本篇内容介绍了“ASCII、Unicode、UTF-8编码问题实例分析”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
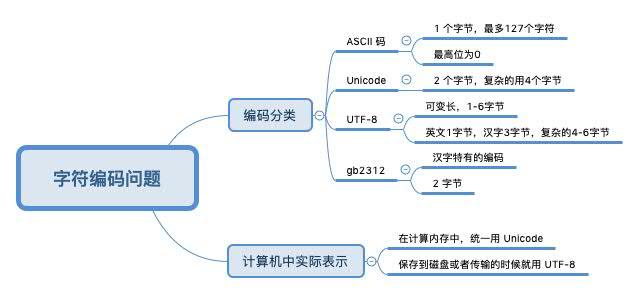
以往我们可能了解的都是一些理论知道,下面我们来通过 Python3 来验证一下。分别来看看英文字符 ‘A’ 和 ‘中’ 分别在不同编码下的实际情况。
A 的 ASCII 、UTF-8、GB2312 编码
>>> 'A'.encode('ascii')
b'A'
>>> 'A'.encode('utf-8')
b'A'
>>> 'A'.encode('gb2312')
b'A'中的 ASCII 、UTF-8、GB2312 编码
>>> '中'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode character '\\u4e2d' in position 0: ordinal not in range(128)
>>> '中'.encode('utf-8')
b'\\xe4\\xb8\\xad'
>>> '中'.encode('gb2312')
b'\\xd6\\xd0'可以看到中文是不能进行 ASCII 编码的
“ASCII、Unicode、UTF-8编码问题实例分析”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





