本篇内容介绍了“机器学习中感知器是怎么产生的”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
感知器的诞生——从样本中学习
神经网络的AI先驱们一直依靠着神经元的绘图以及它们相互连接的方式,进行着艰难的摸索。康奈尔大学的弗兰克·罗森布拉特是最早模仿人体自动图案识别视觉系统架构的人之一。
他发明了一种看似简单的网络感知器(perceptron),这种学习算法可以学习如何将图案进行分类,例如识别字母表中的不同字母。**算法是为了实现特定目标而按步骤执行的过程,**就像烘焙蛋糕的食谱一样。
如果我们了解了感知器如何学习图案识别的基本原则,那么在理解深度学习工作原理的路上已经成功了一半。感知器的目标是确定输入的图案是否属于图像中的某一类别(比如猫)。
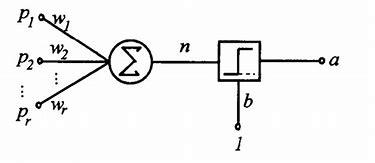
上图解释了感知器的输入如何通过一组权重,来实现输入单元到输出单元的转换。权重是对每一次输入对输出单元做出的最终决定所产生影响的度量,但是我们如何找到一组可以将输入进行正确分类的权重呢?
解决这个问题的传统方法,是根据分析或特定程序来手动设定权重。这需要耗费大量人力,而且往往依赖于直觉和工程方法。另一种方法则是使用一种从样本中学习的自动过程,和我们认识世界上的对象的方法一样。需要很多样本来训练感知器,包括不属于该类别的反面样本,特别是和目标特征相似的,例如,如果识别目标是猫,那么狗就是一个相似的反面样本。这些样本被逐个传递给感知器,如果出现分类错误,算法就会自动对权重进行校正。
感知器具体算法
这种感知器学习算法的美妙之处在于,如果已经存在这样一组权重,并且有足够数量的样本,那么它肯定能自动地找到一组合适的权重。在提供了训练集中的每个样本,并且将输出与正确答案进行比较后,感知器会进行递进式的学习。如果答案是正确的,那么权重就不会发生变化。但如果答案不正确(0被误判成了1,或1被误判成了0),权重就会被略微调整,以便下一次收到相同的输入时,它会更接近正确答。这种渐进的变化很重要,这样一来,权重就能接收来自所有训练样本的影响,而不仅仅是最后一个。

感知器是具有单一人造shen经元的神经网络,它有一个输入层,和将输入单元和输出单元相连的一组连接。感知器的目标是对提供给输入单元的图案进行分类。输出单元执行的基本操作是,把每个输入(xn)与其连接强度或权重(wn)相乘,并将乘积的总和传递给输出单元。上图中,输入的加权和(∑i=1,…,n wi xi)与阈值θ进行比较后的结果被传递给阶跃函数。如果总和超过阈值,则阶跃函数输出“1”,否则输出“0”。例如,输入可以是图像中像素的强度,或者更常见的情况是,从原始图像中提取的特征,例如图像中对象的轮廓。每次输入一个图像,感知器会判定该图像是否为某类别的成员,例如猫类。输出只能是两种状态之一,如果图像处于类别中,则为“开”,否则为“关”。“开”和“关”分别对应二进制值中的1和0。
感知器学习算法可以表达为:
感知器如何区分两个对象类别的几何解释
如果对感知器学习的这种解释还不够清楚,我们还可以通过另一种更简洁的几何方法,来理解感知器如何学习对输入进行分类。对于只有两个输入单元的特殊情况,可以在二维图上用点来表示输入样本。每个输入都是图中的一个点,而网络中的两个权重则确定了一条直线。感知器学习的目标是移动这条线,以便清楚地区分正负样本。对于有三个输入单元的情况,输入空间是三维的,感知器会指定一个平面来分隔正负训练样本。在一般的情况下,即使输入空间的维度可能相当高且无法可视化,同样的原则依然成立。
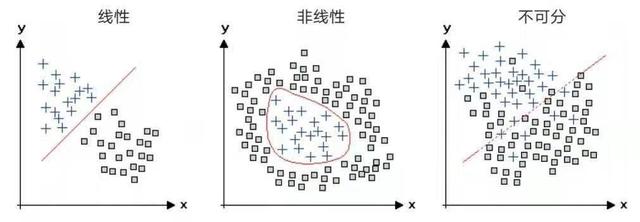
这些对象有两个特征,例如尺寸和亮度,它们依据各自的坐标值(x,y)被绘制在每张图上。左边图中的两种对象(加号和正方形)可以通过它们之间的直线分隔开;感知器能够学习如何进行这种区分。其他两个图中的两种对象不能用直线隔开,但在中间的图中,两种对象可以用曲线分开。而右侧图中的对象必须舍弃一些样本才能分隔成两种类型。如果有足够的训练数据,深度学习网络就能够学习如何对这三个图中的类型进行区分。
最终,如果解决方案是可行的,权重将不再变化,这意味着感知器已经正确地将训练集中的所有样本进行了分类。
但是,在所谓的“过度拟合”(overfitting)中,也可能没有足够的样本,网络仅仅记住了特定的样本,而不能将结论推广到新的样本。为了避免过度拟合,关键是要有另一套样本,称为“测试集”(test set),它没有被用于训练网络。训练结束时,在测试集上的分类表现,就是对感知器是否能够推广到类别未知的新样本的真实度量。泛化(generalization)是这里的关键概念。在现实生活中,我们几乎不会在同样的视角看到同一个对象,或者反复遇到同样的场景,但如果我们能够将以前的经验泛化到新的视角或场景中,我们就可以处理更多现实世界的问题。
利用感知器区分性别
举一个用感知器解决现实世界问题的例子。想想如果去掉头发、首饰和第二性征,比如男性比女性更为突起的喉结,该如何区分男性和女性的面部。
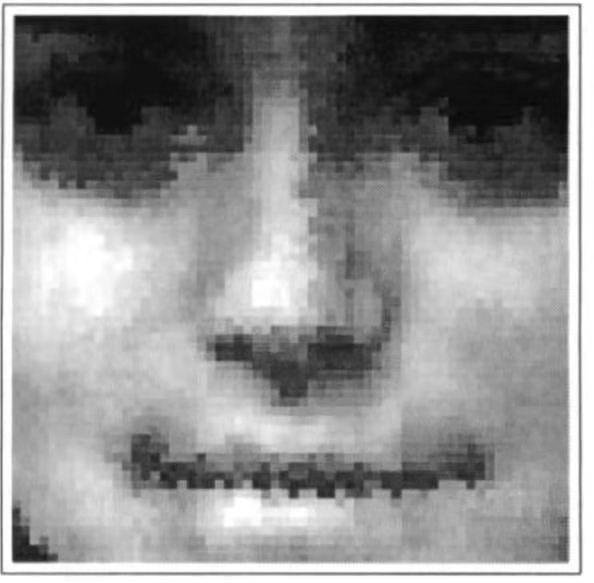
这张脸属于男性还是女性?人们通过训练感知器来辨别男性和女性的面孔。来自面部图像(上图)的像素乘以相应的权重(下图),并将该乘积的总和与阈值进行比较。每个权重的大小被描绘为不同颜色像素的面积。正值的权重(白色)表现为男性,负值的权重(黑色)倾向于女性。鼻子宽度,鼻子和嘴之间区域的大小,以及眼睛区域周围的图像强度对于区分男性很重要,而嘴和颧骨周围的图像强度对于区分女性更重要。

区分男性与女性面部的工作有趣的一点是,虽然我们很擅长做这种区分,却无法确切地表述男女面部之间的差异。由于没有单一特征是决定性的,因此这种模式识别问题要依赖于将大量低级特征的证据结合起来。感知器的优点在于,权重提供了对性别区分最有帮助的面部的线索。令人惊讶的是,人中(即鼻子和嘴唇之间的部分)是最显著的特征,大多数男性人中的面积更大。眼睛周围的区域(男性较大)和上颊(女性较大)对于性别分类也有着很高的信息价值。感知器会权衡来自所有这些位置的证据来做出决定,我们也是这样来做判定的,尽管我们可能无法描述出到底是怎么做到的。
感知器的扩展
感知器激发了对高维空间中模式分离的美妙的数学分析。当那些点存在于有数千个维度的空间中时,我们就无法依赖在生活的三维空间里对点和点之间距离的直觉。俄罗斯数学家弗拉基米尔·瓦普尼克(Vladimir Vapnik)在这种分析的基础上引入了一个分类器,称为“支持向量机”(Support Vector Machine)。
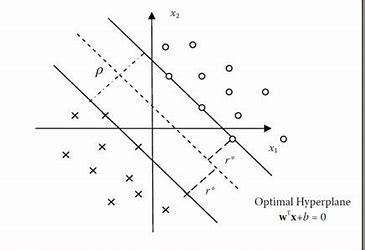
它将感知器泛化,并被大量用于机器学习。他找到了一种自动寻找平面的方法,能够最大限度地将两个类别的点分开(线性)。这让泛化对空间中数据点的测量误差容忍度更大,再结合作为非线性扩充的“内核技巧”(kernel trick),支持向量机算法就成了机器学习中的重要支柱。
“机器学习中感知器是怎么产生的”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





