cdn.com/b13a0815616534c858128d3235d87ea488d057af.png">
作者 | 阿里云容器技术专家 莫源
本文整理自莫源于 8 月 31 日
K8s & cloudnative meetup 深圳场的演讲内容。
关注“阿里巴巴云原生”公众号,回复关键词“资料”
,即可获得 2019 全年 meetup 活动 PPT 合集及 K8s 最全知识图谱。
导读:Serverless 和 Autoscaling 是近些年来广大开发者非常关心的内容。有人说 Serverless 是容器 2.0,终有一天容器会和 Serverless 进行一场决战,分出胜负。实际上,容器和 Serverless 是可以共存并且互补的,特别是在 Autoscaling 相关的场景下,Serverless 可以与容器完美兼容,弥补容器场景在使用简单、速度、成本的缺欠,在本文中将会为大家介绍容器在弹性场景下的原理、方案与挑战,以及 Serverless 是如何帮助容器解决这些问题的。
当我们在谈论"弹性伸缩"的时候,我们在谈论什么?"弹性伸缩"对于团队中不同的角色有不同的意义,而这正是弹性伸缩的魅力所在。
这张图是阐述弹性伸缩问题时经常引用的一张图,表示的是集群的实际资源容量和应用所需容量之间的关系。
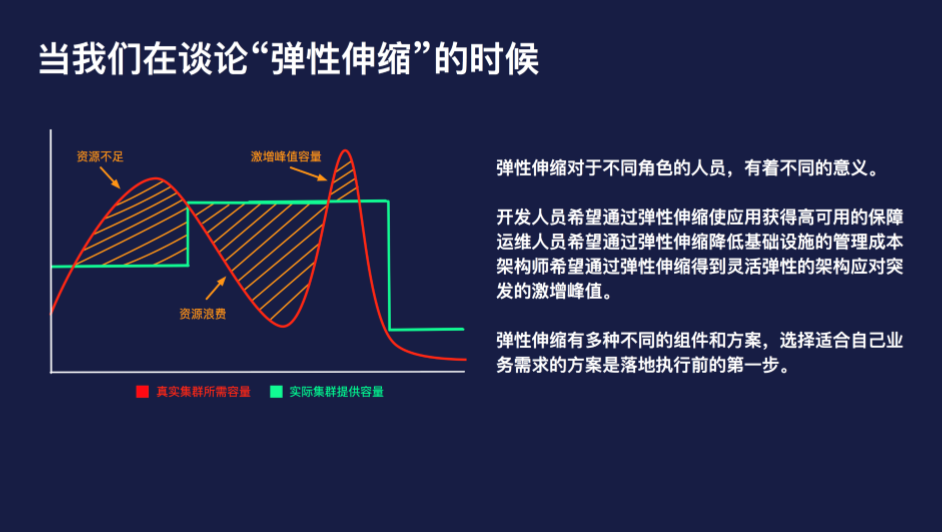
首先,我们先看左侧第一块黄色栅格的区域,这个区域表示集群的容量无法满足业务的容量所需,在实际的场景中,通常会伴随出现由于资源不足而无法调度的 Pod 等现象。
中间的栅格区域,集群的容量远高于实际资源所需的容量,此时会出现资源的浪费,实际的表现通常是节点的负载分配不均,部分节点上面无调度负载,而另外一些节点的负载相对较高。
右侧栅格区域表示的是激增的峰值容量,我们可以看到,到达峰值前的曲率是非常陡峭的,这种场景通常是由于流量激增、大批量任务等非常规容量规划内的场景,激增的峰值流量给运维同学的反应时间非常短,一旦处理不当就有可能引发事故。
弹性伸缩对于不同角色的人员,有着不同的意义:
弹性伸缩有多种不同的组件和方案,选择适合自己业务需求的方案是落地执行前的第一步。
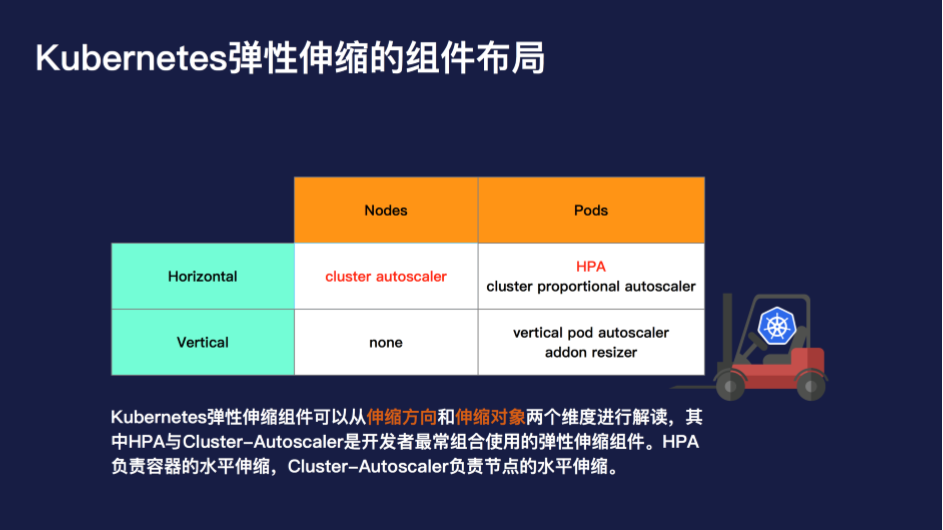
Kubernetes 弹性伸缩的组件可以从两个维度进行解读:一个是伸缩方向,一个是伸缩对象。
从伸缩方向上,分为横向与纵向。从伸缩对象上,分为节点与 Pod。那么将这个象限进行展开,就变成如下 3 类组件:
其中 HPA 与 Cluster-Autoscaler 是开发者最常组合使用的弹性伸缩组件。HPA 负责容器的水平伸缩,Cluster-Autoscaler 负责节点的水平伸缩。很多的开发者会产生这样的疑问:为什么弹性伸缩一个功能需要细化成这么多组件分开处理,难道不可以直接设置一个阈值,就实现集群的自动水位管理吗?
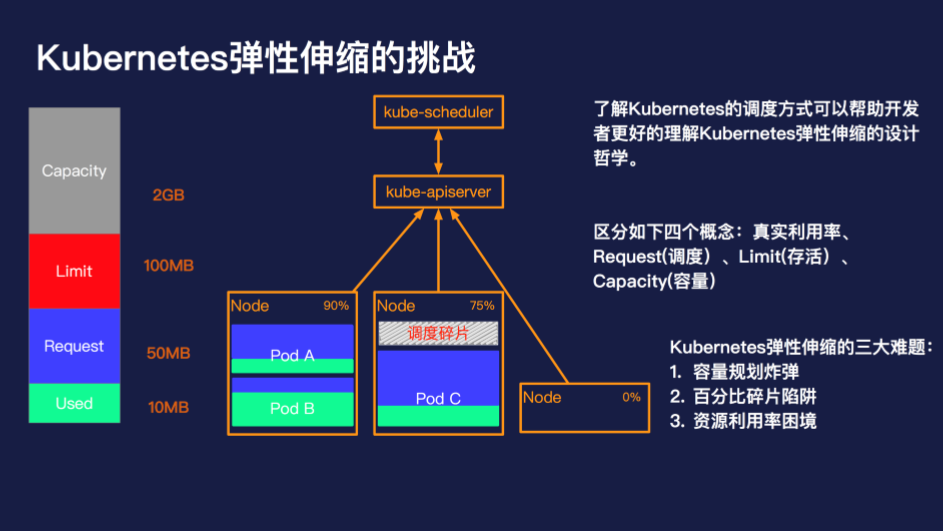
了解 Kubernetes 的调度方式可以帮助开发者更好的理解 Kubernetes 弹性伸缩的设计哲学。在 Kubernetes 中,调度的最小单元是一个 Pod,Pod 会根据调度策略被调度到满足条件的节点上,这些策略包括资源的匹配关系、亲和性与反亲和性等等,其中资源的匹配关系的计算是调度中的核心要素。
通常和资源相关的有如下四个概念:
在了解这四个基本概念和使用场景之后,我们再来看下 Kubernetes 弹性伸缩的三大难题:
1.容量规划
还记得在没有使用容器前,是如何做容量规划的吗?一般会按照应用来进行机器的分配,例如,应用 A 需要 2 台 4C8G 的机器,应用 B 需要 4 台 8C16G 的机器,应用 A 的机器与应用 B 的机器是独立的,相互不干扰。到了容器的场景中,大部分的开发者无需关心底层的资源了,那么这个时候容量规划哪里去了呢?
在 Kubernetes 中是通过
Request 和
Limit 的方式进行设置,
Request 表示资源的申请值,
Limit 表示资源的限制值。既然
Request 和
Limit 才是容量规划的对等概念,那么这就代表着资源的实际计算规则要根据
Request 和
Limit 才更加准确。而对于每个节点预留资源阈值而言,很有可能会造成小节点的预留无法满足调度,大节点的预留又调度不完的场景。
2.百分比碎片陷阱
在一个 Kubernetes 集群中,通常不只包含一种规格的机器。针对不同的场景、不同的需求,机器的配置、容量可能会有非常大的差异,那么集群伸缩时的百分比就具备非常大的迷惑性。
假设我们的集群中存在 4C8G 的机器与 16C32G 两种不同规格的机器,对于 10% 的资源预留而言,这两种规格是所代表的意义是完全不同的。特别是在缩容的场景下,通常为了保证缩容后的集群不处在震荡状态,我们会一个节点一个节点来缩容节点,那么如何根据百分比来判断当前节点是处在缩容状态就尤为重要。此时如果大规格机器有较低的利用率被判断缩容,那么很有可能会造成节点缩容后,容器重新调度后的争抢饥饿。如果添加判断条件,优先缩容小配置的节点,则有可能造成缩容后资源的大量冗余,最终集群中可能会只剩下所有的
巨石节点。
3.资源利用率困境
集群的资源利用率是否可以真的代表当前的集群状态呢?当一个 Pod 的资源利用率很低的时候,不代表就可以侵占他所申请的资源。在大部分的生产集群中,资源利用率都不会保持在一个非常高的水位,但从调度来讲,资源的调度水位应该保持在一个比较高的水位。这样才能既保证集群的稳定可用,又不过于浪费资源。
如果没有设置
Request 与
Limit,而集群的整体资源利用率很高,这意味着什么?这表示所有的 Pod 都在被以真实负载为单元进行调度,相互之间存在非常严重的争抢,而且简单的加入节点也丝毫无法解决问题,因为对于一个已调度的 Pod 而言,除了手动调度与驱逐,没有任何方式可以将这个 Pod 从高负载的节点中移走。那如果我们设置了
Request 与
Limit 而节点的资源利用率又非常高的时候说明了什么呢?很可惜这在大部分的场景下都是不可能的,因为不同的应用不同的负载在不同的时刻资源的利用率也会有所差异,大概率的情况是集群还没有触发设置的阈值就已经无法调度 Pod 了。
在了解了 Kubernetes 弹性伸缩的三大问题后,我们再来看下 Kubernetes 的解决办法是什么?
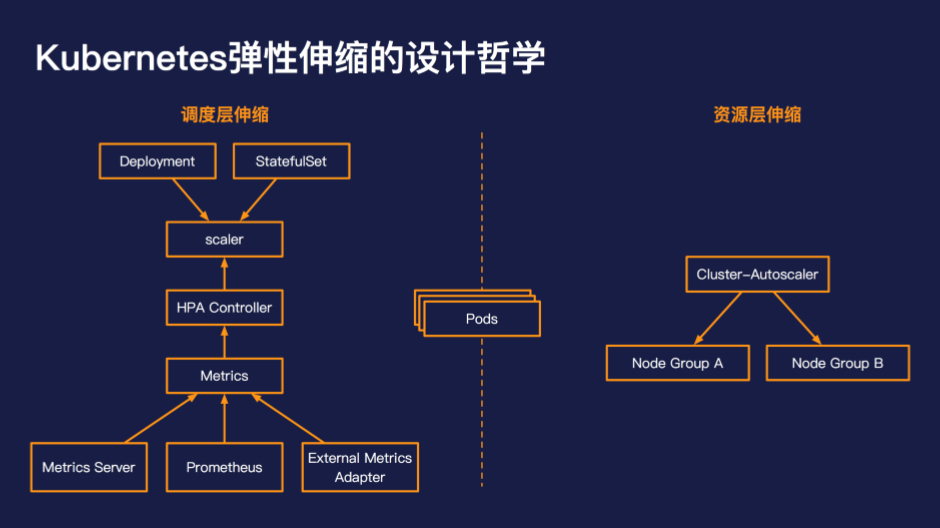
Kubernetes 的设计理念是将弹性伸缩分成调度层伸缩和资源层伸缩。调度层负责根据指标、阈值伸缩出调度单元,而资源层伸缩负责满足调度单元的资源需求。
在调度层通常是通过 HPA 的方式进行 Pod 的水平伸缩,HPA 的使用方式和我们传统意义上理解的弹性伸缩是非常接近和类似的,通过设置判断的指标、判断的阈值来进行水平伸缩。
在资源层目前主流的方案是通过 cluster-autoscaler 进行节点的水平伸缩。当出现 Pod 由于资源不足造成无法调度时,cluster-autoscaler 会尝试从配置伸缩组中,选择一个可以满足调度需求的组,并自动向组内加入实例,当实例启动后注册到 Kubernetes 后,kube-scheduler 会重新触发 Pod 的调度,将之前无法调度的 Pod 调度到新生成的节点上,从而完成全链路的扩容。
同样在缩容时,调度层会现根据资源的利用率与设置的阈值比较,实现 Pod 水平的缩容。当节点上 Pod 的调度资源降低到资源层缩容阈值的时候,此时 Cluster-Autoscaler 会进行低调度百分比的节点的排水,排水完成后会进行节点的缩容,完成整个链路的收缩。
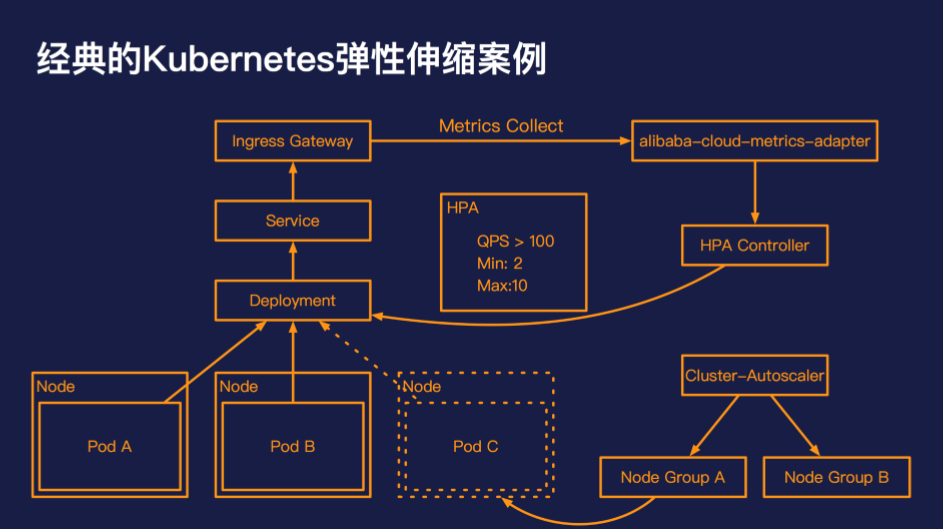
这张图是一个非常经典的弹性伸缩的案例,可以代表大多数的在线业务的场景。应用的初始架构是一个 Deployment,下面有两个 Pod,这个应用的接入层是通 过Ingress Controller 的方式进行对外暴露的,我们设置应用的伸缩策略为:单个 Pod 的 QPS 到达 100,则进行扩容,最小为 2 个 Pod,最大为 10 个 Pod。
HPA controller 会不断轮训 alibaba-cloud-metrics-adapter,来获取 Ingress Gateway 当前路由的 QPS 指标。当 Ingress Gateway 的流量到达 QPS 阈值时,HPA controller 会触发 Deployment 的 Pod 数目变化;当 Pod 的申请容量超过集群的总量后,cluster-autoscaler 会选择合适的伸缩组,弹出相应的 Node,承载之前未调度的 Pod。
这样一个经典的弹性伸缩案例就解析完毕了,那么在实际的开发过程中,会遇到哪些问题呢?
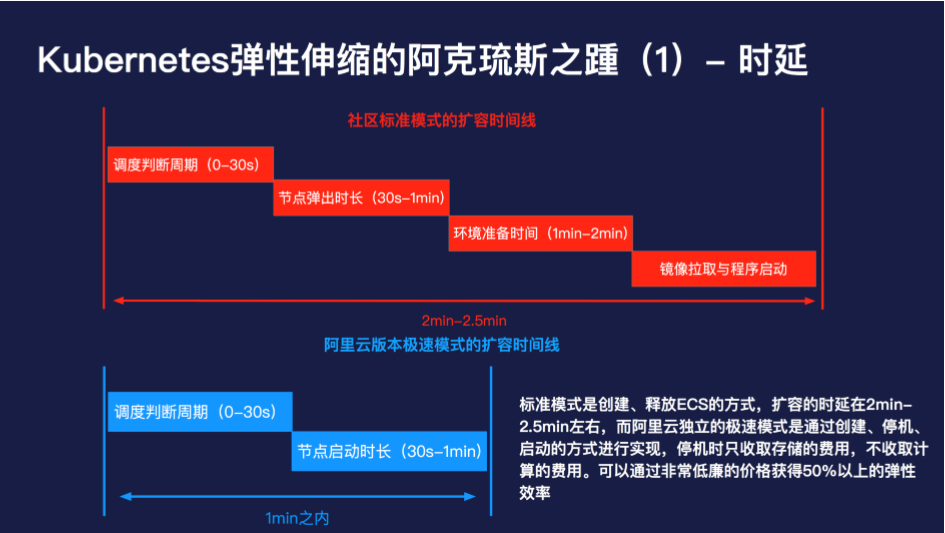
首先是扩容时延的问题,社区标准模式是通过创建、释放 ECS 的方式,扩容的时延在 2min-2.5min 左右,而阿里云独立的极速模式是通过创建、停机、启动的方式进行实现,停机时只收取存储的费用,不收取计算的费用。可以通过非常低廉的价格获得 50% 以上的弹性效率。
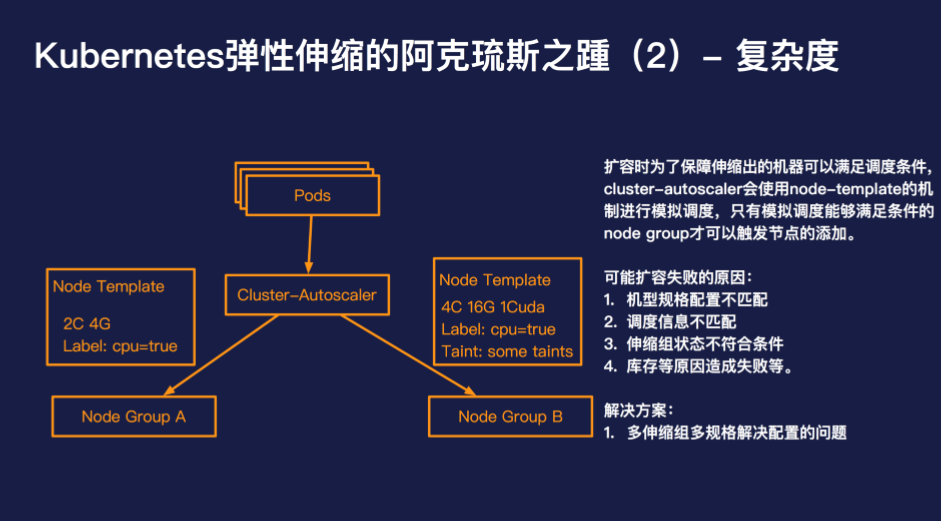
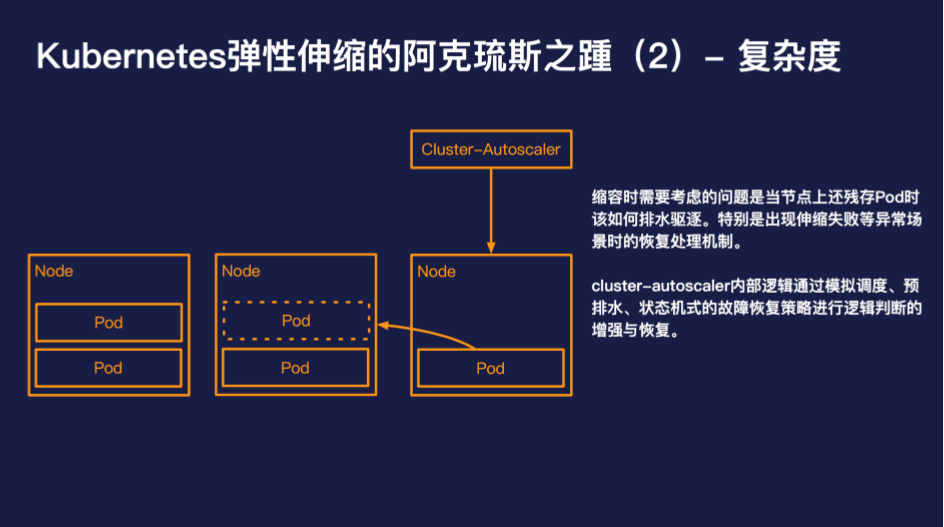
此外复杂度也是 cluster-autoscaler 绕不过的问题,想要用好 cluster-autoscaler,需要深入的了解 cluster-autoscaler 的一些内部机制,否则极有可能造成无法弹出或者无法缩容的场景。

对于大多数的开发者而言,cluster-autoscaler 的工作原理是黑盒的,而且 cluster-autoscaler 目前最好的问题排查方式依然是查看日志。一旦 cluster-autoscaler 出现运行异常后者由于开发者配置错误导致无法如预期的伸缩,那么 80% 以上的开发者是很难自己进行纠错的。
阿里云容器服务团队开发了一款 kubectl plugin,可以提供 cluster-autoscaler 更深层次的可观测性,可以查看当前 cluster-autoscaler 所在的伸缩阶段以及自动弹性伸缩纠错等能力。
虽然目前遇到的几个核心的问题,都不是压死骆驼的最后一棵稻草。但是我们一直在思考,是否有其他的方式可以让弹性伸缩使用起来更简单、更高效?
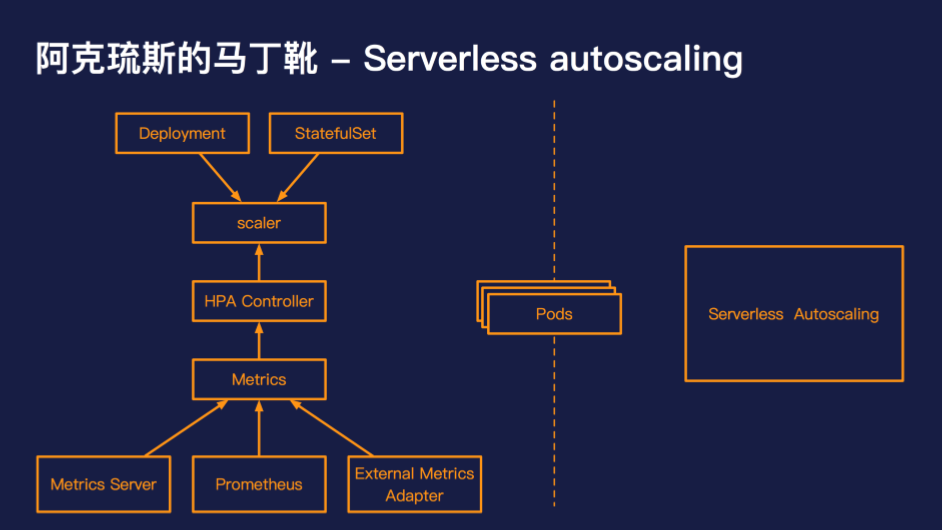
资源层伸缩的核心问题在于学习成本较高、排错困难、时效性差。当回过头来看 Serverless 的时候,我们可以发现这些问题恰好是 Serverless 的特点与优势,那么是否有办法让 Serverless 成为 Kubernetes 资源层的弹性方案呢?
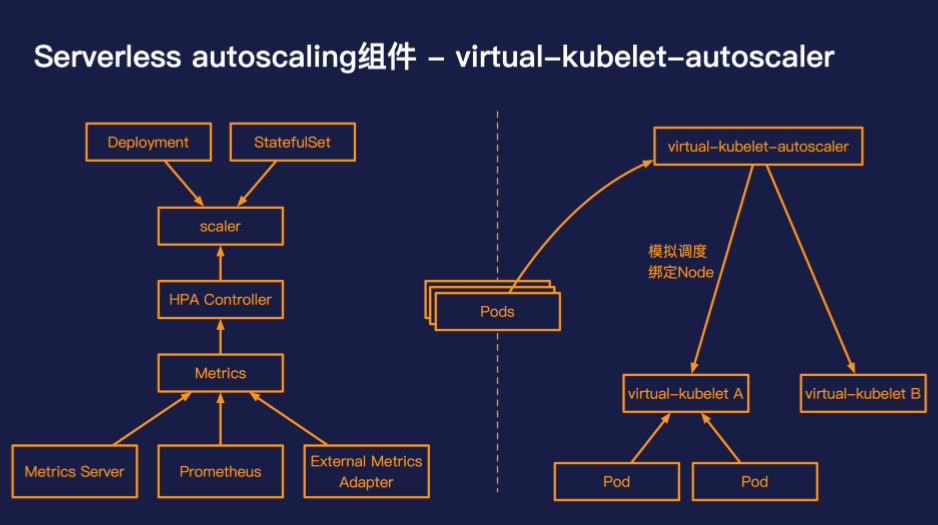
阿里云容器服务团队开发了 virtual-kubelet-autoscaler,一个在 Kubernetes 中实现 serverless autoscaling 的组件。
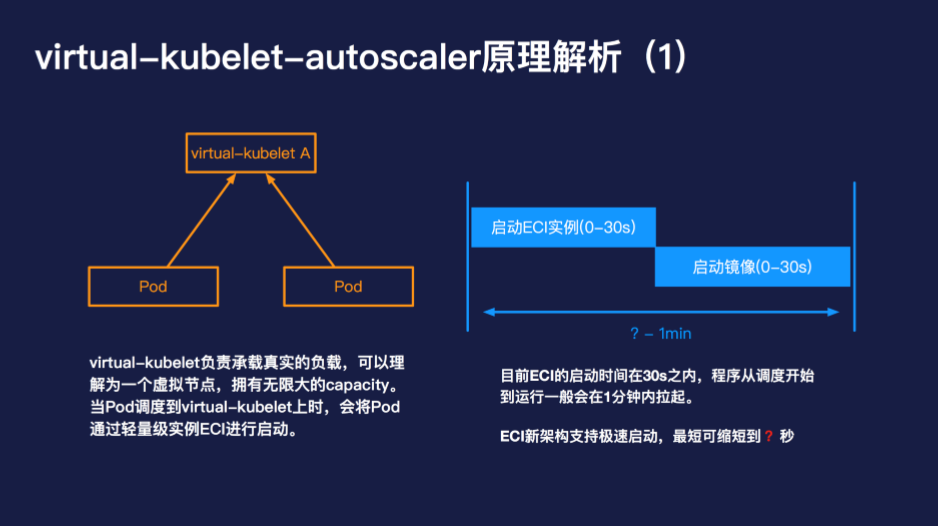
当出现了无法调度的 Pod 的时候,virtual-kubelet 负责承载真实的负载,可以理解为一个虚拟节点,拥有无限大的 capacity。当 Pod 调度到 virtual-kubelet 上时,会将 Pod 通过轻量级实例 ECI 进行启动。目前 ECI 的启动时间在 30s 之内,程序从调度开始到运行一般会在 1 分钟内拉起。
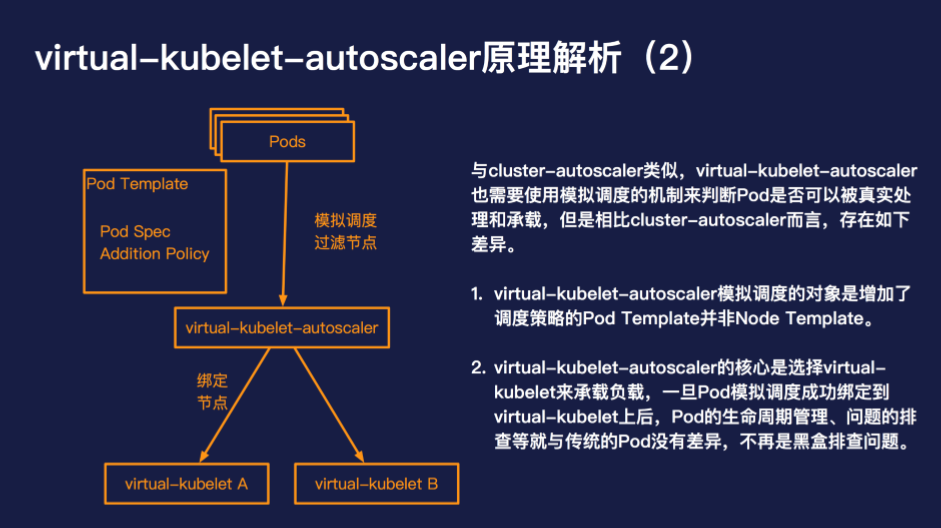
与 cluster-autoscaler 类似,virtual-kubelet-autoscaler 也需要使用模拟调度的机制来判断 Pod 是否可以被真实处理和承载,但是相比 cluster-autoscaler 而言,存在如下差异:
virtual-kubelet-autoscaler 并不是用来替代 cluster-autoscaler 的,virtual-kubelet-autoscaler 的优势在于使用简单、高弹性高并发,按量按需计费。但是与此同时也牺牲了部分的兼容性,目前对 cluster-pi、coredns 等机制支持的还并不完善,只需少许的配置 virtual-kubelet-autoscaler 是可以和 cluster-autoscaler 兼容的。virtual-kubelet-autoscaler 特别适合的场景是大数据离线任务、CI/CD 作业、突发型在线负载等。
serverless autoscaling 已经逐渐成为 Kubernetes 弹性伸缩的重要组成部分,当 serverless autoscaling 兼容性基本补齐的时候,serverless 使用简单、无需运维、成本节约的特性会与 Kubernetes 形成完美互补,实现 Kubernetes 弹性伸缩的新飞跃。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





