时安全的;执行call p_test1(14);数据完全同步到从库。如果是函数,并不完全同步,sysdate()获取的值不同。
p_test1代码:
DELIMITER |
CREATE DEFINER = 'root'@'%' PROCEDURE p_test1
(
pid int
)
BEGIN
declare v_time datetime;
set v_time = sysdate();
insert into t1 values (pid,v_time);
END|
DELIMITER ;
测试结果:结合函数同步的测试情况,可得出:
在binlog_format = STATEMEN的情况下,执行存储过程时,后台采用binlog_format =ROW的方式同步日志;而执行函数时,后台采用binlog_format =STATEMEN的方式同步日志。
(1)查看ssh登陆是否成功
masterha_check_ssh --conf=/etc/masterha/app1.cnf
(2)查看复制是否建立好
masterha_check_repl --conf=/etc/masterha/app1.cnf
(3)启动mha
nohup masterha_manager --conf=/etc/masterha/app1.cnf > /tmp/mha_manager.log < /dev/null 2>&1 &
当有slave节点宕掉的情况是启动不了的,加上--ignore_fail_on_start即使有节点宕掉也能启动mha
nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_fail_on_start > /tmp/mha_manager.log < /dev/null 2>&1 &
(4)检查启动的状态
masterha_check_status --conf=/etc/masterha/app1.cnf
(5)停止mha
masterha_stop --conf=/etc/masterha/app1.cnf
(6)failover后下次重启
每次failover切换后会在管理目录生成文件app1.failover.complete ,下次在切换的时候会发现有这个文件导致切换不成功,需要手动清理掉。
rm -rf /masterha/app1/app1.failover.complete
也可以加上参数--ignore_last_failover
(7)手动在线切换
1).手动切换时需要将在运行的mha停掉后才能切换。可以通过如下命令停止mha
masterha_stop --conf=/etc/app1.cnf
2).执行切换命令
手工failover场景,master死掉,但是masterha_manager没有开启,可以通过手工failover:
masterha_master_switch --master_state=dead --conf=/etc/app1.cnf --dead_master_host=host1 --new_master_host=host5
或者
masterha_master_switch --conf=/etc/app1.cnf --master_state=alive --new_master_host=host1 --orig_master_is_new_slave
或者
masterha_master_switch --conf=/etc/app1.cnf --master_state=alive --new_master_host=host1 --orig_master_is_new_slave --running_updates_limit=10000 --interactive=0
参数解释
--orig_master_is_new_slave切换时加上此参数是将原master变为slave节点,如果不加此参数,原来的master将不启动,需要设置在配置文件中配置repl_user 、repl_password参数 。
--running_updates_limit=10000 切换时候选master如果有延迟的话,mha切换不能成功,加上此参数表示延迟在此时间范围内都可切换(单位为s),但是切换的时间长短是由recover时relay日志的大小决定。
--interactive=0,切换时是否互交,默认是互交的。互交的意思就是要你选择一些选项,如根据提示输入“yes or no”。
--master_state=alive master在线切换,需要如下条件,第一,在所有slave上IO线程运行;第二,SQL线程在所有的slave上正常运行;第三,在所有的slaves上 Seconds_Behind_Master 要小于等于 running_updates_limit seconds;第四,在master上,在show processlist输出结果上,没有更新查询操作多于running_updates_limit seconds。
在备库先执行DDL,一般先stop slave,一般不记录mysql日志,可以通过set SQL_LOG_BIN = 0实现。然后进行一次主备切换操作,再在原来的主库上执行DDL。这种方法适用于增减索引,如果是增加字段就需要额外注意。
上述内容就是MySQL MHA集群方案是怎样的,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





