这篇文章给大家介绍Media Pipeline如何爬取妹子图,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
我们在抓取数据的过程中,除了要抓取文本数据之外,当然也会有抓取图片的需求。那我们的 scrapy 能爬取图片吗?答案是,当然的。说来惭愧,我也是上个月才知道,在 zone7 粉丝群中,有群友问 scrapy 怎么爬取图片数据?后来搜索了一下才知道。现在总结一下分享出来。
我们的 itempipeline 处理可以处理文字信息以外,还可以保存文件和图片数据,分别是 FilesPipeline 和 ImagesPipeline
避免重新下载最近已经下载过的数据
指定存储路径
在一个爬虫里,你抓取一个项目,把其中图片的URL放入 file_urls 组内。
项目从爬虫内返回,进入项目管道。
当项目进入 FilesPipeline,file_urls 组内的URLs将被Scrapy的调度器和下载器(这意味着调度器和下载器的中间件可以复用)安排下载,当优先级更高,- - 会在其他页面被抓取前处理。项目会在这个特定的管道阶段保持“locker”的状态,直到完成文件的下载(或者由于某些原因未完成下载)。
当文件下载完后,另一个字段(files)将被更新到结构中。这个组将包含一个字典列表,其中包括下载文件的信息,比如下载路径、源抓取地址(从 file_urls 组获得)和图片的校验码(checksum)。 files 列表中的文件顺序将和源 file_urls 组保持一致。如果某个图片下载失败,将会记录下错误信息,图片也不会出现在 files 组中。
避免重新下载最近已经下载过的数据
指定存储路径
将所有下载的图片转换成通用的格式(JPG)和模式(RGB)
缩略图生成
检测图像的宽/高,确保它们满足最小限制
# 同时启用图片和文件管道ITEM_PIPELINES = { # 使用时,请修改成你自己的 ImgPipeline 'girlScrapy.pipelines.ImgPipeline': 1,}FILES_STORE = os.getcwd() + '/girlScrapy/file' # 文件存储路径IMAGES_STORE = os.getcwd() + '/girlScrapy/img' # 图片存储路径# 避免下载最近90天已经下载过的文件内容FILES_EXPIRES = 90# 避免下载最近90天已经下载过的图像内容IMAGES_EXPIRES = 30# 设置图片缩略图IMAGES_THUMBS = { 'small': (50, 50), 'big': (250, 250),}# 图片过滤器,最小高度和宽度,低于此尺寸不下载IMAGES_MIN_HEIGHT = 128IMAGES_MIN_WIDTH = 128需要说明的是,你下载的图片名最终会以图片 URL 的 hash 值命名,例如:
0bddea29939becd7ad1e4160bbb4ec2238accbd9.jpg
最终的保存地址为:
your/img/path/full/0bddea29939becd7ad1e4160bbb4ec2238accbd9.jpg这是我 demo 中的一个 ImgPipeline,里面重写了两个方法。
from scrapy.pipelines.images import ImagesPipelineclass ImgPipeline(ImagesPipeline):#继承 ImagesPipeline 这个类 def get_media_requests(self, item, info): for image_url in item['image_urls']: image_url = image_url yield scrapy.Request(image_url) def item_completed(self, results, item, info): image_paths = [x['path'] for ok, x in results if ok] if not image_paths: raise DropItem("Item contains no images") return item分别是:
get_media_requests(self, item, info):item_completed(self, results, item, info):在这里,我们可以获取到 parse 中解析的 item 值,因此我们可以获取到相应的图片地址。在这里返回一个 scrapy.Request(image_url) 去下载图片。
item 和 info 打印出来都是 url 地址列表。其中 results 打印出来是如下值。
# 成功[(True, {'path': 'full/0bddea29939becd7ad1e4160bbb4ec2238accbd9.jpg', 'checksum': '98eb559631127d7611b499dfed0b6406', 'url': 'http://mm.chinasareview.com/wp-content/uploads/2017a/06/13/01.jpg'})]# 错误[(False, Failure(...))]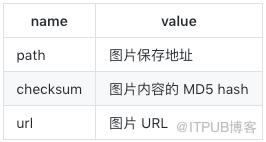
ok,理论部分也讲完了,那我们来实践一下吧
spider 部分很简单,如下:
class GirlSpider(scrapy.spiders.Spider): name = 'girl' start_urls = ["http://www.meizitu.com/a/3741.html"] def parse(self, response): soup = BeautifulSoup(response.body, 'html5lib') pic_list = soup.find('div', id="picture").find_all('img') # 找到界面所有图片 link_list = [] item = ImgItem() for i in pic_list: pic_link = i.get('src') # 拿到图片的具体 url link_list.append(pic_link) # 提取图片链接 item['image_urls'] = link_list print(item) yield itemclass ImgItem(scrapy.Item): image_urls = scrapy.Field()#图片的链接 images = scrapy.Field()class ImgPipeline(ImagesPipeline):#继承 ImagesPipeline 这个类 def get_media_requests(self, item, info): for image_url in item['image_urls']: image_url = image_url yield scrapy.Request(image_url) def item_completed(self, results, item, info): image_paths = [x['path'] for ok, x in results if ok] if not image_paths: raise DropItem("Item contains no images") return itemscrapy crawl girl
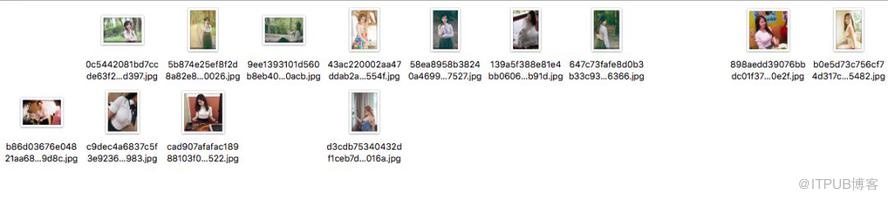
最终爬取结果如下:
关于Media Pipeline如何爬取妹子图就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/31556697/viewspace-2285293/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



