A lot of people start using Oracle Coherence as a distributed cache because they need to get away from a data-bottlenecking problem. Many of open source NoSQL stores will help you with this problem too (if all you need is to stream large data volumes, being solely in memory is unlikely to be worth the additional hardware cost). However there are some big advantages to being entirely in memory. Distributed execution occurs next to the data it needs to operate on, either on request or as a result of some state change (think trigger), and this is a very powerful tool. This can lead to one of those ‘penny-dropping moment’ as the potential of merging data and processing, particularly in a wholly in-memory architecture, begins to unfold.
The benefits or moving computation to data have been around for a very long time – stored procedures being the classic example. The possibilities are extended significantly when the processing space is actually a distributed data grid, with all logic executing in the same language (in this case Java) and with data represented hierarchically (as objects) rather relationally. Suddenly a whole world of fast distributed processing on collocated data opens up.
Interestingly this is one of the main drivers for MapReduce (e.g. Hadoop): deal with very large data sets in a simple (albeit somewhat brute-force) way, collocating data and processing (although in Hadoop’s case it’s disk based) to allow processing to scale to peta- or exabytes. This same pattern can be applied in Coherence but with a slightly different as the goal: extending your application tier to allow real time processing in virtual address space that can grow to terabytes.
There are a couple of points worthy of note before we go on:
Data affinity allows associations to be set up between data in different caches so that the associated data objects in the two different caches are collocated on the same machine. In the example here trade data and market data are linked via the ticker meaning that all trades for ticker ATT will be stored on the same machine as the ATT market data.
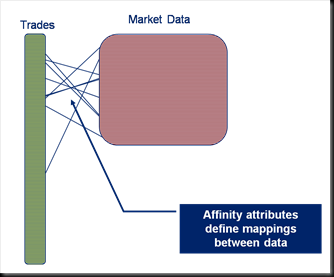
Thus when an Entry Processor or Aggregator executes, say to run a trade pricing routine, it can access the trade and its market data without having to make a wire call as the market data for that particular trade will be held on the same machine (whenever possible).
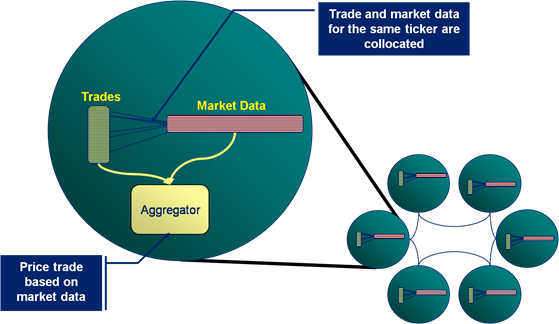
This presents the possibility of folding the classic service-centric approach in two[1]. Suddenly compute architectures can be merged into one layer that has responsibility for compute and data. The fundamental advantage being that far less data needs to be transmitted across the wire.
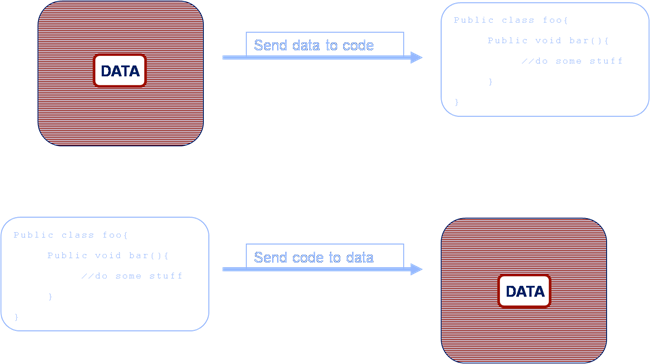
In a standard architecture (the upper example) data is retrieved from a data source and sent to the application tier for processing. However in the Coherence Application-Centric approach (the lower example) the code is sent to the machine that holds the data for execution. This is one of the real penny-dropping concepts that can revolutionise a systems performance.
But it is important to note that Coherence is not a direct substitute for a compute grid such as DataSynapse. Application-Centric Coherence involves leveraging in the inherent distribution Coherence provides as well as its inherent collocation of processing and data.
Thus looking at the anatomy of a simple Application-Centric deployment we see:
This is just one sample pattern, there are many others. Simply using Aggregators (thing MapReduce) distribute work to collocated data on the grid is a powerful pattern in it’s own right. All these patterns share the ability to collocate domain processing in a Java across a large, distributed address space. This means that not only is the execution collocated with the data but the executions are implicitly load balanced across the Coherence cluster.
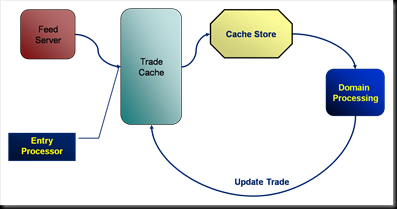
So Coherence has evolved from being a data repository to an application container which provides:
An enticing proposition!!!
[1] Service-Centric and Application-Centric are terms coined by Lewis Foti to describe the two broad architectural styles used to build Coherence based systems. Service-Centric architectures use Coherence simply as a data repository. Application-Centric users use Coherence as a framework for building event based distributed systems. Such systems leverage the inherent distribution and fault tolerance that comes with the product with operations being generally collocated with the data they require. This merges the Application and Data layers of the system.
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/20502651/viewspace-2147076/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



