1.CRS简介
从Oracle 10G开始,oracle引进一套完整的集群管理解决方案—-Cluster-Ready Services,它包括集群连通性.消息和锁.负载管理等框架.从而使得RAC可以脱离第三方集群件,当然,CRS与第三方集群件可以共同使用.
(1).CRS进程
CRS主要由三部分组成,三部分都作为守护进程出现
<1>CRSD:资源可用性维护的主要引擎.它用来执行高可用性恢复及管理操作,诸如维护OCR及管理应用资源,它保存着集群的信息状态和OCR的配置,此进程以root权限运行.
<2>EVMD:事件管理守护进程.此进程还负责启动racgevt进程以管理FAN服务器端调用,此进程以root权限运行
<3>OCSSD:集群同步服务进程.管理集群节点的成员资格,它以fatal方式启动,因此进程发生故障将导致集群重启,以防止数据坏死.同时,CSS还维护集群内的基本锁功能,以及负责监控voting disk的脑裂故障。它以Oracle权限运行
此外,还有一个进程OPRCD,他是集群中的进程监视程序,仅当平台上的CRS不使用厂商群件时候才出现,且无论运行了多少实例,每个节点只会存在一组后台进程.
来看一下这几个守护进程:
rac1-> cat/etc/inittab
…………………………….
# Run xdm in runlevel 5
x:5:respawn:/etc/X11/prefdm –nodaemon
h2:35:respawn:/etc/init.d/init.evmd run >/dev/null 2>&1 </dev/null
h3:35:respawn:/etc/init.d/init.cssd fatal >/dev/null 2>&1 </dev/null
h4:35:respawn:/etc/init.d/init.crsd run >/dev/null 2>&1 </dev/null
(2).Virtual IP Address
Oracle 10G RAC下,有3个重要的IP.
① Public IP ② Private IP ③ Vitual IP
Public IP为数据库所在主机的公共网络IP,Private IP被用来私有高速互联,而Oracle较前版本,增加了一个虚拟IP,用来节点发生故障时候更快的故障转移,oracle利用每个节点的lisnter侦听VIP,一旦发生故障,VIP将进行实际的故障切换,从而在其他的可用的节点上保持联机,从而降低客户应用程序意识到节点故障所需要的时间。
VIP与Public IP必须在同一个网段内。
(3).OCR,Voting disk
OCR(oracle集群注册表)和Voting disk(表决磁盘)是CRS下的两个重要组件,它们必须放在共享磁盘上,以保证每个节点都能对其访问。
OCR包含了针对集群的一些配置信息,诸如:集群数据库中的节点列表.CRS应用程序.资源文件以及事件管理器的授权信息。他负责对集群内的资源追踪,从而获知资源正在哪里运行,应该可以在哪里运行。
Voting disk用来解决split-brain故障:如果节点丢失了与集群中其他节点的网络连接,这些冲突由表决磁盘中的信息来解决
2.ASM相关
ASM (Automated Storage Management) 是Oracle 10G引入的一种文件类型,他提供了直接的I/O读写,是RAC体系下一套不错的对数据文件存储规划的方案. ASM可以自动管理磁盘组,并提供数据冗余和优化.后面章节会就ASM的管理以及ASM下的RAC管理,单独讲解.
3.RAC存储/网络需求

(1).存储需求
共享存储器是RAC的重要组件之一。它要求集群内的节点可以同时读写物理磁盘。目前,支持共享存储的文件类型也比较多,像Oracle自身提供的ASM,OCFS2以及三方提供的群集文件系统,都是可以选择的类型。
表1.1.1显示了RAC 体系架构下各部分所支持的存储类型 (暂不考虑三方集群文件系统,就ASM/raw device/OCFS2和普通文件系统来说)
表1.1.1 RAC各部分所支持的存储类型
|
类别 |
支持的存储类型 |
存储位置 |
备注 |
|
Cluster 软件 |
OCFS2,普通文件系统 |
共享磁盘/本地磁盘 |
|
|
OCR,Voting disk |
OCFS2,raw device |
共享磁盘 |
|
|
数据库软件 |
OCFS2,普通文件系统 |
共享磁盘/本地磁盘 |
|
|
数据库文件 |
OCFS2,raw device,ASM |
共享磁盘 |
|
|
归档日志文件 |
OCFS2,ASM,普通文件系统 |
共享磁盘/本地磁盘 |
|
|
备份/恢复文件 |
OCFS2,ASM,普通文件系统 |
共享磁盘/本地磁盘 |
|
|
闪回日志文件 |
OCFS2,ASM |
共享磁盘 |
|
(2).网络需求
每个节点主机上至少需要2张物理网卡,以便分配公有IP和私有IP地址。对于私有IP连接,每个集群节点通过专用高速网络连接到所有其他节点,目的在于集群上的节点和实例交换信息状态(锁信息,全局缓存信息等)。通过高速互联,Cache Fusion得以实现。
在实际环境中,高速互联至少需要配置GB级的以太网,而且,最好不要使用交叉直连。
较好的解决方案是节点间配置专用交换机,这样避免因为集群上一个节点宕掉而影响另外节点的正常工作。
4.其他
(1).后台进程

图1.4.1 Backgroud Process in RAC 10g
由于要维护多个实例同时访问资源所必需的锁定,因此,同single instance相比,RAC下增加了额外的一些进程。专门针对RAC的进程有如下几种:
1. LMS(Global Cache Service) 全局缓存服务进程
LMS负责为缓存融合请求在实例间传递块。当一致性请求的时候,LMS首先回滚块,创建块的读一致性映像(CR),然后将该一致性版本通过高速互联传递到处理此请求的远程实例中的前台进程上,LMS进程保证了在同一时刻只允许一个实例去更新数据块。
LMS进程的数量由初始化参数GCS_SERVER_PROCESSES控制。Oracle最大支持36个LMS进程(0–9 and a–z),该初始化参数默认值为2。
2. LMD (Global Enqueue Service Daemon) 全局队列服务守护进程
LMD负责管理全局队列和全局资源访问,并更新相应队列的状态,此外还负责远程节点资源的请求与死锁的检测。LMD与LMS进程互交工作,共同维护GRD。
3. LMON (Global Enqueue Service Monitor) 全局队列服务监控器进程
LMON是全局队列服务的监控器,他负责检查集群内实例的死亡情况并发起重新配置,当实例加入或者离开集群的时候,它负责重新配置锁和资源。
4. LCK(Lock process) 锁进程
LCK管理那些不是缓存融合的请求,例如library cahe, row cache.由于LMS进程提供了主要的锁管理功能,因此每个节点实例上只有一个LCK进程。
DIAG (The Diagnostic Daemon)诊断守护进程
DIAG负责监控实例的健康状况并捕获进程失败的信息,并将失败信息写入用于失败分析,该进程自动启动且不需要人为调整,若失败则自动重新启动。
(2).缓存融合/缓存一致性
Cache Fusion是RAC工作原理的一个中心环节.他的本质就是通过互联网络在集群内各节点的SGA之间进行块传递,从而避免了首先将块推送到磁盘,然后再重新读入其他实例的缓存中,从而最大限度的减少I/O。当一个块被读入RAC环境中某个实例的缓存时,该块会被赋予一个锁资源(与行级锁不同),以确保其他实例知道该块正在被使用。之后,如果另一个实例请求该块的一个拷贝,而该块已经处于前一个实例的缓存内,那么该块会通过互联网络直接被传递到另一个实例的SGA。如果内存中的块已经被改变,但改变尚未提交,那么将会传递一个CR副本。这就意味着,只要可能,数据块无需写回磁盘即可在各实例缓存之间移动,从而避免了同步多实例的缓存所花费的额外I/O,由此,需要互联网络的速度是高速的,需要快于磁盘访问的速度.
GCS负责维护全局缓冲区内的缓存一致性,LMS进程是其主要组成部分。GCS确保同一时刻某个块上,只能有来自一个实例上的进程能对其修改,同时,并获得该块的当前版本和前映像,以及块所处的状态(NULL,,Shared, Exclusive),模式(local/gobal)。
GES负责维护dictionary cache和library cache缓存一致性(这个与LCK是不同的)。由于存在某个节点上对数据字典的修改(比如ddl和dcl对object属性的修改),GES负责同步各节点上的字典缓存,消除差异。GES确保请求访问相同对象的多个实例间不会出现死锁。
GRD包含了所有共享资源的当前状态信息,它由GES和GCS共同维护,GRD贮存在内存中,被用来管理全局资源活动。比如:当一个实例第一次读取某块到SGA的时候,该块的角色为LOCAL,GCS记录此状态到GRD,一旦有另外的实例请求该块,GCS会更新GRD,将此块的角色由LOCAL变为GLOBAL。
二 RAC安装
不用把安装RAC看成是多么困难的一件事情.足够细心和耐性,充分的准备工作,然后加上一丁点运气,相信你能很快部署好一个RAC测试环境.当然,虚拟环境和实际环境的安装不尽相同,而且,生产系统环境的搭建需要经过缜密的规划和系统的测试.但大同小异,安装过程不该称为我们的绊脚石.
1.安装规划部署
安装之前需重点规划RAC系统各文件的存储类型.可以参见表1.3.1。一个好的存储规划方案,可以省去很多后续的维护成本。
2. 安装过程
安装过程可以参考oracle联机文档install guid。(Vmware安装可以参考Vincent Chan发表在oracle网站上的一文<使用 VMware Server 在 Oracle Enterprise Linux 上安装 Oracle RAC 10g>.文中讲的很详细,在此简单带过.)。简单列一下安装RAC的几个重要步骤
配置系统内核参数以及环境
配置共享存储
安装CRS软件
安装RDBMS软件
创建数据库以及配置其他
3.几点注意问题.
特别提一下vmware下的时间同步问题,在我的环境下,两节点上时间差别很大.一开始采用vmware-toolbox工具同步宿主时间,效果不理想.可以在每个节点上放置一个小脚本,让他每隔一段时间以另一个节点为基准同步时间.这样,时间同步问题迎刃而解.在我的环境下,我设置每20秒同步一次时间.
rac1>cat date.sh
#!/bin/sh
while true
do
rdate -s rac2>dev/null 2>&1
sleep 10
done
三 RAC管理维护
同Single instance相比,RAC的管理维护要复杂一些。10g给我们提供了一个强大的EM管理工具,将很多管理维护工作简单和界面化。我们也应当习惯使用EM来高效的完成更多的工作。本文以下部分,将暂不讨论EM方面的管理,着重于命令行方式。
1.CRS管理维护
(1).CRS相关的接口命令
CRS在10G RAC体系下有着举足轻重的作用。Oracle也提供了一些命令接口让我们诊断维护它。
<1>CRS_*
10G RAC下,有这么几组crs_命令维护CRS资源。
[root@rac2 bin]# ls $ORA_CRS_HOME/bin|grep "crs_"|grep -v bin
crs_getperm crs_profile crs_register crs_relocate crs_setperm crs_start crs_stat crs_stop crs_unregister
下面分别讲述一下它们。
集群资源查询:CRS_STAT
可以用来查看RAC中各节点上resources的运行状况,Resources的属性等。
例如使用-t选项,检查资源状态:
[root@rac1 ~]# crs_stat –t
Name Type Target State Host
ora.demo.db application ONLINE ONLINE rac2
ora....o1.inst application ONLINE ONLINE rac1
ora....o2.inst application ONLINE ONLINE rac2
ora....SM1.asm application ONLINE ONLINE rac1
ora....C1.lsnr application ONLINE ONLINE rac1
ora.rac1.gsd application ONLINE ONLINE rac1
ora.rac1.ons application ONLINE ONLINE rac1
ora.rac1.vip application ONLINE ONLINE rac1
ora....SM2.asm application ONLINE ONLINE rac2
ora....C2.lsnr application ONLINE ONLINE rac2
ora.rac2.gsd application ONLINE ONLINE rac2
ora.rac2.ons application ONLINE ONLINE rac2
ora.rac2.vip application ONLINE ONLINE rac2
利于-p选项,获得资源配置属性。
[root@rac2 bin]# crs_stat -p ora.rac2.vip
NAME=ora.rac2.vip
TYPE=application
ACTION_SCRIPT=/opt/oracle/product/10.2.0/crs_1/bin/racgwrap
ACTIVE_PLACEMENT=1
AUTO_START=1
CHECK_INTERVAL=60
DESCRIPTION=CRS application for VIP on a node
…………………………………………
USR_ORA_STOP_MODE=immediate
USR_ORA_STOP_TIMEOUT=0
USR_ORA_VIP=192.168.18.112
利用-p参数,获得资源权限。
[root@rac2 bin]# crs_stat -ls|grep vip
ora.rac1.vip root oinstall rwxr-xr—
ora.rac2.vip root oinstall rwxr-xr--
主要参数有-t/-v/-p/-ls/-f等。具体可以参见crs_stat –h
集群资源启动/停止CRS_START/CRS_STOP
这组命令主要负责各个节点上resources的启动/停止。可以针对全局资源(例如:crs_stop –all,表示停止所有节点上的resources),也可以针对节点上的某个特定的资源(例如:crs_start ora.rac2.ons,表示启动节点rac2上的ONS)。
集群资源配置CRS_REGISTER/CRS_UNREGISTER/CRS_PROFILE/CRS_SETPERM
这组命令主要负责集群资源的添加删除以及配置。
CRS_PROFILE:用来生成resource的profile文件(当然我们也可以手动编辑或者通过现有生成),默认存放路径$ORA_CRS_HOME/crs/profile目录下,加参数-dir 手动指定目录。默认名称为resource_name.cap.
crs_profile -create resource_name -t application –a .. –r .. –o..
表3.1为 crs_profile中参数配置说明(比较多,挑一些说吧):
|
参数名称 |
说明 |
参数指令(以create为例) |
|
NAME |
资源名称 |
crs_profile –create resource_name |
|
TYPE |
资源类型(application, generic) |
crs_profile – create resource_name –t … |
|
ACTION_SCRIPT |
用来管理HA方案脚本 |
crs_profile – create resource_name –a … |
|
ACTIVE_PLACEMENT |
资源贮存的位置/节点 |
crs_profile –create resource_name –o –ap … |
|
AUTO_START |
资源自启动 |
crs_profile –create resource_name –o –as … |
|
CHECK_INTERVAL |
资源监控间隔 |
crs_profile –create resource_name –o –ci … |
|
FAILOVER_DELAY |
资源failover的等待时间 |
crs_profile –create resource_name –o –fd … |
|
FAILURE_INTERVAL |
资源重启尝试间隔 |
crs_profile –create resource_name –o –fi … |
|
FAILURE_THRESHOLD |
资源重启尝试次数(最大20次) |
crs_profile –create resource_name –o –ft … |
|
HOSTING_MEMBERS |
资源启动或者failover的首要节点选择 |
crs_profile –create resource_name –h … |
|
PLACEMENT |
资源启动或者failover的节点选择模式(balanced,balanced,balanced) |
crs_profile – create resource_name -p |
|
REQUIRED_RESOURCES |
当前资源所依赖的资源 |
crs_profile – create resource_name -r |
|
RESTART_ATTEMPTS |
资源重配置之前的尝试启动次数 |
crs_profile –create resource_name –o –ra … |
|
SCRIPT_TIMEOUT |
等待ACTION_SCRIPT的结果返回时间 |
crs_profile –create resource_name –o –st … |
|
USR_ORA_VIP |
Vip地址 |
crs_profile –create vip_name -t application –a $ORA_CRS_HOME/bin/uservip –o oi=…,ov=…,on=… |
crs_profile -update resource_name … 用来更新现有profile(更新的只是profile,而并不是对已经注册到crs里面的资源属性的更改)
crs_register负责将resource的注册到OCR。注册的方法是先生成profile,然后运行
crs_register resource [-dir …]命令,同时,crs_register也具有update resource功能,具体办法可以更新resource对应的profile文件,然后运行crs_register -u resource_name [-dir …] 或者直接发布crs_register –update resource_name …
比如,我将rac节点上的vip改为手动启动。
[root@rac1 crs]# crs_register -update ora.rac1.vip -o as=0
[root@rac1 crs]# crs_stat -p ora.rac1.vip|grep AUTO_START
AUTO_START=0
crs_unregister负责将resource从ocr中移除。必要时候需要加-f参数。
crs_setperm用来设置resource的权限(诸如设置owner,用户的读写权限等),更改owner用-o参数,更改group用-g,更改用户权限用-u,在此不多举例了。
<2>.CRSCTL
用crsctl check crs,检查crs的健康情况。
[root@rac1 ~]# crsctl check crs
CSS appears healthy
CRS appears healthy
EVM appears healthy
用crsctl控制CRS服务
crsctl start|stop|enable|disable crs
用crsctl启动/停止resource
[root@rac1 ~]# crsctl stop resources
Stopping resources.
Successfully stopped CRS resources
[root@rac1 ~]# crsctl start resources
Starting resources.
Successfully started CRS resources
用crsctl检查以及添加、删除voting disk
下面讲述。
更多参见crsctl help。
<3>SRVCTL
SRVCTL是一个强大的CRS和RDBMS的管理配置工具。相关用法参照srvctl -h
(1) srvctl add/delete .. 添加删除资源。譬如我们在进行数据库单实例迁移到rac的时候,可以用这个工具手工注册database或者asm实例到OCR。
(2) srvctl status … 资源的状态监测
(3) srvctl start/stop … 资源的启动/停止,这个可以和crs_start/crs_stop互交使用。
(4) srvctl modify .. 重新定义资源的属性
………………………………………………………..
(2).OCR的管理维护
<1> OCR的状态验证:
可以使用ocrcheck工具来验证OCR的状态以及空间使用情况。在Lunix下,/etc/oracle/ocr.loc文件记录了OCR使用的设备情况。
[root@rac1]# ocrcheck
Status of Oracle Cluster Registry is as follows :
Version : 2
Total space (kbytes) : 497896
Used space (kbytes) : 3996
Available space (kbytes) : 493900
ID : 958197763
Device/File Name : /dev/raw/raw5
Device/File integrity check succeeded
Device/File not configured
Cluster registry integrity check succeeded
<2> 在线添加/删除ocrmirror
OCR支持一个镜像,添加/删除镜像可以在线完成,主要在某个online的节点上执行命令即可。
[root@rac1]#ocrconfig -replace ocrmirror /dev/raw/raw5
[root@rac1 oracle]# cat /etc/oracle/ocr.loc
#Device/file getting replaced by device /dev/raw/raw5
ocrconfig_loc=/dev/raw/raw1
ocrmirrorconfig_loc=/dev/raw/raw5
可见,ocr.loc被自动更新。
移除ocr或者镜像的时候,只要不带路径,即可。
当一个crs中存在ocr和镜像的时候,如果移除ocr,镜像会自动转变成ocr的角色。
[root@rac1]# ocrconfig -replace ocr
[root@rac1]# cat /etc/oracle/ocr.loc
#Device/file /dev/raw/raw1 being deleted
ocrconfig_loc=/dev/raw/raw5
可以看到现在的ocrconfig_loc自动变为先前的ocrmirrorconfig_loc设备。
<3> 逻辑备份/恢复
备份命令:
ocrconfig –export [ path ]
还原命令
ocrconfig –import [ path ]
还原OCR的时候,需要停掉各节点crs服务。还原完成后,重新启动CRS。(如果有必要,注意在每个节点分别修改ocr.loc的对应使用设备)
<4> 物理备份/恢复
CRSD负责每4个小时进行一次OCR的备份,默认备份路径在$ORA_CRS_HOME/cdate/crs下,
可以使用ocrConfig –showbackup查看备份情况,如果想更改物理备份路径,可以使用ocrconfig –backuploc [ path ] 来完成
物理恢复命令:
ocrconfig –restore [ path ]
同样,还原OCR的时候,需要停掉各节点crs服务。还原完成后,重新启动CRS。(如果有必要,注意在每个节点分别修改ocr.loc的对应使用设备)
<5> ocrdump
ocrdump可以将ocr信息导出成ascii文本,用于给Oracle Supoort提供检修。
命令如下:
ocrdump
(3).Voting disk管理维护
Voting disk的维护相对简单些。
<1> Votingdisk 状态查询
[root@rac1]# crsctl query css votedisk
0 /dev/raw/raw2
located 1 votedisk(s).
<2>在线添加、删除votingdisk
Oracle建议配置奇数个votingdisk,添加/删除可以在线完成,在某个online的节点上执行命令即可。
添加votingdisk命令:
crsctl add css votedisk [path] -force
删除votingdisk命令:
crsctl add css votedisk [path] -force
<3>votingdisk备份恢复
备份、恢复采用dd命令。恢复的时候,注意停掉各节点上的CRS服务。
2.RDBMS管理维护
(1).spfile以及相关参数说明
最普遍情况,节点共用同一个spfile文件,放置在共享存储上,而每个节点上,相应目录下有一个pfile文件,而这个pfile文件指向共享存储上的spfile。
当我们需要修改某一节点上的paremeter的时候,需要显示的指定sid,例如:
SQL>alter system set sga_target=1024M scope=spfile sid=’rac1’;
System Altered.
这样,节点rac1上的sga_target参数被修改,不会影响其余节点上的参数设置。如果不加sid,默认为sid=’*’,也就是对所有节点生效。
RAC下,有一些不同与单实例的参数,列举如下:
① cluster_database
一般情况下,该参数在rac各实例下应该设置为true。在一些特别情况下,比如upgrade等,需要将该参数设置成false。
② db_name/db_unique_name/instance_name
各节点db_name需要一致,db_unique_name也需要一致(这与standby是不同的)。而instance_name配置成各个节点的实例名称。
③ instance_number
该参数表示节点上实例的实例号。
④ thread
该参数用来标示实例使用的redo线程。线程号与节点号/实例号没有直接关联。
⑤ local_listener
该参数用来手工注册监听。为解决ORA-12514错误,可以设置该参数。
⑥ remote_listener
该参数用来进行服务器端负载均衡配置。
⑦ cluster_interconnects
该参数用来指定集群中IPC通信的网络。如果集群中有多种网络用于高速互联,需要配置该参数。对于多个IP地址,用冒号将其隔开。对于集群中当前使用的互联地址,可以查询视图gv$cluster_interconnects或着oradebug ipc来查看。
⑧ max_commit_propagation_delay
该参数用于配置SCN的产生机制。在rac下,SCN的同步有2种模式:(1) Lamport Scheme.该模式下,由GES管理SCN的传播同步,max_commit_propagation_delay表示SCN同步所允许的最大时间。在该模式下,全局SCN并非完全同步,这在高并发的OLTP系统中,可能会对应用造成一定的影响。(2) Broadcast on Commit scheme. 该模式下,一旦任何一个实例上事务发布commit,都立即同步SCN到全局。
在10g R1下,该参数默认数值为700,即采用Lamport Scheme模式。而在10g R2下,该参数默认数值为0,采用Broadcast on Commit scheme模式 (设置小于700的某一值,都将采用该模式) 。采用何种方式,可以从alert.log中获知。该参数值需要每个节点保持一致。
(2). Redo/Undo管理
?RAC下的Redo管理
同单实例的系统一样,每个节点实例都需要至少2组logfile。各节点实例有自己独立的重做日志线程(由初始化参数thread定义),例如:
SQL> select b.THREAD#,a.GROUP#,a.STATUS,a.MEMBER,b.BYTES,b.ARCHIVED,b.STATUS from v$logfile a,v$log b where a.GROUP#=b.GROUP#;
THREAD# GROUP# STATUS MEMBER BYTES ARCHIVED STATUS
------------------- ------- --------------------------------------------------
1 1 STALE +DATA/demo/onlinelog/group_1.257.660614753 52428800 YES INACTIVE
1 2 +DATA/demo/onlinelog/group_2.258.660614755 52428800 NO CURRENT
2 3 +DATA/demo/onlinelog/group_3.265.660615545 52428800 NO CURRENT
2 4 STALE +DATA/demo/onlinelog/group_4.266.660615543 52428800 YES INACTIVE
重做日志需要部署到共享存储中,必须保证可被所有的集群内的节点实例访问。当某个节点实例进行实例/介质恢复的时候,该节点上的实例将可以应用集群下所有节点实例上的重做日志文件(如果需要),从而保证恢复可以在任意可用节点进行。
?RAC下alter system switch logfile 与alter system archive log current 区别
alter system switch logfile仅对当前发布节点上的对应redo thread进行日志切换并归档。
alter system archive log current对集群内所有节点实例上的redo thread进行切换并归档(在节点实例可用情况下,分别归档到各节点主机的归档目的地,当节点不可用时候,该线程日志归档到命令发布节点的归档目的地)
?RAC下的Undo管理
RAC下的每个节点实例,也需要有自己单独的撤销表空间。由初始化参数 *.Undo_tablespace 指定。同REDO一样,UNDO表空间也需要部署到共享存储,虽然每个节点上UNDO的使用是独立的,但需要保证集群内其他节点实例对其访问,以完成构造读一致性等要求。
SQL>alter system set undo_tablespace=undo1 sid=’demo1’;
SQL>alter system set undo_tablespace=undo2 sid=’demo2’;
(3).Archivelog/flashback配置管理
在RAC下,Archivelog可以放置到本地磁盘,也可以放置到共享存储。需要对Archivelog的放置有合理的部署,如果放置到本地磁盘,会增加备份恢复的复杂程度。
闪回区必须部署到共享存储上,开启前,需要配置db_recovery_file_dest、db_recovery_file_dest_size、db_flashback_retention_target等参数。
下面在一个非归档非闪回的database上,开始归档与闪回。
?更改相关参数
SQL>alter system set log_archive_dest_1='location=/archive/demo1' sid='demo1';
System altered
SQL> alter system set log_archive_dest_1='location=/archive/demo2' sid='demo2';
System altered
SQL> alter system set db_recovery_file_dest_size=512M;
System altered
SQL> alter system set db_recovery_file_dest='+DG1';
System altered
?停掉所有节点实例.开启过程在一个实例上完成。
rac1-> srvctl stop instance -d demo -i demo1
rac1-> srvctl stop instance -d demo -i demo2
rac1-> sqlplus /nolog
SQL*Plus: Release 10.2.0.1.0 - Production on Sun Aug 3 22:06:50 2008
Copyright (c) 1982, 2005, Oracle. All rights reserved.
SQL> conn /as sysdba
Connected to an idle instance.
SQL> startup mount;
ORACLE instance started.
Total System Global Area 167772160 bytes
Fixed Size 1218316 bytes
Variable Size 100665588 bytes
Database Buffers 62914560 bytes
Redo Buffers 2973696 bytes
Database mounted.
SQL> alter database archivelog;
Database altered.
SQL> alter database flashback on;
Database altered.
SQL> alter database open;
Database altered.
SQL> select NAME,LOG_MODE,FLASHBACK_ON from v$database;
NAME LOG_MODE FLASHBACK_ON
--------- ------------ ------------------
DEMO ARCHIVELOG YES
10G下,开启归档和闪回并不需要像9i那样,设置初始化参数cluster_database=false.这无疑简化了操作。
(4).ASM下的RAC管理
?ASM下的参数文件
RAC下,每个节点上有运行有一个ASM实例,而rdbms instance就运行在这个asm实例上。Asm实例是本地的。同rdbms实例一样,他需要有参数文件,参数文件在每个节点的相应目录下。
下面是我的ASM实例下的pfile文件:
cluster_database=true
background_dump_dest=/opt/oracle/admin/+ASM/bdump
core_dump_dest=/opt/oracle/admin/+ASM/cdump
user_dump_dest=/opt/oracle/admin/+ASM/udump
instance_type=asm
large_pool_size=12M
remote_login_passwordfile=exclusive
asm_diskgroups='DG1'
+ASM2.instance_number=2
+ASM1.instance_number=1
简单介绍几个asm实例中比较重要的参数:
instance_type:用来说明实例是ASM 还是RDBMS 类型
asm_diskgroups:ASM磁盘组,asm实例启动的时候会自动mount
asm_diskstring:该参数用来说明能够创建diskgroup的磁盘设备,默认值是NULL
asm_power_limit:该参数用来设置进程 ARBx 的数量,负责控制负载平衡操作的速度。取值 从 0 到 11。默认值为1。
?用于记录ASM实例信息的数据字典。
V$ASM_DISK/ V$ASM_DISK_STAT:记录可以被ASM实例识别的磁盘信息,但这些磁盘并不一定是正在被实例使用的。
V$ASM_DISKGROUP/ V$ASM_DISKGROUP_STAT:记录asm下的diskgroup信息。
V$ASM_ALIAS:记录diskgroup文件的别名信息。
V$ASM_FILE:记录diskgroup中的文件信息。
V$ASM_OPERATION:记录ASM实例中当前运行的一个长时间操作信息。
V$ASM_TEMPLATE:记录diskgroup模板。
V$ASM_CLIENT:记录使用该asm实例下的diskgroup的rdbms实例信息。
?RAC下ASM磁盘组/文件管理操作
<1>.RAC下在线添加、删除磁盘组
在一个节点上添加diskgroup,集群上另外的节点并不会自动mount新添加的diskgroup,需要手动执行。
节点1:
SQL> show parameter asm_diskgroups
NAME TYPE VALUE
------------------------------------ -----------
asm_diskgroups string DATA, DG1
SQL>CREATE DISKGROUP DATA2 NORMAL REDUNDANCY
FAILGROUP DATA2_gp1 DISK '/dev/raw/raw6' FAILGROUP DATA2_gp2 DISK '/dev/raw/raw7';
Diskgroup created.
SQL> show parameter asm_diskgroups
NAME TYPE VALUE
------------------------------------ -----------
asm_diskgroups string DATA, DG1, DATA2
此时观察节点2,新加的磁盘组没有被mount。
SQL> show parameter asm_diskgroups
NAME TYPE VALUE
-----------------------------------------------
asm_diskgroups string DATA, DG1
SQL>select group_number,type,state,type,total_mb,free_mb from v$asm_diskgroup_stat;
GROUP_NUMBER STATE TYPE TOTAL_MB FREE_MB
--------------- --------------- ------------------------
1 CONNECTED EXTERN 5726 4217
2 CONNECTED EXTERN 415 297
0 DISMOUNTED 0 0
SQL>alter diskgroup DATA2 mount;
删除diskgroup时,保留一个节点diskgroup为mount状态,将其余节点上的diskgroup dismount,然后执行删除命令。
<2>.在线添加、删除磁盘
RAC下在线添加磁盘与删除磁盘与单实例并不差别。需要注意该操作会引起磁盘组的重新平衡,并确保删除磁盘的时候该磁盘组有足够的剩余空间。
节点1:
SQL> alter diskgroup dg6 add disk '/dev/raw/raw7' name dg6_disk7;
Diskgroup altered.
节点2上查询:
SQL>select GROUP_NUMBER,path,NAME,MOUNT_STATUS,HEADER_STATUS,MODE_STATUS,STATE from v$asm_disk_stat where NAME is not null;
GROUP_NUMBER PATH NAME MOUNT_S HEADER_STATU MODE_ST STATE
------------ ---------------- ---------- ------- ------------ -------
1 /dev/raw/raw3 DATA_0000 CACHED MEMBER ONLINE NORMAL
2 /dev/raw/raw4 DG1_0000 CACHED MEMBER ONLINE NORMAL
3 /dev/raw/raw6 DG6_0001 CACHED MEMBER ONLINE NORMAL
3 /dev/raw/raw7 DG6_DISK7 CACHED MEMBER ONLINE NORMAL
删除磁盘在某一节点操作即可,不做举例验证。
关于ASM的更多管理命令,就不多列举了。
3.Database备份/恢复
RAC下的备份恢复跟单实例的备份恢复实质上没有太大的差别,需要注意的是备份/恢复的时候当前节点对所有数据文件/归档日志的可见。在一个数据文件和归档日志全部放在共享存储上的RAC系统,备份与恢复过程与单实例下的几乎一样。而归档日志如果采用的是本地磁盘,就需要另加注意。下面分别来模拟这个备份恢复过程。
(1).Archivelog对各节点可见的备份/恢复
在这种模式下,备份恢复可以在任意一个可用节点执行即可,跟单实例并不太大区别。
?对database进行备份
RMAN>run{allocate channel orademo type disk;
backup database format '/backup/database/db_%s_%p_%t' plus archivelog format '/backup/database/arch_%s_%p_%t' delete input;
backup current controlfile format '/backup/database/contr_%s_%p_%t';}
allocated channel: orademo
channel orademo: sid=130 instance=demo2 devtype=DISK
Starting backup at 03-MAY-08
current log archived
channel orademo: starting archive log backupset
channel orademo: specifying archive log(s) in backup set
input archive log thread=1 sequence=5 recid=70 stamp=661823848
input archive log thread=1 sequence=6 recid=72 stamp=661823865
……………………………………..
Finished backup at 03-MAY-08
released channel: orademo
?添加数据,用于测试恢复效果
SQL> create table kevinyuan.test_b as select * from dba_data_files;
Table created
SQL> alter system switch logfile;
System altered
SQL> insert into kevinyuan.test_b select * from dba_data_files;
6 rows inserted
SQL> commit;
Commit complete
SQL> select count(*) from kevinyuan.test_b;
COUNT(*)
12
?模拟故障/恢复
RMAN> run {restore controlfile from '/backup/database/contr_16_1_661823935';
sql 'alter database mount';
restore database;
recover database;
sql 'alter database open resetlogs'; }
Starting restore at 04-MAY-08
allocated channel: ORA_DISK_1
…………………………………………………………………………..
archive log filename=+DATA/demo/onlinelog/group_4.266.660615543 thread=2 sequence=11
archive log filename=+DATA/demo/onlinelog/group_3.265.660615545 thread=2 sequence=12
media recovery complete, elapsed time: 00:00:00
Finished recover at 04-MAY-08
sql statement: alter database open resetlogs
?恢复完毕,来看一下验证数据:
SQL> select count(*) from kevinyuan.test_b;
COUNT(*)
12
(2). Archivelog对各节点不可见的备份/恢复
如果arhivelog采用本地磁盘,归档日志并不是对任意节点可见。备份archivelog的时候,如果采用和上述类似的备份方案,必然会导致一些归档日志由于无法access而抛出异常。可以采取如下的备份方式,目的就是使得备份通道能够access所有的数据字典中记录的归档日志信息。
恢复的时候,copy所有节点产生的相关备份片/集和归档日志文件到待恢复节点,在一个节点上执行restore/recover操作即可。
模拟一下这个操作。
SQL> alter system set log_archive_dest_1='location=/archive/demo1/' sid='demo1';
System altered
SQL> alter system set log_archive_dest_1='location=/archive/demo2/' sid='demo2';
System altered
(1)备份数据库
RMAN>run{allocate channel orademo1 type disk connect sys/kevinyuan@demo1;
allocate channel orademo2 type disk connect
sys/kevinyuan@demo2;
backup database format '/backup/database/db_%s_%p_%t'
plus archivelog format '/backup/database/arch_%s_%p_%t' delete
input;
backup current controlfile format
'/backup/database/contr_%s_%p_%t;}
allocated channel:
orademo1
channel orademo1: sid=133 instance=demo1 devtype=DISK
allocated
channel: orademo2
channel orademo2: sid=151 instance=demo2
devtype=DISK
Starting backup at 04-MAY-08
current log archived
channel
orademo2: starting archive log backupset
channel orademo2: specifying archive
log(s) in backup set
input archive log thread=2 sequence=4 recid=89
stamp=661826286
………………………………………………………………….
channel orademo1: finished
piece 1 at 04-MAY-08
piece handle=/backup/database/contr_28_1_661826504
tag=TAG20080504T004130 comment=NONE
channel orademo1: backup set complete,
elapsed time: 00:00:09
Finished backup at 04-MAY-08
released channel:
orademo1
released channel:
orademo2
(2)COPY节点2上的备份文件/归档日志文件到节点1相应目录下。
rac2-> scp /backup/database/* rac1:/backup/database/
rac2-> scp /archive/demo2/* rac1:/archive/demo1
(3)恢复database
RMAN>run{restore controlfile from '/backup/database/contr_28_1_661826504';
sql 'alter database mount';
restore database;
recover database;
sql 'alter database open resetlogs';}
starting restore at 04-MAY-08
using target database
control file instead of recovery catalog
allocated channel:
ORA_DISK_1
channel ORA_DISK_1: sid=147 instance=demo1 devtype=DISK
channel
ORA_DISK_1: restoring control file
channel ORA_DISK_1: restore complete,
elapsed time: 00:00:20
…………………………………………………………………………………
archive log
filename=+DATA/demo/onlinelog/group_3.265.660615545 thread=2
sequence=7
archive log
filename=+DATA/demo/onlinelog/group_4.266.660615543
thread=2 sequence=8
media recovery complete, elapsed time:
00:00:06
Finished recover at 04-MAY-08
sql statement: alter database open
resetlogs
至此,恢复完成。
生产库的备份需要缜密部署与模拟测试,不同的数据库类型也需要制定不同的方案实现。对DATABASE来说,备份重于泰山,不能抱有任何侥幸心理。
Service.Failover and Load Balance
1.Service
服务是rac体系中相当重要的概念,它为应用提供高可用和多样化的解决方案。实际中,我们可以创建不同性质的service来满足我们应用的不同需求。
10gR2下,可以通过以下几个方式创建服务。
(1).使用dbca
(2).使用srvctl
node1->srvctl add service -d demo -s srv_1 -r node1 -a node2
node1-> srvctl start service -d demo -s srv_1
node1-> crs_stat –t
Name Type Target State Host
ora.demo.db application ONLINE ONLINE node1
ora….o1.inst application ONLINE ONLINE node1
ora….o2.inst application ONLINE OFFLINE
ora….rv_1.cs application ONLINE ONLINE node1
ora….mo1.srv application ONLINE ONLINE node1
SQL> show parameter service
NAME TYPE VALUE
———————————— ———– ———–
service_names string demo,srv_1
(3).使用dbms_service命令创建
10g提供了dbms_service用于管理服务并进行功能扩展.
SQL>EXEC DBMS_SERVICE.CREATE_SERVICE(SERVICE_NAME=>’srv_2′,NETWORK_NAME=>’ srv_2′);
PL/SQL procedure successfully completed
SQL> exec DBMS_SERVICE.START_SERVICE(service_name => ’srv_2′,instance_name => ‘demo1′);
PL/SQL procedure successfully completed
SQL> show parameter service
NAME TYPE VALUE
———————————— ———– ———–
service_names string demo,srv_2
(4).其他等..
不管采用哪种方式,实质都是通过修改service_names而向lisnter动态注册服务.
2. failover and load banance
RAC为应用提供了高性能和高可用的服务,对用户来讲,核心的功能便是failover与load banance.
(1)Failover
在10gR2版本里,Failover的实现方式有两种,一种是TAF(Transparent Application Failover), 一种是FCF(Fast Connection Failover).
TAF以及实现:
TAF是net层透明故障转移,是一种被动的故障转移方式, 依赖于VIP.可以通过客户端和服务器端配置taf的策略.
<1> client端taf配置
以下是一个简单的具有taf功能的tnsnames.ora 内容
demo =
(DESCRIPTION =
(FAILOVER=ON)
(ADDRESS=(PROTOCOL=TCP)(HOST=10.194.129.145)(PORT=1521))
(ADDRESS=(PROTOCOL=TCP)(HOST=10.194.129.146)(PORT=1521))
(CONNECT_DATA =
(SERVICE_NAME = demo)
(SERVER=DEDICATED)
(FAILOVER_MODE=(TYPE=SELECT)
(METHOD=BASIC)
(RETRIES=50)
(DELAY=5)
)
)
)
控制TAF策略的参数说明:
|
参数 |
描述 |
|
FAILOVER |
Failover控制开关(on/off),如果为off,不提供故障切换功能,但连接时会对address列表进行依次尝试,直到找到可用为止 |
|
TYPE |
两种类型:session /select Session: 提供session级别的故障切换。 Select:提供select级别的故障切换,切换过程对查询语句透明,但事物类处理需要回滚操作 |
|
METHOD |
两种类型:basic/preconnect Basic:client同时只连接一个节点,故障切换时跳转到另外节点 Preconnect:需要与backup同时使用,client同时连接到主节点和backup节点 |
|
BACKUP |
采用Preconnect模式的备用连接配置 |
|
RETRIES |
故障切换时重试次数 |
|
DELAY |
故障切换时重试间隔时间 |
<2> Server端TAF配置
10gR2提供Server端的TAF配置,需要调用dbms_service包来在实例上进行修改。
SQL> exec dbms_service.modify_service(service_name => ‘DEMO’,failover_method => ‘BASIC’,failover_type => ‘SELECT’,failover_retries => 180,failover_delay => 5);
客户端连接字符串修改成如下即可:
demo =
(DESCRIPTION =
(ADDRESS=(PROTOCOL=TCP)(HOST=10.194.129.145)(PORT=1521))
(ADDRESS=(PROTOCOL=TCP)(HOST=10.194.129.146)(PORT=1521))
(CONNECT_DATA =
(SERVICE_NAME = demo)
(SERVER=DEDICATED)
)
)
FCF及实现
FCF是10g引进的一种新的failover机制,它依靠各节点的ons进程,通过广播FAN事件来获得各节点的运行情况,是一种前摄性的判断,支持JDBC/OCI/ODP.NET
(1).ons配置
onsctl工具配置各节点的local /remote节点以及端口.配置文件路径:$ORACLE_HOME/opmn/ons.config.
使用 onsctl debug 跟踪ons进程是否正常运行。
(2).配置连接池(以jdbc为例)
需要连接池支持Implicit Connection Cache,设置FastConnectionFailoverEnabled=true.
将ojdbc14.jar / ons.jar等加入CLASSPATH.具体代码可以参见联机文档或metalink相关文档.
(2) Load Balance
10g的 load balance同前版本相比有了很大功能上的改进,依据Load Balancing Advisory,提供了Runtime Connection Load Balancing的策略,但个人认为这也是个相对矛盾所在。越是细化的负载均衡机制,越是有加重cache fusion的可能,这对rac的整体性能是个考验。
load balance主要有两种实现方式:一种是Connection Load Balancing(CLB),另外一种是Runtime Connection Load Balancing(RCLB)。
CLB分为客户端client-side和服务器端server-side两种。
client-side需要在tnsname.ora添加LOAD_BALANCE=ON来实现,提供基于平衡连接数的负载方案.
server-side需要修改remote_listener参数,让listener能监听到集群中的所有节点,通过PMON来收集节点上的负载信息。
FCF默认支持RCLB功能,RCLB通过load balancing advisory事件来对连接提供更好的服务。RCLB有两种负载平衡方案可供选择—-基于总体service name和基于总体Throughput。可以通过dbms_service来设置具体的goal方案。
SQL> exec dbms_service.modify_service(service_name => ‘TEST’, goal => DBMS_SERVICE.GOAL_SERVICE_TIME);
至于这两种方式的具体差异,在我的测试中,并没有得到明显的体现。
Load Balanc这部分是我存疑最多的地方,查阅了很多文档,说法不一,且没有翔实的案例证明,在此也希望有过研究的朋友们做指正。
RAC下其他维护实施相关/案例
本环节侧重一些RAC工程维护相关的实际案例,暂举例以下案例
1.集群中主机名的更改
2.集群中IP地址的更改
3.集群中节点的添加/删除
4.升级:9i rac升级10g rac
5.rac + dg 搭建
6.其他
<一> 集群中主机名的更改
以下为一个实际案例,下表为更改前后的主机名称对比
hostname:node1/node2 —-> td1/td2
private_name:node1_priv/node2_priv —-> td1_priv/td2_priv
vip_name:node1_vip/node2_vip —-> td1_vip/td2_vip
1.生成listener的cap文件
node1->crs_stat –p ora.node1.LISTENER_NODE1.lsnr>/home/oracle/ora.node1.LISTENER_NODE1.lsnr.cap
node1->crs_stat –p ora.node2.LISTENER_NODE2.lsnr>/home/oracle/ora.node2.LISTENER_NODE2.lsnr.cap
2.停掉所有的资源,备份ocr、votingdisk并重新格式化
备份OCR
[root@node1 backup]# ocrcheck
Status of Oracle Cluster Registry is as follows :
Version : 2
Total space (kbytes) : 104176
Used space (kbytes) : 4424
Available space (kbytes) : 99752
ID : 2042344313
Device/File Name : /dev/raw/raw1
Device/File integrity check succeeded
Device/File not configured
Cluster registry integrity check succeeded
[root@node1 init.d]# ocrconfig -export /backup/ocr_1.bak
备份votedisk
[root@node1 ~]# crsctl query css votedisk
0. 0 /dev/raw/raw110
located 1 votedisk(s).
[root@node1 ~]# dd if=/dev/raw/raw110 of=/backup/votedisk.bak
重新格式化
[root@td01 ~]# dd if=/dev/zero of=/dev/raw/raw1 bs=1024k count=1
[root@td01 ~]# dd if=/dev/zero of=/dev/raw/raw110 bs=1024k count=1
3.OS上修改hostname并编辑相关文件,重启主机(步骤略)
4.重新配置集群互信。(步骤略)
5.编辑$ORA_CRS_HOME/ install/rootconfig文件,修改以下为你实际的情况。
ORA_CRS_HOME=/opt/oracle/product/10.2.0/crs_1
CRS_ORACLE_OWNER=oracle
CRS_DBA_GROUP=oinstall
CRS_VNDR_CLUSTER=false
CRS_OCR_LOCATIONS=/dev/raw/raw1
CRS_CLUSTER_NAME=crs
CRS_HOST_NAME_LIST=td1,1,td2,2
CRS_NODE_NAME_LIST=td1,1,td2,2
CRS_PRIVATE_NAME_LIST=td1-priv,1,td2-priv,2
CRS_LANGUAGE_ID=’AMERICAN_AMERICA.WE8ISO8859P1′
CRS_VOTING_DISKS=/dev/raw/raw110
CRS_NODELIST=td1,td2
CRS_NODEVIPS=’td1/td1-vip/255.255.255.0/eth0,td2/td2-vip/255.255.255.0/eth0′
在每个节点依次执行:
[root@td2 install]# /opt/oracle/product/10.2.0/crs_1/install/rootconfig
Checking to see if Oracle CRS stack is already configured
Setting the permissions on OCR backup directory
Setting up NS directories
Oracle Cluster Registry configuration upgraded successfully
WARNING: directory ‘/opt/oracle/product/10.2.0′ is not owned by root
WARNING: directory ‘/opt/oracle/product’ is not owned by root
WARNING: directory ‘/opt/oracle’ is not owned by root
WARNING: directory ‘/opt’ is not owned by root
clscfg: EXISTING configuration version 3 detected.
clscfg: version 3 is 10G Release 2.
Successfully accumulated necessary OCR keys.
Using ports: CSS=49895 CRS=49896 EVMC=49898 and EVMR=49897.
node :
node 1: td1 td1-priv td1
node 2: td2 td2-priv td2
clscfg: Arguments check out successfully.
NO KEYS WERE WRITTEN. Supply -force parameter to override.
-force is destructive and will destroy any previous cluster
configuration.
Oracle Cluster Registry for cluster has already been initialized
Startup will be queued to init within 30 seconds.
Adding daemons to inittab
Expecting the CRS daemons to be up within 600 seconds.
CSS is active on these nodes.
td1
td2
CSS is active on all nodes.
Waiting for the Oracle CRSD and EVMD to start
Oracle CRS stack installed and running under init(1M)
Running vipca(silent) for configuring nodeapps
Creating VIP application resource on (2) nodes…
Creating GSD application resource on (2) nodes…
Creating ONS application resource on (2) nodes…
Starting VIP application resource on (2) nodes…
Starting GSD application resource on (2) nodes…
Starting ONS application resource on (2) nodes…
如果是10.2.0.1 版本,在最后一个节点上执行的时候会因为vip的bug抛出异常,在该节点上调用VIPCA图形化界面。
这样gsd、ons和vip已经全部注册到OCR中。
[root@td1 install]# crs_stat –t
Name Type Target State Host
ora.td1.gsd application ONLINE ONLINE td1
ora.td1.ons application ONLINE ONLINE td1
ora.td1.vip application ONLINE ONLINE td1
ora.td2.gsd application ONLINE ONLINE td2
ora.td2.ons application ONLINE ONLINE td2
ora.td2.vip application ONLINE ONLINE td2
6.使用oifcfg配置共有/私连网络
td1-> oifcfg setif -global eth0/10.194.129.0:public
td1-> oifcfg setif -global eth2/10.10.10.0:cluster_interconnect
7.注册其他资源到集群
(1)注册监听到集群
修改监听配置文件lisntener.ora并编辑生成的cap文件(改名),更改其中用到的hostname.
td1-> crs_register ora.td1.LISTENER_TD1.lsnr -dir /home/oracle
td1-> crs_register ora.td2.LISTENER_TD2.lsnr -dir /home/oracle
或者使用netca图形化界面来配置监听.
(2)注册ASM实例到集群(如果使用ASM)
td1->srvctl add asm -n td1 -i ASM1 -o $ORACLE_HOME
td1->srvctl add asm -n td2 -i ASM2 -o $ORACLE_HOME
(3)注册instance/database到集群
td1->srvctl add database -d demo -o $ORACLE_HOME
td1->srvctl add instance -d demo -i demo1 -n td1
td1->srvctl add instance -d demo -i demo2 -n td2
验证:
td1-> crs_stat -t
Name Type Target State Host
————————————————————
ora.demo.db application ONLINE ONLINE td1
ora….o1.inst application ONLINE ONLINE td1
ora….o2.inst application ONLINE ONLINE td2
ora….SM1.asm application ONLINE ONLINE td1
ora….D1.lsnr application ONLINE ONLINE td1
ora.td1.gsd application ONLINE ONLINE td1
ora.td1.ons application ONLINE ONLINE td1
ora.td1.vip application ONLINE ONLINE td1
ora….SM2.asm application ONLINE ONLINE td2
ora….D2.lsnr application ONLINE ONLINE td2
ora.td2.gsd application ONLINE ONLINE td2
ora.td2.ons application ONLINE ONLINE td2
ora.td2.vip application ONLINE ONLINE td2
登陆数据库检查db使用的内连接链路
SQL> select * from v$cluster_interconnects;
NAME IP_ADDRESS IS_PUBLIC SOURCE
————— —————- ——— ——————————-
eth2 10.10.10.145 NO Oracle Cluster Repository
如果使用了OCFS作为共享文件格式,注意在启动数据库前检查相应OCFS的配置并确认ocfs是否能正常挂载使用。
2.集群中IP地址的更改
IP地址的更改比hostname的更改相对容易一些。对于同网段的public/private IP更改,无需进行特别操作。如果是不同网段,需要使用oifcfg处理。因为VIP是作为资源注册到OCR,所以任何VIP的改动都需调用相关命令进行处理。
以上处理都需要在集群资源停掉的基础上操作。
以下是修改前后的public/pricate/vip
Public IP 10.194.129.145/146 –> 10.194.128.145/146
Privite IP 10.10.10.145/146 –> 10.10.1.145/146
Virtual IP 10.194.129.147/148 –> 10.194.128.147/148
1.停掉各资源
数据库正常关库,其余资源使用crs_stop 停止。
2.重新修改网卡ip/gateway/host文件等,重启网络等相关服务
3.利用oifcfg更改public/private ip
查看当前使用
td1-> oifcfg getif
eth2 10.10.10.0 global cluster_interconnect
eth0 10.194.129.0 global public
删除当前
td1-> oifcfg delif -global eth0
td1-> oifcfg delif -global eth2
重新添加
td1-> oifcfg setif -global eth0/10.194.128.0:public
td1-> oifcfg setif -global eth2/10.10.1.0:cluster_interconnect
4.更新注册到OCR中的vip配置(root用户)
[root@td1 ~]# crs_register -update ora.td1.vip -o oi=eth0,ov=10.194.128.147,on=255.255.255.0
[root@td1 ~]# crs_register -update ora.td2.vip -o oi=eth0,ov=10.194.128.148,on=255.255.255.0
或者使用(root用户)
[root@td1 ~]# srvctl modify nodeapps -n td1 -A 10.194.128.147/255.255.255.0/eth0
[root@td1 ~]# srvctl modify nodeapps -n td2 -A 10.194.128.148/255.255.255.0/eth0
5.如果你使用了ocfs,修改ocfs配置文件(/etc/ocfs/cluster.conf),验证修改后是否可用
6.修改监听listener配置文件
7.启动集群各节点资源并验证
td1-> crs_start –all
登陆数据库,检验内连接是否生效。
SQL> select * from v$cluster_interconnects;
NAME IP_ADDRESS IS_PUBLIC SOURCE
————— —————- ——— —————————-
eth2 10.10.1.145 NO Oracle Cluster Repository
<三>.集群中节点的删除/添加
同9i的节点删除/添加相比,10g对节点的添加和删除相对来说略显麻烦,但操作起来更加规范。
因为集群件的存在,需调用一系列接口命令将资源从OCR中添加/删除,本文不再对该案例做详细描述,具体参见oracle官方联机文档RAC部分–Adding and Deleting Nodes and Instances on UNIX-Based Systems.
<四>.升级与迁移
RAC的迁移与升级并不比单实例复杂多少。对于一个rac新手来说,在思想上也无需觉得这是个很庞杂的事情,当然前提是你有足够的单实例方面的基础知识并对此深刻理解。
比如,利用rman备份,我们可以方便的将一个运行在单节点的实例迁移到rac环境下。需要做的重点,仅仅是迁移数据库(你可以想象成是单实例对单实例),然后编辑参数文件,添加其他节点启动db所必要的redo和undo,并注册数据库资源到集群中以便管理。
如果你的迁移或升级有停机时间的限制,那大部分情况下重点的问题并不在于被操作对象是RAC架构,而在于如何制定你的MAA策略。比如你需要运用一些表空间传输或者高级复制/流等方面的特性来压缩停机时间,这也许因为是RAC架构而增加了整个施工的难度,但很多时候问题的重点并不在于此。
接下来提供一个9I RAC同机静默升级到 10G RAC的案例,详细可参见我的一篇blog http://www.easyora.net/blog/9i_rac_upgrade_10g_rac.html
<五>.高可用架构:RAC+DG
应该说,rac+dg企业级的架构在高可用和灾备方面来说还是有相当大的市场。
在搭建与管理方面,rac(主)+DG(备)的过程与单实例的主备也无太大异同。需要注意以下方面(但不限于以下方面):
1.log gap的检测问题
注意正确配置fal_server与fal_clicent参数,尤其是对于rac主库归档到各自节点上的情况下,standby端gap server需要将每个主库节点都涵盖进去。
2.switchover/failover注意事项
做任何切换的时候,需要将rac端只保留一个alive的实例,其余实例关闭后,切换步骤跟单节点dg基本一致。
3.standby logfile问题
如果采用LGWR传输日志,需要备库端添加standby logfile日志。需要注意添加的standby logfile的thread要与主库一致。如果你的主库节点有3个实例,那需要添加3大组与rac主库相同thread号的备用日志,每个thread至少2组日志即可。
六、RAC监控优化
1.思路及等待事件说明
鉴于RAC体系的复杂性,RAC的优化比单实例的优化给我们提出了更高的难度和要求。大部分情况下,单实例上的优化方法在RAC结构下同样适用。
RAC优化的2个核心问题:
(1).减少shared pool的压力:减少对数据字典的争用,减少硬解析。
因为row cache/library cache是全局的,频繁的数据字典争用/硬解析在RAC环境下会造成比单实例更严重的性能后果。
(2).减少因Cache fusion带来的全局块传输和争用
频繁的Cache fusion会带来一系列数据块上的全局争用。如何减少逻辑读,减少数据在实例之间共享传输,是RAC体系对应用设计和部署的新要求
Cache fusion性能是影响RAC系统性能的一个极为重要的方面。Avg global cache cr block receive time和avg global cache current block receive time是cache fusion的两个重要指标,以下是oracle给出的这两个指标的阈值情况:
|
Name |
Lower Bound |
Typical |
Upper Bound |
|
Avg global cache cr block receive time(ms) |
0.3 |
4 |
12 |
|
Avg global cache current block receive time(ms) |
0.3 |
8 |
30 |
RAC下的全局等待事件:
SQL>select * from v$event_name where NAME like ‘gc%’ and WAIT_CLASS=’Cluster’;
10G R2下有40多个非空闲的全局等待时间,最常见的值得引起注意的等待事件如下:
gc current/cr request
该等待事件表示资源从远程实例读取到本地实例所花费的时间。出现该事件并不能说明什么问题,如果等待时间过长,可能表示内联网络存在问题或者有严重的块争用。
gc buffer busy
buffer busy waits在全局上的延伸。出现该等待时间一般可能是块的争用问题。
Enquenue类
RAC中,常见的Enquenue有enq: HW – contention/ enq: TX - index contention/enq等,在跨节点高并发的insert环境中很容易出现。
诸如gc current-2way/3way.gc current/cr grant等事件,这些事件只是提供了块传输和消息传输方面的细节或是结果,一般情况下无需太投入关注。
2.性能诊断
性能上的调整很难给出一个定式,但指导思想上可以实现很大方面的统一。
AWR/ASH等报告可以作为RAC系统中一个强有力的性能采集和诊断工具。同单实例的报告相比,AWR中的RAC Statistics部分给我们提供了详细的GES、GCS性能采样,结合全局等待事件,定位集群问题上的症状。
在RAC结构下,Segment Statistics部分是我们更加需要注意的地方。如果你还是习惯使用STATSPACK来进行性能采集,建议至少将收集级别设置为7。该部分为我们提供了详细的Segment级别的活动情况,有助于我们定位全局的HOT table /HOT index,分析全局资源排队争用的根源。
要重视DBA_HIS开头的一系列视图的作用,这将帮我们将问题定位的更加细化,甚至定位到SQL级别。糟糕的SQL效率拖垮系统性能的案例比比皆是,这在RAC中往往更加常见。dba_hist_active_sess_history 可以作为很好的切入点,例如通过关联dba_hist_sqltext获得执行文本,通过关联dba_hist_sql_plan获得执行计划树等,有时候将直接找到造成等待事件的元凶。
RAC中常见的争用和解决方法:
① Sequence and index contention
Sequence是RAC中容易引起争用的一个地方,尤其是以sequence作索引,在高并发的多节点insert情况下极易引起索引块的争用以及CR副本的跨实例传输。
需要尽量增大Sequence的cache值并设置序列为noorder。
② undo block considerations
RAC下CR的构造比单实例成本要高,如果一个block中的活动事务分布在几个实例上,需要将几个实例上的undo合并构造所需要的CR,尤其是高并发的有索引键的插入,容易造成undo block的争用。
尽量使用小事务处理。
③ HW considerations
跨节点的高并发insert会造成高水位线的争用,采用更大的extent/采用ASSM和分区技术能减缓这一争用。
④ Hot Block
全局热点块问题对RAC系统的影响巨大,尽量减少块跨实例的并发更改,适当采用分区可以缓解该争用。
一个良好的应用设计是RAC发挥功力的重要前提,根据不同的节点部署不同的应用,能有效的减少全局资源的争用,对RAC性能的稳定也相当重要。
服务硬件:指提供计算服务的硬件,比如 PC 机、PC 服务器。
服务实体:服务实体通常指服务软体和服务硬体。
节点(node):运行 Heartbeat 进程的一个独立主机称为节点,节点是 HA 的核心组成部分,每个节点上运行着操作系统和Heartbeat 软件服务。
资源(resource):资源是一个节点可以控制的实体,当节点发生故障时,这些资源能够被其他节点接管。如: 磁盘分区、文件系统、IP 地址、应用程序服务、共享存储
事件(event):事件也就是集群中可能发生的事情,例如节点系统故障、网络连通故障、网卡故障和应用程序故障等。这些事件都会导致节点的资源发生转移,HA 的测试也是基于这些事件进行的。
集群(cluster)就是一组计算机,它们作为一个整体向用户提供一组网络资源,这些单个的计算机系统就是集群的节点(node)。集群提供了以下关键的特性。
(一) 可扩展性。集群的性能不限于单一的服务实体,新的服务实体可以动态的加入到集群,从而增强集群的性能。
(二) 高可用性。集群通过服务实体冗余使客户端免于轻易遭遇到“out of service”警告。当一台节点服务器发生故障的时候,这台服务器上所运行的应用程序将在另一节点服务器上被自动接管。消除单点故障对于增强数据可用性、可达性和可靠性是非常重要的。
(三) 负载均衡。负载均衡能把任务比较均匀的分布到集群环境下的计算和网络资源,以便提高数据吞吐量。
(四) 错误恢复。如果集群中的某一台服务器由于故障或者维护需要而无法使用,资源和应用程序将转移到可用的集群节点上。这种由于某个节点中的资源不能工作,另一个可用节点中的资源能够透明的接管并继续完成任务的过程叫做错误恢复。
分布式与集群的联系与区别如下:
(一) 分布式是指将不同的业务分布在不同的地方。
(二) 而集群指的是将几台服务器集中在一起,实现同一业务。
(三) 分布式的每一个节点,都可以做集群,而集群并不一定就是分布式的。而分布式,从狭义上理解,也与集群差不多,但是它的组织比较松散,不像集群,有一定组织性,一台服务器宕了,其他的服务器可以顶上来。分布式的每一个节点,都完成不同的业务,一个节点宕了,这个业务就不可访问了。
集群主要分成三大类:
HA:高可用集群(High Availability Cluster)。
LBC:负载均衡集群/负载均衡系统(Load Balance Cluster)
HPC:科学计算集群(High Performance Computing Cluster)/高性能计算(High Performance Computing)集群。
随着经济的高速发展,企业规模的迅猛扩张,企业用户的数量、数据量的爆炸式增长,对数据库提出了严峻的考验。对于所有的数据库而言,除了记录正确的处理结果之外,还面临着以下几方面的挑战。
在数据库上,组建集群也是同样的道理,主要有以下几个原因:
(一) 伴随着企业的成长,业务量提高,数据库的访问量和数据量快速增长,其处理能力和计算速度也相应增大,使得单一的设备根本无法承担。
(二) 在以上情况下,若扔掉现有设备,做大量的硬件升级,势必造成现有资源的浪费,而且下一次业务量提升时,又将面临再一次硬件升级的高额投入。于是,人们希望通过几个中小型服务器组建集群,实现数据库的负载均衡及持续扩展;在需要更高数据库处理速度时,只要简单的增加数据库服务器就可以得到扩展。
(三) 数据库作为信息系统的核心,起着非常重要的作用,单一设备根本无法保证系统的下持续运行,若发生系统故障,将严重影响系统的正常运行,甚至带来巨大的经济损失。于是,人们希望通过组建数据库集群,实现数据库的高可用,当某节点发生故障时,系统会自动检测并转移故障节点的应用,保证数据库的持续工作。
(四) 企业的数据库保存着企业的重要信息,一些核心数据甚至关系着企业的命脉,单一设备根本无法保证数据库的安全性,一旦发生丢失,很难再找回来。于是,人们希望通过组建数据库集群,实现数据集的冗余,通过备份数据来保证安全性。
数据库集群技术是将多台服务器联合起来组成集群来实现综合性能优于单个大型服务器的技术,这种技术不但能满足应用的需要,而且大幅度的节约了投资成本。数据库集群技术分属两类体系:基于数据库引擎的集群技术和基于数据库网关(中间件)的集群技术。在数据库集群产品方面,其中主要包括基于数据库引擎的集群技术的 Oracle RAC、Microsoft MSCS、IBM DB2UDB、Sybase ASE,以及基于数据库网关(中间件)的集群技术的 ICX-UDS 等产品。
一般来讲,数据库集群软件侧重的方向和试图解决的问题划分为三大类:
只有 Oracle RAC 能实现以上三方面
(一) Oracle RAC:
其架构的最大特点是共享存储架构(Shared-storage),整个 RAC 集群是建立在一个共享的存储设备之上的,节点之间采用高速网络互联。OracleRAC 提供了非常好的高可用特性,比如负载均衡和应用透明切块(TAF),其最大的优势在于对应用完全透明,应用无需修改便可切换到RAC 集群。但是RAC 的可扩展能力有限,首先因为整个集群都依赖于底层的共享存储,所以共享存储的 I/O 能力和可用性决定了整个集群的可以提供的能力,对于 I/O 密集型的应用,这样的机制决定后续扩容只能是 Scale up(向上扩展)类型,对于硬件成本、开发人员的要求、维护成本都相对比较高。Oracle显然也意识到了这个问题,在 Oracle 的 MAA(Maximum Availability Architecture)架构中,采用 ASM 来整合多个存储设备的能力,使得 RAC 底层的共享存储设备具备线性扩展的能力,整个集群不再依赖于大型存储的处理能力和可用性。
RAC 的另外一个问题是,随着节点数的不断增加,节点间通信的成本也会随之增加,当到某个限度时,增加节点可能不会再带来性能上的提高,甚至可能造成性能下降。这个问题的主要原因是 Oracle RAC 对应用透明,应用可以连接集群中的任意节点进行处理,当不同节点上的应用争用资源时,RAC 节点间的通信开销会严重影响集群的处理能力。所以对于使用 ORACLE RAC 有以下两个建议:
基于这个原因,Oracle RAC 通常在 DSS 环境(决策支持系统Decision Support System ,简称DSS)中可以做到很好的扩展性,因为 DSS 环境很容易将不同的任务分布在不同计算节点上,而对于 OLTP 应用(On-Line Transaction Processing联机事务处理系统),Oracle RAC 更多情况下用来提高可用性,而不是为了提高扩展性。
(二) MySQL Cluster
MySQL cluster 和 Oracle RAC 完全不同,它采用 无共享架构Shared nothing(shared nothing architecture)。整个集群由管理节点(ndb_mgmd),处理节点(mysqld)和存储节点(ndbd)组 成,不存在一个共享的存储设备。MySQL cluster 主要利用了 NDB 存储引擎来实现,NDB 存储引擎是一个内存式存储引擎,要求数据必须全部加载到内存之中。数据被自动分布在集群中的不同存 储节点上,每个存储节点只保存完整数据的一个分片(fragment)。同时,用户可以设置同一份数据保存在多个不同的存储节点上,以保证单点故障不会造 成数据丢失。MySQL cluster 主要由 3 各部分组成:
这样的分层也是与 MySQL 本身把 SQL 处理和存储分开的架构相关系的。MySQL cluster 的优点在于其是一个分布式的数据库集群,处理节点和存储节点都可以线性增加,整个集群没有单点故障,可用性和扩展性都可以做到很高,更适合 OLTP 应用。但是它的问题在于:
虽然 MySQL cluster 目前性能还不理想,但是 share nothing 的架构一定是未来的趋势,Oracle 接手 MySQL之后,也在大力发展 MySQL cluster,我对 MySQL cluster 的前景抱有很大的期待。
(三) 分布式数据库架构
MySQL 5 之后才有了数据表分区功能(Sharding), Sharding 不是一个某个特定数据库软件附属的功能,而是在具体技术细节之上的抽象处理,是水平扩展(Scale Out,亦或横向扩展、向外扩展)的解决方案,其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题。比如 Oracle 的 RAC 是采用共享存储机制,对于 I/O 密集型的应用,瓶颈很容易落在存储上,这样的机制决定后续扩容只能是 Scale Up(向上扩展) 类型,对于硬件成本、开发人员的要求、维护成本都相对比较高。Sharding 基本上是针对开源数据库的扩展性解决方案,很少有听说商业数据库进行 Sharding 的。目前业界的趋势基本上是拥抱 Scale Out,逐渐从 Scale Up 中解放出来。
Sharding 架构的优势在于,集群扩展能力很强,几乎可以做到线性扩展,而且整个集群的可用性也很高,部分节点故障,不会影响其他节点提供服务。Sharding 原理简单,容易实现,是一种非常好的解决数据库扩展性的方案。Sharding 并不是数据库扩展方案的银弹,也有其不适合的场景,比如处理事务型的应用它可能会造成应用架构复杂或者限制系统的功能,这也是它的缺陷所在。读写分离是架构分布式系统的一个重要思想。不少系统整体处理能力并不能同业务的增长保持同步,因此势必会带来瓶颈,单纯的升级硬件并不能一劳永逸。针对业务类型特点,需要从架构模式进行一系列的调整,比如业务模块的分割,数据库的拆分等等。集中式和分布式是两个对立的模式,不同行业的应用特点也决定了架构的思路。如互联网行业中一些门户站点,出于技术和成本等方面考虑,更多的采用开源的数据库产品(如 MYSQL),由于大部分是典型的读多写少的请求,因此为 MYSQL 及其复制技术大行其道提供了条件。而相对一些传统密集交易型的行业,比如电信业、金融业等,考虑到单点处理能力和可靠性、稳定性等问题,可能更多的采用商用数据库,比如DB2、Oracle 等。就数据库层面来讲,大部分传统行业核心库采用集中式的架构思路,采用高配的小型机做主机载体,因为数据库本身和主机强大的处理能力,数据库端一般能支撑业务的运转,因此,Oracle 读写分离式的架构相对MYSQL 来讲,相对会少。读写分离架构利用了数据库的复制技术,将读和 写分布在不同的处理节点上,从而达到提高可用性和扩展性的目的。最通常的做法是利用 MySQL Replication 技术,Master DB 承担写操作,将数据变化复制到多台 Slave DB上,并承担读的操作。这种架构适合 read-intensive 类型的应用,通过增加 Slave DB 的数量,读的性能可以线性增长。为了避免 Master DB 的单点故障,集群一般都会采用两台 Master DB 做双机热备,所以整个集群的读和写的可用性都非常高。除了 MySQL,Oracle 从 11g 开始提供 Active Standby 的功能,也具备了实现读写分离架构的基础。读写分离架构的缺陷在于,不管是 Master 还是 Slave,每个节点都必须保存完整的数据,如 果在数据量很大的情况下,集群的扩展能力还是受限于单个节点的存储能力,而且对于 Write-intensive 类型的应用,读写分离架构并不适合。
采用 Oracle 读写分离的思路,Writer DB 和 Reader DB 采用日志复制软件实现实时同步; Writer DB 负责交易相关的实时查询和事务处理,Reader DB 负责只读接入,处理一些非实时的交易明细,报表类的汇总查询等。同时,为了满足高可用性和扩展性等要求,对读写端适当做外延,比如 Writer DB 采用 HA 或者 RAC 的架构模式,目前,除了数据库厂商的 集群产品以外,解决数据库扩展能力的方法主要有两个:数据分片和读写分离。数据分片(Sharding)的原理就是将数据做水平切分,类似于 hash 分区 的原理,通过应用架构解决访问路由和Reader DB 可以采用多套,通过负载均衡或者业务分离的方式,有效分担读库的压力。
对于 Shared-nothing 的数据库架构模式,核心的一个问题就是读写库的实时同步;另外,虽然 Reader DB只负责业务查询,但并不代表数据库在功能上是只读的。只读是从应用角度出发,为了保证数据一致和冲突考虑,因为查询业务模块可能需要涉及一些中间处理,如果需要在数据库里面处理(取决与应用需求和设计),所以Reader DB 在功能上仍然需要可写。下面谈一下数据同步的技术选型问题:
能实现数据实时同步的技术很多,基于 OS 层(例如 VERITAS VVR),基于存储复制(中高端存储大多都支持),基于应用分发或者基于数据库层的技术。因为数据同步可能并不是单一的 DB 整库同步,会涉及到业务数据选择以及多源整合等问题,因此 OS 复制和存储复制多数情况并不适合做读写分离的技术首选。基于日志的 Oracle 复制技术,Oracle 自身组件可以实现,同时也有成熟的商业软件。选商业的独立产品还是 Oracle 自身的组件功能,这取决于多方面的因素。比如团队的相应技术运维能力、项目投入成本、业务系统的负载程度等。
采用 Oracle 自身组件功能,无外乎 Logical Standby、Stream 以及 11g 的 Physical Standby(Active Data Guard),对比来说,Stream 最灵活,但最不稳定,11g Physical Standby 支持恢复与只读并行,但由于并不是日志的逻辑应用机制,在读写分离的场景中最为局限。如果技术团队对相关技术掌握足够充分,而选型方案的处理能力又能支撑数据同步的要求,采用 Oracle 自身的组件完全可行。选择商业化的产品,更多出于稳定性、处理能力等考虑。市面上成熟的 Oracle 复制软件也无外乎几种,无论是老牌的 Shareplex,还是本土 DSG 公司的 RealSync 和九桥公司的 DDS,或是 Oracle 新贵 Goldengate,都是可供选择的目标。随着 GoldenGate 被 Oracle 收购和推广,个人认为 GoldenGate 在容灾、数据分发和同步方面将大行其道。当然,架构好一个可靠的分布式读写分离的系统,还需要应用上做大量设计,不在本文讨论范围内。
(四) CAP 和 BASE 理论
分布式领域 CAP 理论:
定理:任何分布式系统只可同时满足二点,没法三者兼顾。
忠告:架构师不要将精力浪费在如何设计能满足三者的完美分布式系统,而是应该进行取舍。
关系数据库的 ACID 模型拥有 高一致性 + 可用性 很难进行分区:
(五) 跨数据库事务
2PC (two-phase commit), 2PC is the anti-scalability pattern (Pat Helland) 是反可伸缩模式的,也就是说传统关系型数据库要想实现一个分布式数据库集群非常困难,关系型数据库的扩展能力十分有限。而近年来不断发展壮大的 NoSQL(非关系型的数据库)运动,就是通过牺牲强一致性,采用 BASE 模型,用最终一致性的思想来设计分布式系统,从而使得系统可以达到很高的可用性和扩展性。那么,有没有可能实现一套分布式数据库集群,既保证可用性和一致性,又可以提供很好的扩展能力呢?
BASE 思想的主要实现有按功能划分数据库 sharding 碎片BASE 思想主要强调基本的可用性,如果你需要 High 可用性,也就是纯粹的高性能,那么就要以一致性或容错性为牺牲,BASE 思想的方案在性能上还是有潜力可挖的。
目前,已经有很多分布式数据库的产品,但是绝大部分是面向 DSS 类型的应用,因为相比较 OLTP 应用,DSS 应用更容易做到分布式扩展,比如基于 PostgreSQL 发展的 Greenplum,就很好的解决了可用性和扩展性的问题,并且提供了很强大的并行计算能力。对于 OLTP 应用,业务特点决定其要求:高可用性,一致性, 响应时间短,支持事务和 join 等等。数据库和 NoSQL当越来越多的 NoSQL 产品涌现出来,它们具备很多关系型数据库所不具备的特性,在可用性和扩展性方面都可以做到很好。
第一,NoSQL 的应用场景非常局限,某个类型的 NoSQL 仅仅针对特定类型的应用场景而设计。而关系型数据库则要通用的多,使用 NoSQL 必须搞清楚自己的应用场景是否适合。
第二,利用关系型数据库配合应用架构, 比如 Sharding 和读写分离技术,同样可以搭建出具备高可用和扩展性的分布式数据库集群。
第三,关系型数据库厂商依然很强大,全世界有大量的 用户,需求必然会推动新的产品问世。
第四,硬件的发展日新月异,比如闪存的技术的不断成熟,未来闪存可以作为磁盘与内存之间的 cache,或者完 全替代磁盘。而内存价格越来越低,容量越来越大,In-memory cache 或 database 的应用越来越广泛,可以给应用带来数量级的性能提升。数据库面临的 IO 问题将被极大改善。
1 RAC(Real Application Clusters)
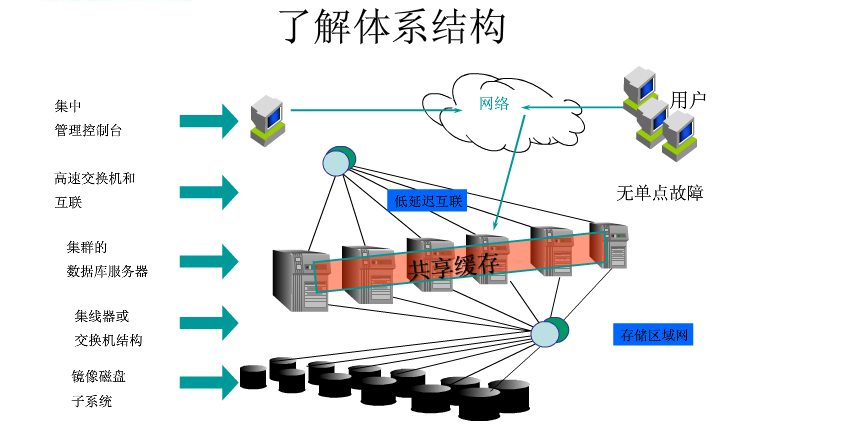
多个Oracle服务器组成一个共享的Cache,而这些Oracle服务器共享一个基于网络的存储。这个系统可以容忍单机/或是多机失败。不过系统内部的多个节点需要高速网络互连,基本上也就是要全部东西放在在一个机房内,或者说一个数据中心内。如果机房出故障,比如网络不通,那就坏了。所以仅仅用RAC还是满足不了一般互联网公司的重要业务的需要,重要业务需要多机房来容忍单个机房的事故。
2 Data Guard.(最主要的功能是冗灾)
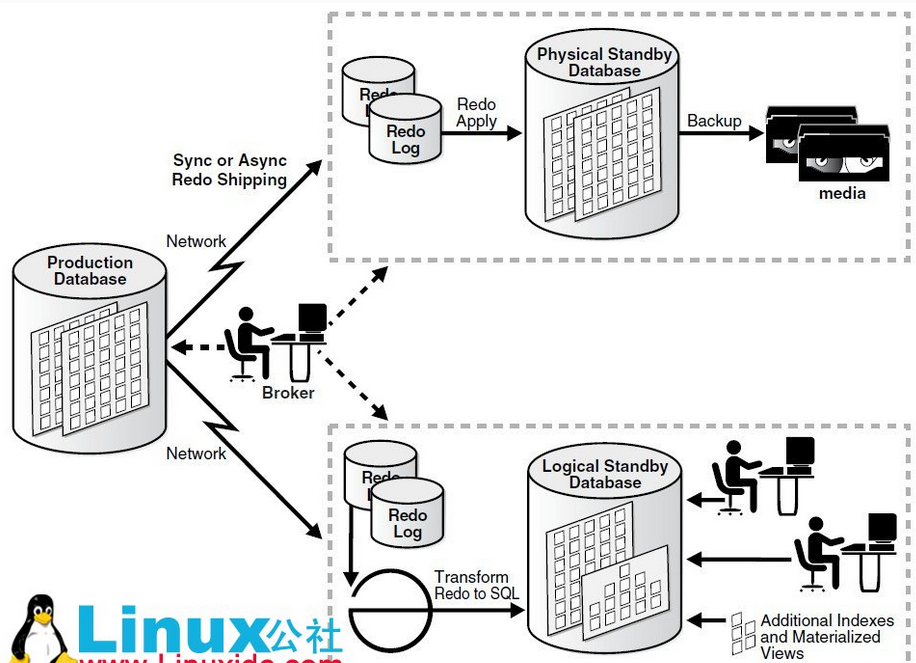
Data Guard这个方案就适合多机房的。某机房一个production的数据库,另外其他机房部署standby的数据库。Standby数据库分物理的和逻辑的。物理的standby数据库主要用于production失败后做切换。而逻辑的standby数据库则在平时可以分担production数据库的读负载。
3 MAA
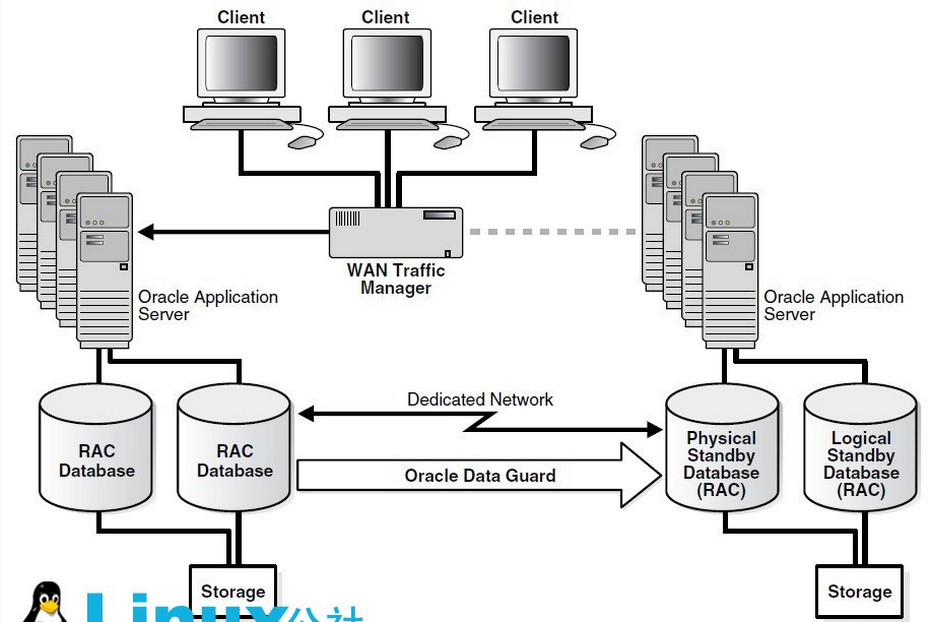
MAA(Maximum Availability Architecture)其实不是独立的第三种,而是前面两种的结合,来提供最高的可用性。每个机房内部署RAC集群,多个机房间用Data Guard同步。
共享存储文件系统(NFS),或甚至集群文件系统(如:OCFS2)主要被用于存储区域网络(所有节点直接访问共享文件系统上存储器),这就使得节点失效而不影响来自其他节点对文件系统的访问,通常,共享磁盘文件系统用于高可用集群。
Oracle RAC的核心是共享磁盘子系统,集群中所有节点必须能够访问所有数据、重做日志文件、控制文件和参数文件,数据磁盘必须是全局可用的,允许所有节点访问数据库,每个节点有它自己的重做日志和控制文件,但是其他节点必须能够访问它们以便在那个节点出现系统故障时能够恢复。
Oracle RAC 运行于集群之上,为 Oracle 数据库提供了最高级别的可用性、可伸缩性和低成本计算能力。如果集群内的一个节点发生故障,Oracle 将可以继续在其余的节点上运行。Oracle 的主要创新是一项称为高速缓存合并的技术。高速缓存合并使得集群中的节点可以通过高速集群互联高效地同步其内存高速缓存,从而最大限度地低降低磁盘 I/O。高速缓存最重要的优势在于它能够使集群中所有节点的磁盘共享对所有数据的访问。数据无需在节点间进行分区。Oracle 是唯一提供具备这一能力的开放系统数据库的厂商。其它声称可以运行在集群上的数据库软件需要对数据库数据进行分区,显得不切实际。企业网格是未来的数据中心,构建于由标准化商用组件构成的大型配置之上,其中包括:处理器、网络和存储器。Oracle RAC 的高速缓存合并技术提供了最高等级的可用性和可伸缩性。Oracle 数据库 10g 和 OracleRAC 10g 显著降低了运营成本,增强了灵活性,从而赋予了系统更卓越的适应性、前瞻性和灵活性。动态提供节点、存储器、CPU 和内存可以在实现所需服务级别的同时,通过提高的利用率不断降低成本。
Oracle RAC 10g 在 Oracle 数据库 10g 运行的所有平台上提供了一个完整集成的集群件管理解决方案。这一集群件功能包括集群连接、消息处理服务和锁定、集群控制和恢复,以及一个工作负载管理框架(将在下文探讨)。Oracle RAC 10g 的集成集群件管理具有以下优势:
(一) 成本低。Oracle 免费提供这一功能。
(二) 单一厂商支持。消除了相互推诿的问题。
(三) 安装、配置和持续维护更简单。Oracle RAC 10g 集群件使用标准 Oracle 数据库管理工具进行安装、配置和维护。这一过程无须其它的集成步骤。
(四) 所有平台,质量始终如一。与第三方产品相比,Oracle 对新软件版本进行了更严格的测试。
(五) 所有平台,功能始终如一。例如,一些第三方集群件产品限制了集群内可以支持的节点的数量。借助Oracle RAC 10g,所有平台可以支持多达 64 个节点。用户还可以在所有平台上获得一致的响应体验,从而有效解决了高可用性挑战,包括服务器节点故障、互连故障以及 I/O 隔离现象等。
(六) 支持高级功能。这包括集成监视和通知功能,从而在发生故障时,在数据库和应用层之间实现快速协调的恢复。
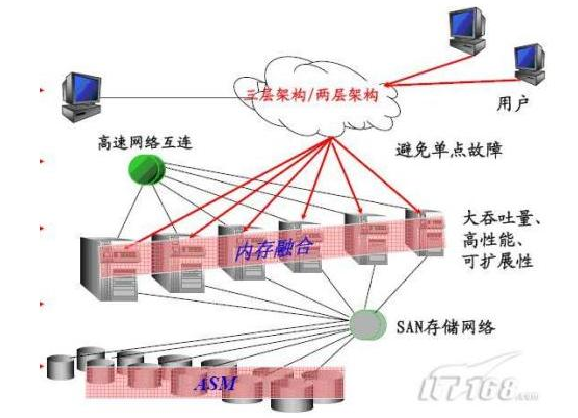
RAC 是 Oracle 数据库的一个群集解决方案,是有着两个或者两个以上的数据库节点协调运作能力的。如下图所示的 RAC 结构图:
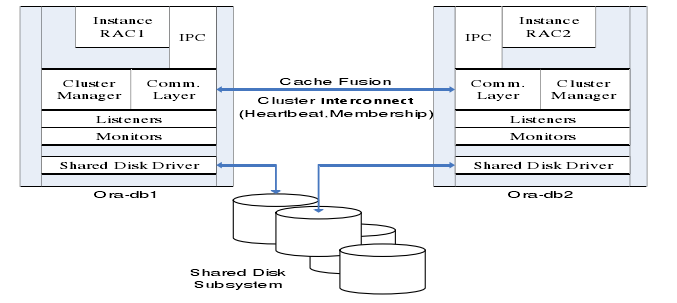
集群管理器(Cluster Manager)在集群系统中对其他各个模块进行整合,通过高速的内连接来提供群集节点之间的通信。各节点之间内连接使用心跳线互联,心跳线上的信息功能确定群集逻辑上的节点成员信息和节点更新情况,以及节点在某个时间点的运行状态,保证群集系统正常运行。通信层管理节点之间的通信。它的职责是配置,互联群集中节点信息,在群集管理器中使用由心跳机制产生的信息,由通信层负责传输,确保信息的正确到达。还有一些群集监视进程不断验证系统的不同领域运行状况。例如,心跳监测不断验证的心跳机制的运作是否良好。在一个应用环境当中,所有的服务器使用和管理同一个数据库,目的是分散每一台服务器的工作量。硬件上至少需要两台以上的服务器,而且还需要一个共享存储设备;同时还需要两类软件,一类是集群软件,另外一类就是 Oracle 数据库中的 RAC 组件。同时所有服务器上的 OS 都应该是同一类 OS,根据负载均衡的配置策略,当一个客户端发送请求到某一台服务的 listener 后,这台服务器根据负载均衡策略,会把请求发送给本机的 RAC组件处理,也可能会发送给另外一台服务器的 RAC 组件处理,处理完请求后,RAC 会通过群集软件来访问共享存储设备。逻辑结构上看,每一个参加群集的节点有一个独立的实例,这些实例访问同一个数据库。节点之间通过集群软件的通信层(Communication Layer)来进行通信。同时为了减少 I/O 的消耗,存在一个全局缓存服务,因此每一个数据库的实例,都保留了一份相同的数据库 cache。RAC 中的特点如下:
在 Oracle9i 之前,RAC 称为 OPS(Oracle Parallel Server)。RAC 与 OPS 之间的一个较大区别是,RAC 采用了Cache Fusion(高缓存合并)技术,节点已经取出的数据块更新后没有写入磁盘前,可以被另外一个节点更新,然后以最后的版本写入磁盘。在 OPS 中,节点间的数据请求需要先将数据写入磁盘,然后发出请求的节点才可以读取该数据。使用 Cache Fusion 时,RAC 的各个节点间数据缓冲区通过高速、低延迟的内部网络进行数据块的传输。下图是一个典型的 RAC 对外服务的示意图,一个 Oracle RAC Cluster 包含了如下的部分
Oracle RAC 有一些自己独特的后台进程,在单一实例中不发挥配置作用。如下图所示,定义了一些 RAC 运行的后台进程。这些后台进程的功能描述如下。
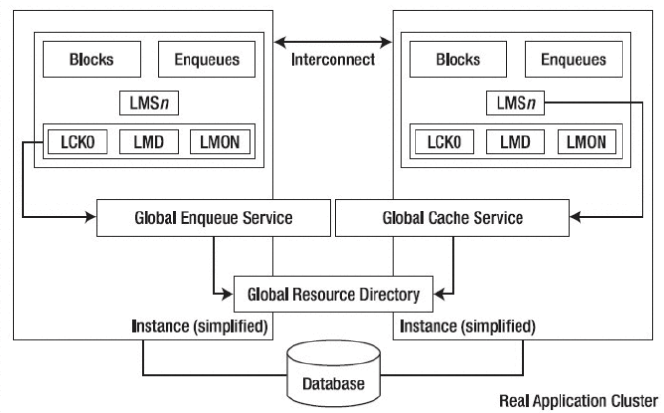
(1)LMS(Global cache service processes 全局缓存服务进程)进程主要用来管理集群内数据块的访问,并在不同实例的 Buffer Cache 中传输数据块镜像。直接从控制的实例的缓存复制数据块,然后发送一个副本到请求的实例上。并保证在所有实例的 Buffer Cache 中一个数据块的镜像只能出现一次。LMS 进程靠着在实例中传递消息来协调数据块的访问,当一个实例请求数据块时,该实例的 LMD 进程发出一个数据块资源的请求,该请求指向主数据块的实例的 LMD 进程,主实例的 LMD 进程和正在使用的实例的 LMD 进程释放该资源,这时拥有该资源的实例的 LMS 进程会创建一个数据块镜像的一致性读然后把该数据块传递到请求该资源的实例的BUFFER CACHE 中。LMS 进程保证了在每一时刻只能允许一个实例去更新数据块,并负责保持该数据块的镜像记录(包含更新数据块的状态 FLAG)。RAC 提供了 10 个 LMS 进程(0~9),该进程数量随着节点间的消息传递的数据的增加而增加。(2)LMON(Lock Monitor Process,锁监控进程)是全局队列服务监控器,各个实例的 LMON 进程会定期通信,以检查集群中各个节点的健康状况,当某个节点出现故障时,负责集群重构、GRD 恢复等操作,它提供的服务叫做 Cluster Group Service(CGS)。
LMON 主要借助两种心跳机制来完成健康检查。
(一) 节点间的网络心跳(Network Heartbeat):可以想象成节点间定时的发送 ping 包检测节点状态,如果能在规定时间内收到回应,就认为对方状态正常。
(二) 通过控制文件的磁盘心跳(controlfile heartbeat):每个节点的 CKPT 进程每隔 3 秒钟更新一次控制文件的数据块,这个数据块叫做 Checkpoint Progress Record,控制文件是共享的,所以实例间可以互相检查对方是否及时更新来判断。
(三) LMD(the global enqueue service daemon,锁管理守护进程)是一个后台进程,也被称为全局的队列服务守护进程,因为负责对资源的管理要求来控制访问块和全局队列。在每一个实例的内部,LMD 进程管理输入的远程资源请求(即来自集群中其他实例的锁请求)。此外,它还负责死锁检查和监控转换超时。
(四) LCK(the lock process,锁进程)管理非缓存融合,锁请求是本地的资源请求。LCK 进程管理共享资源的实例的资源请求和跨实例调用操作。在恢复过程中它建立一个无效锁元素的列表,并验证锁的元素。由于处理过程中的 LMS 锁管理的首要职能,只有一个单一的 LCK 进程存在每个实例中。
(五) DIAG(the diagnosability daemon,诊断守护进程)负责捕获 RAC 环境中进程失败的相关信息。并将跟踪信息写出用于失败分析,DIAG 产生的信息在与 Oracle Support 技术合作来寻找导致失败的原因方面是非常有用的。每个实例仅需要一个 DIAG 进程。
(六) GSD(the global service daemon,全局服务进程)与 RAC 的管理工具 dbca、srvctl、oem 进行交互,用来完成实例的启动关闭等管理事务。为了保证这些管理工具运行正常必须在所有的节点上先start gsd,并且一个 GSD 进程支持在一个节点的多个 rac.gsd 进程位ORACLEHOME/bin目录下,其log文件为ORACLEHOME/bin目录下,其log文件为ORACLE_HOME/srvm/log/gsdaemon.log。GCS 和 GES 两个进程负责通过全局资源目录(Global Resource Directory GRD)维护每个数据的文件和缓存块的状态信息。当某个实例访问数据并缓存了数据之后,集群中的其他实例也会获得一个对应的块镜像,这样其他实例在访问这些数据是就不需要再去读盘了,而是直接读取 SGA 中的缓存。GRD 存在于每个活动的 instance 的内存结构中,这个特点造成 RAC 环境的 SGA 相对于单实例数据库系统的 SGA 要大。其他的进程和内存结构都跟单实例数据库差别不大。
RAC 需要有共享存储,独立于实例之外的信息,如上面提到的ocr 和 votedisk 以及数据文件都存放在这个共享存储里的。有OCFS、OCFS2、RAW、NFS、ASM 等这样的一些存储方式。OCFS(Oracle Cluster File System) 和 OCFS2 就是一个文件系统而已,和 NFS 一样,提供一种集群环境中的共享存储的文件系统。RAW 裸设备也是一种存储方式,是 oracle11g 之前的版本中 RAC 支持的存储方式,在 Oralce9i 之前,OPS/RAC的支持只能使用这样的方式,也就是把共享存储映射到 RAW Device,然后把 Oracle 需要的数据选择 RAW device存储,但是 RAW 相对于文件系统来说不直观,不便于管理,而且 RAW Device 有数量的限制,RAW 显然需要有新的方案来代替,这样就有了 OCFS 这样的文件系统。当然,这只是 Oracle 自己的实现的集文件系统而已,还有其他厂商提供的文件系统可以作为存储的选择方案。ASM 只是数据库存储的方案而已,并不是 cluster 的方案,所以这里 ASM 应该是区别于 RAW 和 OCFS/OCFS2同一级别的概念,RAW 和 OCFS/OCFS2 不仅可以作为数据库存储的方案,同时也可以作为 Clusterware 里的存储方案,是 CRS 里需要的 storage,而 ASM 仅作为数据库的存储而已,严格来说仅是 RAC 中的一个节点应用(nodeapps)。ASM 对于 clusterware 安装时需要的 ocr 和 votedisk 这两项还不支持,毕竟 ASM 本身就需要一个实例,而 CRS 是完全在架构之外的,这也就是为什么使用了 ASM 的方案,却总还要加上 OCFS/OCFS2 和 RAW 其中的一个原因。各种 RAC 共享存储方式的对比如下:
为了让 RAC 中的所有实例能够访问数据库,所有的 datafiles、control files、PFILE/Spfile 和 redo log files 必须保存在共享磁盘上,并且要都能被所有节点同时访问,就涉及到裸设备和集群文件系统等。RAC database 在结构上与单实例的不同之处:至少为每个实例多配置一个 redo 线程,比如:两个实例组成的集群至少要 4 个 redo log group。每个实例两个 redo group。另外要为每一个实例准备一个 UNDO 表空间。
1、redo 和 undo,每个实例在做数据库的修改时谁用谁的 redo 和 undo 段,各自锁定自己修改的数据,把不同实例的操作相对的独立开就避免了数据不一致。后面就要考虑备份或者恢复时 redo log 和归档日志在这种情况下的特殊考虑了。
2、内存和进程各个节点的实例都有自己的内存结构和进程结构.各节点之间结构是基本相同的.通过 Cache Fusion(缓存融合)技术,RAC 在各个节点之间同步 SGA 中的缓存信息达到提高访问速度的效果也保证了一致性。
OracleRAC 是多个单实例在配置意义上的扩展,实现由两个或者多个节点(实例)使用一个共同的共享数据库(例如,一个数据库同时安装多个实例并打开)。在这种情况下,每一个单独的实例有它自己的 cpu 和物理内存,也有自己的 SGA 和后台进程。和传统的 oracle 实例相比,在系统全局区(SYSTEM CLOBAL AREA,SGA)与后台进程有着显著的不同。最大的不同之处在于多了一个GRD,GRD内存块主要是记录此rac有多少个集群数据库与系统资源,同时也会记录数据块的相关信息,因为在 rac 架构中,每个数据块在每一个 SGA 中都有一份副本,而 rac 必须知道这些数据块的位置,版本,分布以及目前的状态,这些信息就存放在 GRD 中,但 GRD 只负责存放不负责管理,管理的责任则交给后台进程 GCS 和 GES 来进行。Oracle 的多个实例访问一个共同的共享数据库。每个实例都有自己的 SGA、PGA 和后台进程,这些后台进程应该是熟悉的,因为在 RAC 配置中,每个实例将需要这些后台进程运行支撑的。可以从以下几个方面了解 RAC工作原理和运行机制。
(一) SCN
SCN 是 Oracle 用来跟踪数据库内部变化发生先后顺序的机制,可以把它想象成一个高精度的时钟,每个 Redo日志条目,Undo Data Block,Data Block 都会有 SCN 号。 Oracle 的Consistent-Read, Current-Read,Multiversion-Block 都是依赖 SCN 实现。在 RAC 中,有 GCS 负责全局维护 SCN 的产生,缺省用的是 Lamport SCN 生成算法,该算法大致原理是: 在所有节点间的通信内容中都携带 SCN, 每个节点把接收到的 SCN 和本机的 SCN 对比,如果本机的 SCN 小,则调整本机的 SCN 和接收的一致,如果节点间通信不多,还会主动地定期相互通报。 故即使节点处于 Idle 状态,还是会有一些 Redo log 产生。 还有一个广播算法(Broadcast),这个算法是在每个 Commit 操作之后,节点要想其他节点广播 SCN,虽然这种方式会对系统造成一定的负载,但是确保每个节点在 Commit 之后都能立即查看到 SCN.这两种算法各有优缺点,Lamport 虽然负载小,但是节点间会有延迟,广播虽然有负载,但是没有延迟。Oracle 10g RAC 缺省选用的是 BroadCast 算法,可以从 alert.log 日志中看到相关信息:Picked broadcast on commit scheme to generate SCNS
(二) RAC 的 GES/GCS 原理
全局队列服务(GES)主要负责维护字典缓存和库缓存的一致性。字典缓存是实例的 SGA 内所存储的对数据字典信息的缓存,用于高速访问。由于该字典信息存储在内存中,因而在某个节点上对字典进行的修改(如DDL)必须立即被传播至所有节点上的字典缓存。GES 负责处理上述情况,并消除实例间出现的差异。处于同样的原因,为了分析影响这些对象的 SQL 语句,数据库内对象上的库缓存锁会被去掉。这些锁必须在实例间进行维护,而全局队列服务必须确保请求访问相同对象的多个实例间不会出现死锁。LMON、LCK 和 LMD 进程联合工作来实现全局队列服务的功能。GES 是除了数据块本身的维护和管理(由 GCS 完成)之外,在 RAC 环境中调节节点间其他资源的重要服务。为了保证集群中的实例的同步,两个虚拟服务将被实现:全局排队服务(GES),它负责控制对锁的访问。
全局内存服务(GCS),控制对数据块的访问。GES 是 分布式锁管理器(DLM)的扩展,它是这样一个机制,可以用来管理 oracle 并行服务器的锁和数据块。在一个群集环境中,你需要限制对数据库资源的访问,这些资源在单 instance 数据库中被 latches 或者 locks 来保护。比如说,在数据库字典内存中的对象都被隐性锁所保护,而在库高速缓存中的对象在被引用的时候,必须被 pin 所保护。在 RAC 群集中,这些对象代表了被全局锁所保护的资源。GES 是一个完整的 RAC 组件,它负责和群集中的实例全局锁进行沟通,每个资源有一个主节点实例,这个实例记录了它当前的状态。而且,资源的当前的状态也记录在所有对这个资源有兴趣的实例上。GCS,是另一个 RAC 组件,负责协调不同实例间对数据块的访问。对这些数据块的访问以及跟新都记录在全局目录中(GRD),这个全局目录是一个虚拟的内存结构,在所有的实例中使用扩张。每个块都有一个master实例,这个实例负责对GSD的访问进行管理,GSD里记录了这个块的当前状态信息。GCS 是 oracle 用来实施 Cache fusion 的机制。被 GCS 和 GES 管理的块和锁叫做资源。对这些资源的访问必须在群集的多个实例中进行协调。这个协调在实例层面和数据库层面都有发生。实例层次的资源协调叫做本地资源协调;数据库层次的协调叫做全局资源协调。
本地资源协调的机制和单实例 oracle 的资源协调机制类似,包含有块级别的访问,空间管理,dictionary cache、library cache 管理,行级锁,SCN 发生。全局资源协调是针对 RAC 的,使用了 SGA 中额外的内存组件、算法和后台进程。GCS 和 GES 从设计上就是在对应用透明的情况下设计的。换一句话来说,你不需要因为数据库是在 RAC上运行而修改应用,在单实例的数据库上的并行机制在 RAC 上也是可靠地。
支持 GCS 和 GES 的后台进程使用私网心跳来做实例之间的通讯。这个网络也被 Oracle 的 群集组件使用,也有可能被 群集文件系统(比如 OCFS)所使用。GCS 和 GES 独立于 Oracle 群集组件而运行。但是,GCS 和GES 依靠 这些群集组件获得群集中每个实例的状态。如果这些信息不能从某个实例获得,这个实例将被关闭。这个关闭操作的目的是保护数据库的完整性,因为每个实例需要知道其他实例的情况,这样可以更好的确定对数据库的协调访问。GES 控制数据库中所有的 library cache 锁和 dictionary cache 锁。这些资源在单实例数据库中是本地性的,但是到了 RAC 群集中变成了全局资源。全局锁也被用来保护数据的结构,进行事务的管理。一般说来,事务和表锁 在 RAC 环境或是 单实例环境中是一致的。
Oracle 的各个层次使用相同的 GES 功能来获得,转化以及释放资源。在数据库启动的时候,全局队列的个数将被自动计算。GES 使用后台进程 LMD0 和 LCK0 来执行它的绝大多数活动。一般来说,各种进程和本地的 LMD0 后台进程沟通来管理全局资源。本地的 LMD0 后台进程与 别的实例上的 LMD0 进程进行沟通。
LCK0 后台进程用来获得整个实例需要的锁。比如,LCK0 进程负责维护 dictionary cache 锁。影子进程(服务进程) 与这些后台进程通过 AST(异步陷阱)消息来通信。异步消息被用来避免后台进程的阻塞,这些后台进程在等待远端实例的的回复的时候将阻塞。后台进程也能 发送 BAST(异步锁陷阱)来锁定进程,这样可以要求这些进程把当前的持有锁置为较低级限制的模式。资源是内存结构,这些结构代表了数据库中的组件,对这些组件的访问必须为限制模式或者串行化模式。换一句话说,这个资源只能被一个进程或者一直实例并行访问。如果这个资源当前是处于使用状态,其他想访问这个资源的进程必须在队列中等待,直到资源变得可用。队列是内存结构,它负责并行化对特殊资源的访问。如果这些资源只被本地实例需求,那么这个队列可以本地来获得,而且不需要协同。但是如果这个资源被远程实例所请求,那么本地队列必须变成全球化。
在单机环境下,Oracle 是运行在 OS Kernel 之上的。 OS Kernel 负责管理硬件设备,并提供硬件访问接口。Oracle 不会直接操作硬件,而是有 OS Kernel 代替它来完成对硬件的调用请求。在集群环境下, 存储设备是共享的。OS Kernel 的设计都是针对单机的,只能控制单机上多个进程间的访问。 如果还依赖 OS Kernel 的服务,就无法保证多个主机间的协调工作。 这时就需要引入额外的控制机制,在RAC 中,这个机制就是位于 Oracle 和 OS Kernel 之间的 Clusterware,它会在 OS Kernel 之前截获请求,然后和其他结点上的 Clusterware 协商,最终完成上层的请求。在 Oracle 10G 之前,RAC 所需要的集群件依赖与硬件厂商,比如 SUN,HP,Veritas. 从 Oracle 10.1版本中,Oracle推出了自己的集群产品. Cluster Ready Service(CRS),从此 RAC 不在依赖与任何厂商的集群软件。 在 Oracle 10.2版本中,这个产品改名为:Oracle Clusterware。所以我们可以看出, 在整个 RAC 集群中,实际上有 2 个集群环境的存在,一个是由 Clusterware 软件组成的集群,另一个是由 Database 组成的集群。
(一) Clusterware 的主要进程
a) CRSD——负责集群的高可用操作,管理的 crs 资源包括数据库、实例、监听、虚拟 IP,ons,gds 或者其他,操作包括启动、关闭、监控及故障切换。改进程由 root 用户管理和启动。crsd 如果有故障会导致系统重启。
b) cssd,管理各节点的关系,用于节点间通信,节点在加入或离开集群时通知集群。该进程由 oracle 用户运行管理。发生故障时 cssd 也会自动重启系统。
c) oprocd – 集群进程管理 —Process monitor for the cluster. 用于保护共享数据 IO fencing。
d) 仅在没有使用 vendor 的集群软件状态下运行
e) evmd :事件检测进程,由 oracle 用户运行管理
Cluster Ready Service(CRS,集群准备服务)是管理集群内高可用操作的基本程序。Crs 管理的任何事物被称之为资源,它们可以是一个数据库、一个实例、一个监听、一个虚拟 IP(VIP)地址、一个应用进程等等。CRS是根据存储于 OCR 中的资源配置信息来管理这些资源的。这包括启动、关闭、监控及故障切换(start、stop、monitor 及 failover)操作。当一资源的状态改变时,CRS 进程生成一个事件。当你安装 RAC 时,CRS 进程监控Oracle 的实例、监听等等,并在故障发生时自动启动这些组件。默认情况下,CRS 进程会进行 5 次重启操作,如果资源仍然无法启动则不再尝试。Event Management(EVM):发布 CRS 创建事件的后台进程。Oracle Notification Service(ONS):通信的快速应用通知(FAN:Fast Application Notification)事件的发布及订阅服务。RACG:为 clusterware 进行功能扩展以支持 Oracle 的特定需求及复杂资源。它在 FAN 事件发生时执行服务器端的调用脚本(server callout script)Process Monitor Daemon(OPROCD):此进程被锁定在内存中,用于监控集群(cluster)及提供 I/O 防护(I/Ofencing)。OPROCD 执行它的检查,停止运行,且如果唤醒超过它所希望的间隔时,OPROCD 重置处理器及重启节点。一个 OPROCD 故障将导致 Clusterware 重启节点。
Cluster Synchronization Service(CSS):CSS 集群同步服务,管理集群配置,谁是成员、谁来、谁走,通知成员,是集群环境中进程间通信的基础。同样,CSS 也可以用于在单实例环境中处理 ASM 实例与常规 RDBMS 实例之间的交互作用。在集群环境中,CSS 还提供了组服务,即关于在任意给定时间内哪些节点和实例构成集群的动态信息,以及诸如节点的名称和节点静态信息(这些信息在节点被加入或者移除时被修改)。CSS 维护集群内的基本锁功能(尽管大多数锁有 RDBMS 内部的集成分布式锁管理来维护)。除了执行其他作业外,CSS 还负责在集群内节点间维持一个心跳的程序,并监控投票磁盘的 split-brain 故障。在安装 clusterware 的最后阶段,会要求在每个节点执行 root.sh 脚本,这个脚本会在/etc/inittab 文件的最后把这 3 个进程加入启动项,这样以后每次系统启动时,clusterware 也会自动启动,其中 EVMD 和 CRSD 两个进程如果出现异常,则系统会自动重启这两个进程,如果是 CSSD 进程异常,系统会立即重启。
注意:
1、Voting Disk 和 OCR 必须保存在存储设备上供各个节点访问。
2、Voting Disk、OCR 和网络是安装的过程中或者安装前必须要指定或者配置的。安装完成后可以通过一些工具进行配置和修改。
RAC 软件结构可以分为四部分。
(一) Operation System-Dependent(OSD)
RAC 通过操作系统的相关软件来访问操作系统和一些与 Cluster 相关的服务进程。OSD 软件可能由 Oracle 提供(windows 平台)或由硬件厂商提供(unix 平台)。OSD 包括三个自部分:
(二) Real Application Cluster Shard Disk Component
RAC 中这部分组件和单实例 Oracle 数据库中的组件没有什么区别。包括一个或者多个控制文件、一些列联机重做日志文件、可选的归档日志文件、数据文件等。在 RAC 中使用服务器参数文件会简化参数文件的管理,可以将全局参数和实例特定的参数存储在同一个文件中。
(三) Real Application Cluster-Specific Daemon and Instance Processes包括以下部分:
(四) The Global Cache and Global Enqueue Service
全局缓存服务(GCS)和全局队列服务(GES)是 RAC 的集成组件,用于协调对共享数据库和数据库内的共享资源的同时访问。
GCS 和 GES 包括以下特性:
健忘问题是由于每个节点都有配置信息的拷贝,修改节点的配置信息不同步引起的。Oracle 采用的解决方法就是把这个配置文件放在共享的存储上,这个文件就是 OCR Disk。OCR 中保存整个集群的配置信息,配置信息以”Key-Value” 的形式保存其中。在 Oracle 10g 以前,这个文件叫作 Server Manageability Repository(SRVM). 在 Oracle 10g,这部分内容被重新设计,并重名为 OCR.在 Oracle Clusterware 安装的过程中,安装程序会提示用户指定 OCR 位置。并且用户指定的这个位置会被记录在/etc/oracle/ocr.Loc(LinuxSystem) 或者/var/opt/oracle/ocr.Loc(SolarisSystem)文件中。而在 Oracle 9i RAC 中,对等的是 srvConfig.Loc 文件。Oracle Clusterware 在启动时会根据这里面的内容从指定位置读入 OCR 内容。
(一) OCR key
整个 OCR 的信息是树形结构,有 3 个大分支。分别是 SYSTEM,DATABASE 和 CRS。每个分支下面又有许多小分支。这些记录的信息只能由 root 用户修改。
(二) OCR process
Oracle Clusterware 在 OCR 中存放集群配置信息,故 OCR 的内容非常的重要,所有对 OCR 的操作必须确保OCR 内容完整性,所以在 ORACLE Clusterware 运行过程中,并不是所有结点都能操作 OCR Disk.在每个节点的内存中都有一份 OCR 内容的拷贝,这份拷贝叫作 OCR Cache。每个结点都有一个 OCR Process来读写 OCR Cache,但只有一个节点的 OCR process 能读写 OCR Disk 中的内容,这个节点叫作 OCR Master 结点。这个节点的 OCR process 负责更新本地和其他结点的 OCR Cache 内容。所有需要OCR 内容的其他进程,比如OCSSD,EVM等都叫作Client Process,这些进程不会直接访问OCR Cache,而是像 OCR Process发送请求,借助 OCR Process获得内容,如果想要修改 OCR 内容,也要由该节点的 OCR Process像 Master node 的 OCR process 提交申请,由 Master OCR Process 完成物理读写,并同步所有节点 OCR Cache 中的内容。
Voting Disk 这个文件主要用于记录节点成员状态,在出现脑裂时,决定那个 Partion 获得控制权,其他的Partion 必须从集群中剔除。在安装 Clusterware 时也会提示指定这个位置。安装完成后可以通过如下命令来查看Voting Disk 位置。$Crsctl query css votedisk
一、专用网络
每个集群节点通过专用高速网络连接到所有其他节点,这种专用高速网络也称为集群互联或高速互联 (HSI)。Oracle 的 Cache Fusion 技术使用这种网络将每个主机的物理内存 (RAM) 有效地组合成一个高速缓存。 OracleCache Fusion 通过在专用网络上传输某个 Oracle 实例高速缓存中存储的数据允许其他任何实例访问这些数据。它还通过在集群节点中传输锁定和其他同步信息保持数据完整性和高速缓存一致性。专用网络通常是用千兆以太网构建的,但是对于高容量的环境,很多厂商提供了专门为 Oracle RAC 设计的低延迟、高带宽的专有解决方案。 Linux 还提供一种将多个物理 NIC 绑定为一个虚拟 NIC 的方法(此处不涉及)来增加带宽和提高可用性。
二、公共网络
为维持高可用性,为每个集群节点分配了一个虚拟 IP 地址 (VIP)。 如果主机发生故障,则可以将故障节点的 IP 地址重新分配给一个可用节点,从而允许应用程序通过相同的 IP 地址继续访问数据库。
三、Virtual lP(VIP)
即虚拟 IP,Oracle 推荐客户端连接时通过指定的虚拟 IP 连接,这也是 Oracle10g 新推出的一个特性。其本质目的是为了实现应用的无停顿(虽然目前还是有点小问题,但离目标已经非常接近)。用户连接虚 IP,这个 IP并非绑定于网卡,而是由 oracle 进程管理,一旦某个用户连接的虚 IP 所在实例宕机,oracle 会自动将该 IP 映射到状态正常的实例,这样就不会影响到用户对数据库的访问,也无须用户修改应用。Oracle 的 TAF 建立在 VIP 技术之上。IP 和 VIP 区别在与: IP 是利用 TCP 层超时, VIP 利用的是应用层的立即响应。VIP 它是浮动的 IP. 当一个节点出现问题时会自动的转到另一个节点上。
透明应用故障转移(Transport Application Failover,TAF)是 oracle 数据提供的一项,普遍应用于 RAC 环境中,当然也可以用于 Data Guard 和传统的 HA 实现的主从热备的环境中。TAF 中的 Transparent 和 Failover,点出了这个高可用特性的两大特点:
但是,TAF 是完美的吗?是不是使用了 TAF,应用就能真的无缝地进行切换呢?对应用和数据库有没有其他什么要求?要回答这些问题,我们需要全面地了解、掌握 TAF。我始终认为,要用好一个东西,首先得掌握这个东西背后的工作原理与机制。首先来看看 Failover。Failover 有两种,一种是连接时 Failover,另一种则是运行时 Failover。前者的作用在于,应用(客户端)在连接数据库时,如果由于网络、实例故障等原因,连接不上时,能够连接数据库中的其他实例。后者的作用在于,对于一个已经在工作的会话(也就是连接已经建立),如果这个会话的实例异常中止等,应用(客户端)能够连接到数据库的其他实例(或备用库)。
负载均衡(Load-Banlance)是指连接的负载均衡。RAC 的负载均衡主要指的是新会话连接到 RAC 数据库时,根据服务器节点的 CPU 负载判定这个新的连接要连接到哪个节点进行工作。Oracle RAC 可以提供动态的数据服务,负载均衡分为两种,一种是基于客户端连接的,一种是基于服务器端的。
Oracle 的 TAF 建立在 VIP 的技术之上。IP 和 VIP 区别在于:IP 是利用 TCP 层超时,VIP 利用的是应用层的立即响应。VIP 是是浮动的 IP,当一个节点出现问题的时候,会自动的转到另一个节点上。假设有一个两节点的 RAC,正常运行时每个节点上都有一个 VIP,即 VIP1 和 VIP2。当节点 2 发生故障,比如异常关系。RAC 会做如下操作:
(一) CRS 在检测到 rac2 节点异常后,会触发 Clusterware 重构,最后把 rac2 节点剔除集群,由节点 1 组成新的集群。
(二) RAC 的 Failover 机制会把节点 2 的 VIP 转移到节点 1 上,这时节点 1 的 PUBLIC 网卡上就有 3 个 IP 地址:VIP1,VIP2, PUBLIC IP1.
(三) 用户对 VIP2 的连接请求会被 IP 层路由转到节点 1
(四) 因为在节点 1 上有 VIP2 的地址,所有数据包会顺利通过路由层,网络层,传输层。
(五) 但是,节点 1 上只监听 VIP1 和 public IP1 的两个 IP 地址。并没有监听 VIP2,故应用层没有对应的程序接收这个数据包,这个错误立即被捕获。
(六) 客户端能够立即接收到这个错误,然后客户端会重新发起向 VIP1 的连接请求。VIP 特点:
Redo Thread
RAC 环境下有多个实例,每个实例都需要有自己的一套 Redo Log 文件来记录日志。这套 Redo Log 就叫做 RedoThread,其实单实例下也是 Redo Thread,只是这个词很少被提及,每个实例一套 Redo Thread 的设计就是为了避免资源竞争造成的性能瓶颈。Redo Thread 有两种,一种是 Private,创建语法 alter database add logfile ......thread n;另一种是 public,创建语法:alter database add logfile......;RAC 中每个实例都要设置 thread 参数,该参数默认值为 0。如果设置了这个参数,则使用缺省值 0,启动实例后选择使用 Public Redo Thread,并且实例会用独占的方式使用该 Redo Thread。RAC 中每个实例都需要一个 Redo Thread,每个 Redo Log Thread 至少需要两个 Redo Log Group,每个 Log Group成员大小应该相等,没组最好有 2 个以上成员,这些成员应放在不同的磁盘上,防止单点故障。
注意:在 RAC 环境下,Redo Log Group 是在整个数据库级别进行编号,如果实例 1 有 1,2 两个日志组,那么实例 2 的日志组编号就应该从 3 开始,不能使用 1,2 编号了。在 RAC 环境上,所有实例的联机日志必须放在共享存储上,因为如果某个节点异常关闭,剩下的节点要进行 crash recovery,执行 crash recovery 的这个节点必须能够访问到故障节点的连接日志,只有把联机日志放在共享存储上才能满足这个要求。
Archive log
RAC 中的每个实例都会产生自己的归档日志,归档日志只有在执行 Media Recovery 时才会用到,所以归档日志不必放在共享存储上,每个实例可以在本地存放归档日志。但是如果在单个实例上进行备份归档日志或者进行 Media Recovery 操作,又要求在这个节点必须能够访问到所有实例的归档日志,在 RAC 幻境下,配置归档日志可以有多种选择。
使用 NFS 的方式将日志直接归档到存储,例如两个节点,每个节点都有 2 个目录,Arch2,Arch3 分别对应实例 1 和实例 2 产生的归档日志。每个实例都配置一个归档位置,归档到本地,然后通过 NFS 把对方的目录挂到本地。
实例间归档(Cross Instance Archive)是上一种方式的变种,也是比较常见的一种配置方法。两个节点都创建 2 个目录 Arch2 和 Arch3 分别对应实例 1 和实例 2 产生的归档日志。每个实例都配置两个归档位置。位置 1对应本地归档目录,位置 2 对应另一个实例
使用 ASM 将日志归档到共享存储,只是通过 Oracle 提供的 ASM,把上面的复杂性隐藏了,但是原理都一样。
Trace 日志
Oracle Clusterware 的辅助诊断,只能从 log 和 trace 进行。 而且它的日志体系比较复杂。 alert.log:$ORA_CRS_HOME/log/hostname/alert.Log, 这是首选的查看文件。
Clusterware 后台进程日志
Nodeapp 日志位置
ORACRSHOME/log/hostname/racg/这里面放的是nodeapp的日志,包括ONS和VIP,比如:ora.Rac1.ons.Log工具执行日志:ORACRSHOME/log/hostname/racg/这里面放的是nodeapp的日志,包括ONS和VIP,比如:ora.Rac1.ons.Log工具执行日志:ORA_CRS_HOME/log/hostname/client/
Clusterware 提供了许多命令行工具 比如 ocrcheck, ocrconfig,ocrdump,oifcfg 和 clscfg, 这些工具产生的日志就放在这个目录下,还有ORACLEHOME/log/hostname/client/和ORACLEHOME/log/hostname/client/和ORACLE_HOME/log/hostname/racg 也有相关的日志。
前面已经介绍了 RAC 的后台进程,为了更深入的了解这些后台进程的工作原理,先了解一下 RAC 中多节点对共享数据文件访问的管理是如何进行的。要了解 RAC 工作原理的中心,需要知道 Cache Fusion 这个重要的概念,要发挥 Cache Fusion 的作用,要有一个前提条件,那就是互联网络的速度要比访问磁盘的速度要快。否则,没有引入 Cache Fusion 的意义。而事实上,现在 100MB 的互联网都很常见。
Cache Fusion 就是通过互联网络(高速的 Private interconnect)在集群内各节点的 SGA 之间进行块传递,这是RAC最核心的工作机制,他把所有实例的SGA虚拟成一个大的SGA区,每当不同的实例请求相同的数据块时,这个数据块就通过 Private interconnect 在实例间进行传递。以避免首先将块推送到磁盘,然后再重新读入其他实例的缓存中这样一种低效的实现方式(OPS 的实现)。当一个块被读入 RAC 环境中某个实例的缓存时,该块会被赋予一个锁资源(与行级锁不同),以确保其他实例知道该块正在被使用。之后,如果另一个实例请求该块的一个副本,而该块已经处于前一个实例的缓存内,那么该块会通过互联网络直接被传递到另一个实例的 SGA。如果内存中的块已经被改变,但改变尚未提交,那么将会传递一个 CR 副本。这就意味着只要可能,数据块无需写回磁盘即可在各实例的缓存之间移动,从而避免了同步多实例的缓存所花费的额外 I/O。很明显,不同的实例缓存的数据可以是不同的,也就是在一个实例要访问特定块之前,而它又从未访问过这个块,那么它要么从其他实例 cache fusion 过来,或者从磁盘中读入。GCS(Global Cache Service,全局内存服务)和 GES(Global EnquenceService,全局队列服务)进程管理使用集群节点之间的数据块同步互联。
这里还是有一些问题需要思考的:
锁是在各实例的 SGA 中保留的资源,通常被用于控制对数据库块的访问。每个实例通常会保留或控制一定数量与块范围相关的锁。当一个实例请求一个块时,该块必须获得一个锁,并且锁必须来自当前控制这些锁的实例。也就是锁被分布在不同的实例上。而要获得特定的锁要从不同的实例上去获得。但是从这个过程来看这些锁不是固定在某个实例上的,而是根据锁的请求频率会被调整到使用最频繁的实例上,从而提高效率。要实现这些资源的分配和重分配、控制,这是很耗用资源的。这也决定了 RAC 的应用设计要求比较高。假设某个实例崩溃或者某个实例加入,那么这里要有一个比较长的再分配资源和处理过程。在都正常运行的情况下会重新分配,以更加有效的使用资源;在实例推出或加入时也会重新分配。在 alert 文件中可以看到这些信息。而 Cache Fusion 及其他资源的分配控制,要求有一个快速的互联网络,所以要关注与互联网络上消息相关的度量,以测试互联网络的通信量和相应时间。对于前面的一些问题,可以结合另外的概念来学习,它们是全局缓存服务和全局队列服务。
全局缓存服务(GCS):要和 Cache Fusion 结合在一起来理解。全局缓存要涉及到数据块。全局缓存服务负责维护该全局缓冲存储区内的缓存一致性,确保一个实例在任何时刻想修改一个数据块时,都可获得一个全局锁资源,从而避免另一个实例同时修改该块的可能性。进行修改的实例将拥有块的当前版本(包括已提交的和未提交的事物)以及块的前象(post image)。如果另一个实例也请求该块,那么全局缓存服务要负责跟踪拥有该块的实例、拥有块的版本是什么,以及块处于何种模式。LMS 进程是全局缓存服务的关键组成部分。
猜想:Oracle 目前的 cache fusion 是在其他实例访问时会将块传输过去再构建一个块在那个实例的 SGA 中,这个主要的原因可能是 interconnect 之间的访问还是从本地内存中访问更快,从而让 Oracle 再次访问时可以从本地内存快速获取。但是这也有麻烦的地方,因为在多个节点中会有数据块的多个 copy,这样在管理上的消耗是很可观的,Oracle 是否会有更好的解决方案出现在后续版本中?如果 interconnect 速度允许的话...)
全局队列服务(GES):主要负责维护字典缓存和库缓存内的一致性。字典缓存是实例的 SGA 内所存储的对数据字典信息的缓存,用于高速访问。由于该字典信息存储在内存中,因而在某个节点上对字典进行的修改(如DDL)必须立即被传播至所有节点上的字典缓存。GES 负责处理上述情况,并消除实例间出现的差异。处于同样的原因,为了分析影响这些对象的 SQL 语句,数据库内对象上的库缓存锁会被去掉。这些锁必须在实例间进行维护,而全局队列服务必须确保请求访问相同对象的多个实例间不会出现死锁。LMON、LCK 和 LMD 进程联合工作来实现全局队列服务的功能。GES 是除了数据块本身的维护和管理(由 GCS 完成)之外,在 RAC 环境中调节节点间其他资源的重要服务。
SQL> select * from gv$sysstat where name like 'gcs %'
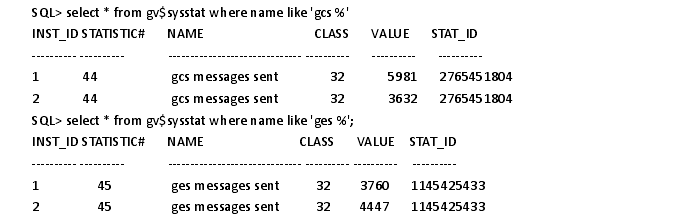
这里可以看到 gcs 和 ges 消息的发送个数。(如果没有使用 DBCA 来创建数据库,那么要 SYSDBA 权限来运行CATCLUST.SQL 脚本来创建 RAC 相关的视图和表)
Oracle failsafe、Data Guard 和 RAC 均为 ORACLE 公司提供的高可靠性(HA)解决方案。然而之三者之间却存在着很大区别。HA 是 High Availability 的首字母组合,翻译过来,可以叫做高可用,或高可用性,高可用(环境)。我觉得应该说 HA 是一个观念而不是一项或一系列具体技术,就象网格一样。作过系统方案就知道了,评价系统的性能当中就有一项高可用。也就是 OS 一级的双机热备。RAC 是 real application cluster 的简称,它是在多个主机上运行一个数据库的技术,即是一个 db 多个 instance。它的好处是 可以由多个性能较差的机器构建出一个整体性能很好的集群,并且实现了负载均衡,那么当一个节点出现故障时,其上的服务会自动转到另外的节点去执行,用户甚 至感觉不到什么。
1、 操作系统:
failsafe 系统局限于 WINDOWS 平台,必须配合 MSCS(microsoft cluster server),而 RAC 最早是在 UNIX 平台推出的,目前已扩展至 LINUX 和 WINDOWS 平台,通过 OSD(operating system dependent)与系统交互。对于高端的 RAC 应用,UNIX 依然是首选的平台。
2、 系统结构:
FAILSAFE 采用的是 SHARE NOTHING 结构,即采用若干台服务器组成集群,共同连接到一个共享磁盘系统,在同一时刻,只有一台服务器能够访问共享磁盘,能够对外提供服务。只要当此服务器失效时,才有另一台接管共享磁盘。RAC 则是采用 SHARE EVERYTHING,组成集群的每一台服务器都可以访问共享磁盘,都能对外提供服务。也就是说 FAILSAFE 只能利用一台服务器资源,RAC 可以并行利用多台服务器资源。
3、 运行机理:
组成 FAILSAFE 集群的每台 SERVER 有独立的 IP,整个集群又有一个 IP,另外还为 FAILSAFE GROUP 分配一个单独的 IP(后两个 IP 为虚拟 IP,对于客户来说,只需知道集群 IP,就可以透明访问数据库)。工作期间,只有一台服务器(preferred or owner or manager)对外提供服务,其余服务器(operator)成待命状,当前者失效时,另一服务器就会接管前者,包括FAILSAFE GROUP IP与CLUSTER IP,同时FAILSAFE会启动上面的DATABASE SERVICE,LISTENER 和其他服务。客户只要重新连接即可,不需要做任何改动。对于 RAC 组成的集群,每台服务器都分别有自已的 IP,INSTANCE 等,可以单独对外提供服务,只不过它们都是操作位于共享磁盘上的同一个数据库。当某台服务器失效后,用户只要修改网络配置,如(TNSNAMES。ORA),即可重新连接到仍在正常运行的服务器上。但和 TAF 结合使用时,甚至网络也可配置成透明的。
4、 集群容量:
前者通常为两台,后者在一些平台上能扩展至 8 台。
5、 分区:
FAILSAFE 数据库所在的磁盘必须是 NTFS 格式的,RAC 则相对灵活,通常要求是 RAW,然而若干 OS 已操作出了 CLUSTER 文件系统可以供 RAC 直接使用。综上所述,FAILSAFE 比较适合一个可靠性要求很高,应用相对较小,对高性能要求相对不高的系统,而 RAC则更适合可靠性、扩展性、性能要求都相对较高的较大型的应用。
RAC 是 OPS 的后继版本,继承了 OPS 的概念,但是 RAC 是全新的,CACHE 机制和 OPS 完全不同。RAC 解决了 OPS 中 2 个节点同时写同一个 BLOCK 引起的冲突问题。 从产品上来说 RAC 和 OPS 是完全不同的产品,但是我们可以认为是相同产品的不同版本
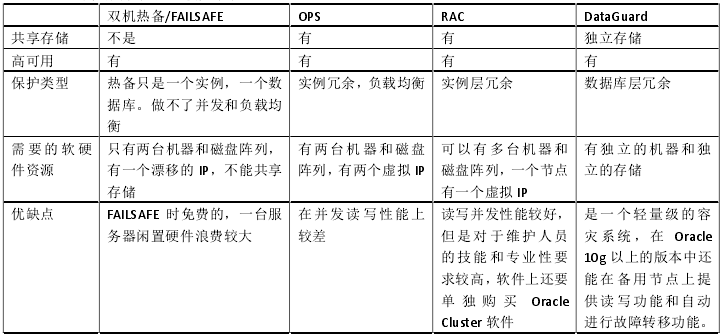
Data Guard 是 Oracle 的远程复制技术,它有物理和逻辑之分,但是总的来说,它需要在异地有一套独立的系统,这是两套硬件配置可以不同的系统,但是这两套系统的软件结构保持一致,包括软件的版本,目录存储结构,以及数据的同步(其实也不是实时同步的),这两套系统之间只要网络是通的就可以了,是一种异地容灾的解决方案。而对于 RAC,则是本地的高可用集群,每个节点用来分担不用或相同的应用,以解决运算效率低下,单节点故障这样的问题,它是几台硬件相同或不相同的服务器,加一个 SAN(共享的存储区域)来构成的。Oracle 高可用性产品比较见下表:
通常在 RAC 环境下,在公用网络的基础上,需要配置两条专用的网络用于节点间的互联,在 HACMP/ES 资源的定义中,这两条专用的网络应该被定义为"private" 。在实例启动的过程中,RAC 会自动识别和使用这两条专用的网络,并且如果存在公用"public" 的网络,RAC 会再识别一条公用网络。当 RAC 识别到多条网络时,RAC会使用 TNFF (Transparent Network Failvoer Failback) 功能,在 TNFF 下所有的节点间通信都通过第一条专用的网络进行,第二条( 或第三条等) 作为在第一条专用的网络失效后的备份。RAC 节点间通信如下图所示。
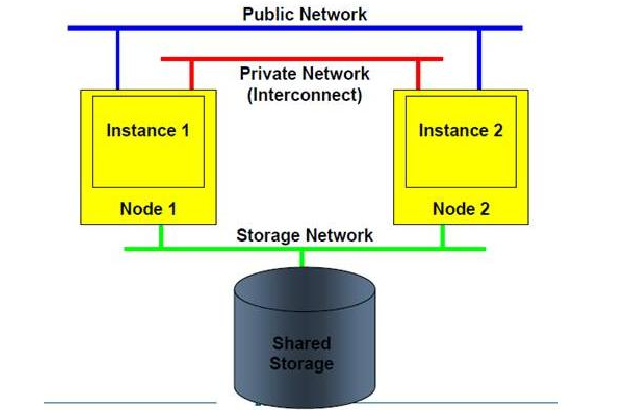
CLUSTER_INTERCONNECTS 是在 Oracle RAC 中的一个可选的初始化(init.ora) 参数。此参数可以指定使用哪一条网络用于节点间互联通信,如果指定多条网络,RAC 会在这些网络上自动进行负载均衡。然而,当CLUSTER_INTERCONNECTS 设置时,TNFF 不起作用,这将降低 RAC 的可用性,任何一条节点间互联网络的失效,都会造成 RAC 一个或多个节点的失效。ORACLE RAC 用于 INTERCONNECT 的内网卡的物理连接方式的选择:采用交换机连接或是网线直连。直连的弊端是,一旦一个节点机的内网卡出现故障,oracle 从 OS 得到两个节点的网卡状态都是不正常的,因而会导致两个实例都宕掉。在 INTERCONNECT 线路出现问题的时候,oracle 一般情况下会启动一个竞争机制来决定哪个实例宕掉,如果宕掉的实例正好是好的实例的话, 这样就会导致两个实例都宕掉。在 9i 中,oracle 在启动竞争机制之前,会先等待一段时间,等待 OS 将网络的状态发给 oracle,如果在超时之前,oracle 获得哪个实例的网卡是 down 的话,则将该实例宕掉,这样的话,则可以保留正常的那个实例继续服务,否则还是进入竞争机制。
综上所述节点间通信分为两种情况:
? 是接在交换机上面,此时一般情况下,是会保证正常的实例继续服务的,但有的时候如果 os 来不及将网卡状态送到 oracle 时,也是有可能会导致两个节点都宕掉的。
? 如果是直连的话,则会导致两个实例都宕掉。
CSS 心跳
OCSSD 这个进程是 Clusterware 最关键的进程,如果这个进程出现异常,会导致系统重启,这个进程提供CSS(Cluster Synchronization Service)服务。 CSS 服务通过多种心跳机制实时监控集群状态,提供脑裂保护等基础集群服务功能。
CSS 服务有 2 种心跳机制: 一种是通过私有网络的 Network Heartbeat,另一种是通过 Voting Disk 的 DiskHeartbeat。这 2 种心跳都有最大延时,对于 Disk Heartbeat,这个延时叫作 IOT (I/O Timeout);对于 Network Heartbeat, 这个延时叫 MC(Misscount)。这 2 个参数都以秒为单位,缺省时 IOT 大于 MC,在默认情况下,这 2 个参数是 Oracle自动判定的,并且不建议调整。可以通过如下命令来查看参数值:
$crsctl get css disktimeout
$crsctl get css misscount
Oracle RAC 节点间使用的通信协议见下表。

LOCK(锁)是用来控制并发的数据结构,如果有两个进程同时修改同一个数据, 为了防止出现混乱和意外,用锁来控制访问数据的次序。有锁的可以先访问,另外一个进程要等到第一个释放了锁,才能拥有锁,继续访问。总体来说,RAC 里面的锁分两种, 一种是本地主机的进程之间的锁,另外一种是不同主机的进程之间的锁。本地锁的机制有两类,一类叫做 lock(锁),另外一类叫做 latch 闩。
全局锁就是指 RAC lock,就是不同主机之间的锁,Oracle 采用了 DLM(Distributed Lock Management,分布式锁管理)机制。在 Oracle RAC 里面,数据是全局共享的,就是说每个进程看到的数据块都是一样的,在不同机器间,数据块可以传递。给出了 GRD目录结构。
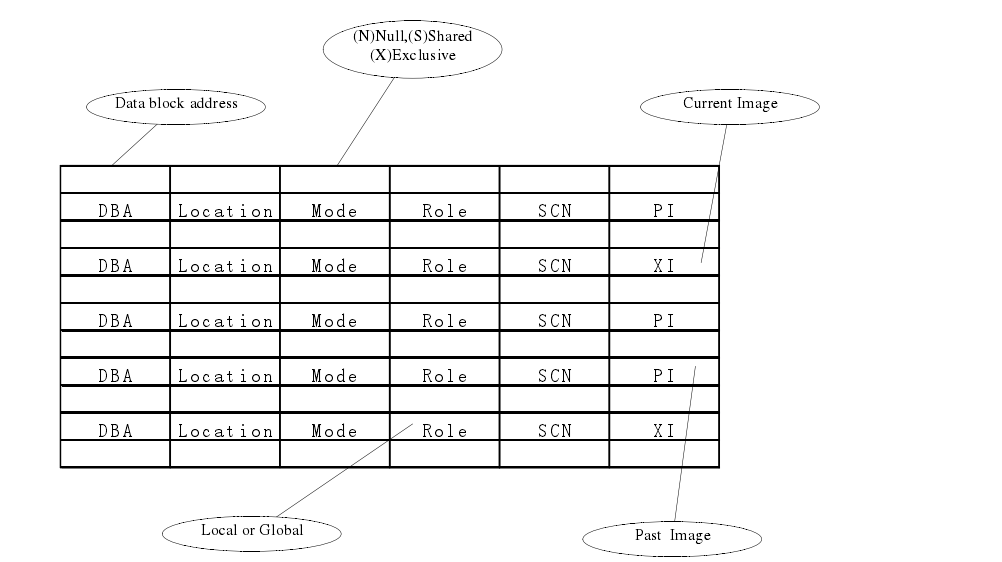
可以看出 Mode、Role、n 构成了 RAC lock 的基本结构
数据一致性和并发性描述了 Oracle 如何维护多用户数据库环境中的数据一致性问题。在单用户数据库中,用户修改数据库中的数据,不用担心其他用户同时修改相同的数据。但是,在多用户数据库中,同时执行的多个事务中的语句可以修改同一数据。同时执行的事务需要产生有意义的和一致性的结果。因而,在多用户数据库中,数据并发性和数据一致性的控制非常重要:数据并发性:每个用户可以看到数据的一致性结果。ANSI/IOS SQL 标准(SQL 92)定义了 4 个事务隔离级别,对事务处理性能的影响也个不相同。这些隔离级别是考虑了事务并发执行必须避免的 3 个现象提出的。3 个应该避免的现象为: ? ?
SQL92 根据这些对象定义了 4 个隔离级别,事务运行在特定的隔离级别允许特别的一些表现。如下表表示隔离级别阻止的读现象。

(一) OCR KEY 是树形结构。
(二) OCR PROCESS 每个节点都有 OCR CACHE 的复制,由 ORC MASTER 节点负责更新到 OCR DISK
自动启动的脚本/etc/inittab 里定义:
OCSSD(Clustery Synchronization Service)提供心跳机制监控集群状态
DISK HEARTBEAT
NETWORK HEARBEAT
CRSD(Clustery Ready Service)提供高可用、干预、关闭、重启、转移服务。
资源包括 nodeapps、database-related:前者每个节点只需要一个即可正常工作,后一个与数据库相关,不受节点限制,可以为多个。
EVMD: 这个进程负责发布 CRS 产生的各种事件,还是 CRS 和 CSS 两个服务之间通信的桥梁
RACGIMON: 这个进程负责检查数据库健康状态,包括数据库服务的启动、停止和故障转移。属于持久连接,定期检查 SGA。
OPROCD(Process Monitor Daemon)检测 CPU hang(非 Linux 平台使用)
DLM 分布式锁管理。
(一) NM(NODE MANAGEMENT)group
(二) 重构集群触发:有 node 加入或者离开集群,由 NM 触发 Network Heartbeat 异常:因为 LMON 或者 GCS、GES 通信异常 ,由 IMR(Instance Membership Reconfiguration)controlfile heartbeat 触发。
(一) 多节点负载均衡
(二) 提供高可用性,故障容错及无缝切换功能,将硬件和软件的异常造成的影响最小化。
(三) 通过并行执行技术提供事务响应的时间 - 通常用于数据分析系统。
(四) 通过横向扩展提高每秒交易数和连接数 - 通常用于 OLTP。
(五) 节约硬件成本,可以使用多个廉价的 PC 服务器代替小型机大型机,节约相应的维护成本。
(六) 可扩展性好,可以方便添加删除节点,扩展硬件资源。
(一) 管理更复杂,要求更高
(二) 系统规划设计较差时性能可能会不如单节点
(三) 可能会增加软件成本(按照 CPU 收费)
在需要将一个 LUN (逻辑单元号)映射给多个节点、为集群提供一个共享的存储卷时,同一个存储 LUN 在各个主机端的 LUNID 必须是相同的。比如:
(一) 在为多个 ESX 节点创建一个 VMFS 卷的时候
(二) 在双机 HA 集群创建共享存储的时候
集群模式下,各个节点要协同工作,因此,各主机的时间必须一致。因此,各主机的时间必须一致。各个节点之间的时间差不能超时,一般如果超过 30s,节点很可能会重启,所以要同步各节点的时间。例如,需要配置一个 ntp 时钟服务器,来给 RAC 的各个节点进行时间同步。或者让节点之间进行时间同步,保证各个节点的时间同步,但是无法保证 RAC 数据库的时间的准确性。
集群必须依赖内部的互联网络实现数据通讯或者心跳功能。因此,采用普通的以太网还是其他的高速网络(比如 IB),就很有讲究,当然了,还有拿串口线实现心跳信息传递。此外,采用什么样的网络参数对集群整体的性能和健壮性都大有关系。
案例:
XX 市,4 节点 Oracle 10g RAC
操作系统采用的是 RHEL 4,按照默认的安装文档,设置网络参数为如下值:
net.core.rmem_default = 262144
net.core.rmem_max = 262144
执行一个查询语句,需要 11 分钟,修改参数:
net.core.rmem_default = 1048576
net.core.rmem_max = 1048576
再次执行仅需 16.2 秒。
案例:
XX 市,HPC 集群,运行 LS-DYNA(通用显示非线性有限元分析程序)。
集群存储系统的环境说明:存储系统的 3 个 I/O 节点通过 FC SAN 交换机连接到一个共享的存储。
故障现象
集群到货后发现盘阵与机器直连能通,两个设备接 200E 交换机不通。后经测试交换机 IOS 版本问题导致不能正常认出盘阵的光纤端口,与交换机的供货商联系更新了两次 IOS,盘阵的端口能正常识别,但盘阵与机器相连还是无法找到盘阵。经过今天的测试发现三台 I/O 节点采用的 HBA 卡 firmware 版本不一致。最早接光纤交换机及与盘阵直连的的 I/O1 的 firmware 为 v4.03.02,今天又拿出来的两台 I/O 节点 firmware 为 v4.06.03。用后两台测试后盘阵、机器、交换机之间可以正常通信,到今天晚上为止没有发现异常情况。从目前的情况判断是QLE2460 firmware 为 v4.03.01 的 HBA 卡与 200E IOS V5.3.1 有冲突者不兼容导致的故障。至于新的 HBA 卡 firmware为 v4.06.03 与 200E IOS V5.3.1 连接的稳定性如何还要做进一步测试。
诊断处理结果
I/O 1 节点 HBA 卡的 fimware 升级到 v4.06.03 后连接 200E 找不到盘阵的故障已经得到解决。其实是一个 FCHBA 卡的固件版本不一致引起的问题。
Oracle Cluster Registry(OCR):记录 OCR 记录节点成员的配置信息,如 database、ASM、instance、 listener、VIP 等 CRS 资源的配置信息,可存储于裸设备或者群集文件系统上。Voting disk : 即仲裁盘,保存节点的成员信息,当配置多个投票盘的时候个数必须为奇数,每个节点必须同时能够连接半数以上的投票盘才能够存活。初次之外包含哪些节点成员、节点的添加和删除信息。
在 Oracle RAC 中,软件不建议安装在共享文件系统上,包括 CRS_HOME 和 ORACLE_HOME,尤其是 CRS 软件,推荐安装在本地文件系统中,这样在进行软件升级,以及安装 patch 和 patchset 的时候可以使用滚动升级(rolling upgrade)的方式,减少计划当机时间。另外如果软件安装在共享文件系统也会增加单一故障点。如果使用 ASM 存储,需要为 asm 单独安装 ORACLE 软件,独立的 ORACLE_HOME,易于管理和维护,比如当遇到 asm 的 bug 需要安装补丁时,就不会影响 RDBMS 文件和软件。
在一个共享存储的集群中,当集群中 heartbeat 丢失时,如果各节点还是同时对共享存储去进行操作,那么在这种情况下所引发的情况是灾难的。ORACLE RAC 采用投票算法来解决这个问题,思想是这样的:每个节点都有一票,考虑有 A,B,C 三个节点的集群情形,当 A 节点由于各种原因不能与 B,C 节点通信时,那么这集群分成了两个 DOMAIN,A 节点成为一个 DOMAIN,拥有一票;B,C 节点成为一个 DOMAIN 拥有两票,那么这种情况B,C 节点拥有对集群的控制权,从而把 A 节点踢出集群,对要是通 IO FENCING 来实现。如果是两节点集群,则引入了仲裁磁盘,当两个节点不能通信时,请求最先到达仲裁磁盘的节点拥用对集群的控制权。网络问题(interconnect 断了),时间不一致;misscount 超时 等等,才发生 brain split,而此时为保护整个集群不受有问题的节点影响,而发生 brain split。oracle 采用的是 server fencing,就是重启有问题的节点,试图修复问题。当然有很多问题是不能自动修复的。比如时间不一致,而又没有 ntp;网线坏了。。。这些都需要人工介入修复问题。而此时的表现就是有问题的节点反复重启。
从 Oracle10g 起,Oracle 提供了自己的集群软件,叫做 Oracle Clusterware,简称 CRS,这个软件是安装 oraclerac 的前提,而上述第三方集群则成了安装的可选项 。同时提供了另外一个新特性叫做 ASM,可以用于 RAC 下的共享磁盘设备的管理,还实现了数据文件的条带化和镜像,以提高性能和安全性 (S.A.M.E: stripe and mirroreverything ) ,不再依赖第三方存储软件来搭建 RAC 系统。尤其是 Oracle11gR2 版本不再支持裸设备,Oracle 将全力推广 ASM,彻底放弃第三方集群组件支持。
Oracle Clusterware 使用两种心跳设备来验证成员的状态,保证集群的完整性。
两种心跳机制都有一个对应的超时时间,分别叫做 misscount 和 disktimeout:
reboottime ,发生裂脑并且一个节点被踢出后,这个节点将在reboottime 的时间内重启;默认是 3 秒。用下面的命令查看上述参数的实际值:
在下面两种情况发生时,css 会踢出节点来保证数据的完整,:
(一) Private Network IO time > misscount,会发生 split brain 即裂脑现象,产生多个“子集群”(subcluster) ,这些子集群进行投票来选择哪个存活,踢出节点的原则按照下面的原则:节点数目不一致的,节点数多的 subcluster 存活;节点数相同的,node ID 小的节点存活。
(二) VoteDisk I/O Time > disktimeout ,踢出节点原则如下:失去半数以上 vote disk 连接的节点将在 reboottime 的时间内重启。例如有 5 个 vote disk,当由于网络或者存储原因某个节点与其中>=3 个 vote disk 连接超时时,该节点就会重启。当一个或者两个 vote disk 损坏时则不会影响集群的运行。
对于一个已经有的系统,可以用下面几种方法来确认数据库实例的心跳配置,包括网卡名称、IP 地址、使用的网络协议。
? 最简单的方法,可以在数据库后台报警日志中得到。使用 oradebug
SQL> oradebug setmypid
Statement processed.
SQL> oradebug ipc
Information written to trace file.
SQL> oradebug tracefile_name
/oracle/admin/ORCL/udump/orcl2_ora_24208.trc
找到对应 trace 文件的这一行:socket no 7 IP 10.0.0.55 UDP 16878
? 从数据字典中得到:
SQL> select * from v$cluster_interconnects;

SQL> select * from x$ksxpia;

为了避免心跳网络成为系统的单一故障点,简单地我们可以使用操作系统绑定的网卡来作为 Oracle 的心跳网络,以 AIX 为例,我们可以使用 etherchannel 技术,假设系统中有 ent0/1/2/3 四块网卡,我们绑定 2 和 3 作为心跳:在 HPUX 和 Linux 对应的技术分别叫 APA 和 bonding
UDP 私有网络的调优当使用 UDP 作为数据库实例间 cache fusion 的通信协议时,在操作系统上需要调整相关参数,以提高 UDP传输效率,并在较大数据时避免出现超出 OS 限制的错误:
(一) UDP 数据包发送缓冲区:大小通常设置要大于(db_block_size * db_multiblock_read_count )+4k,
(二) UDP 数据包接收缓冲区:大小通常设置 10 倍发送缓冲区;
(三) UDP 缓冲区最大值:设置尽量大(通常大于 2M)并一定要大于前两个值;
各个平台对应查看和修改命令如下:
Solaris 查看 ndd /dev/udp udp_xmit_hiwat udp_recv_hiwat udp_max_buf ;
修改 ndd -set /dev/udp udp_xmit_hiwat 262144
ndd -set /dev/udp udp_recv_hiwat 262144
ndd -set /dev/udp udp_max_buf 2621440
AIX 查看 no -a |egrep “udp_|tcp_|sb_max”
修改 no -p -o udp_sendspace=262144
no -p -o udp_recvspace=1310720
no -p -o tcp_sendspace=262144
no -p -o tcp_recvspace=262144
no -p -o sb_max=2621440
Linux 查看 文件/etc/sysctl.conf
修改 sysctl -w net.core.rmem_max=2621440
sysctl -w net.core.wmem_max=2621440
sysctl -w net.core.rmem_default=262144
sysctl -w net.core.wmem_default=262144
HP-UX 不需要
HP TRU64 查看 /sbin/sysconfig -q udp
修改: 编辑文件/etc/sysconfigtab
inet: udp_recvspace = 65536
udp_sendspace = 65536
Windows 不需要
About Me
...............................................................................................................................
● 本文整理自网络
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-06-02 09:00 ~ 2017-06-30 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
...............................................................................................................................
拿起手机使用微信客户端扫描下边的左边图片来关注小麦苗的微信公众号:xiaomaimiaolhr,扫描右边的二维码加入小麦苗的QQ群,学习最实用的数据库技术。

亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/31489487/viewspace-2144927/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务







