Oracle数据库---对象中最基本的是表和视图,其他还有约束、索引、序列、函数、存储过程、甚至创建同义词。对数据库的操作可以基本归结为对数据对象的操作,因此,在上篇博文讲述了基本操作的基础上,本篇博文将介绍其对象的基本操作。
- Oracle中表是数据存储的基本结构。随之引入了分区表和对象表,后来又引入了临时表,使表的功能更强大。
- 视图是一个或多个表中数据的逻辑表达式。用户可以将视图看成一个存储查询(stored query)或一个虚拟表(virtual table).查询仅仅存储在oracle数据字典中,实际的数据没有存放在任何其它地方,所以建立视图不用消耗其他的空间。视图也可以隐藏复杂查询。
在上一篇博文已详细阐述,创建表空间---创建用户(c##jerry)---创建表(info),表环境如下:
SQL>create table info
2 (
3 id number(4) constraint PK_id primary key, #constraint :约束
4 name varchar2(10),
5 score number(5,2),
6 born date,
7 address varchar2(50)
8 );
SQL>insert into info values(1,'zhangsan',88,to_date('2018-10-9','yyyy-mm-dd'),'nanjing');
SQL>insert into info values(2,'lisi',77,null,null);
SQL>insert into info values(3,'lwangwu',77,null,null);
SQL>commit;
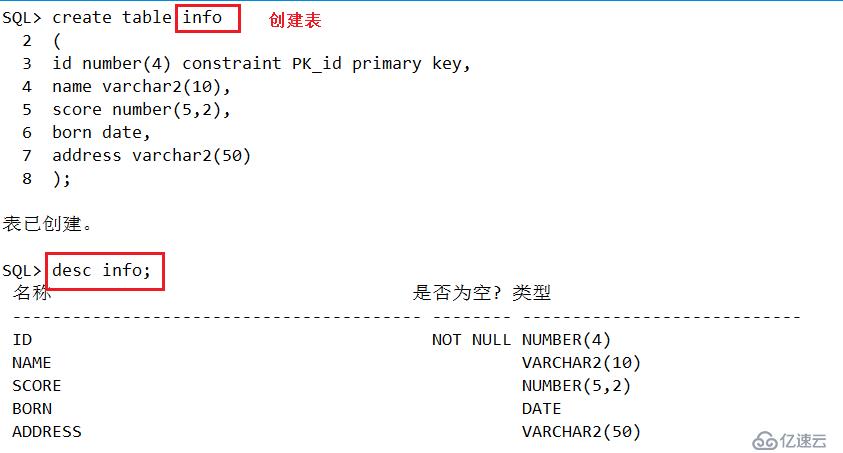
SQL>create view view_info as select * from info; #创建视图
select view view_info as select * from info; #查看视图
drop view view_info; #删除视图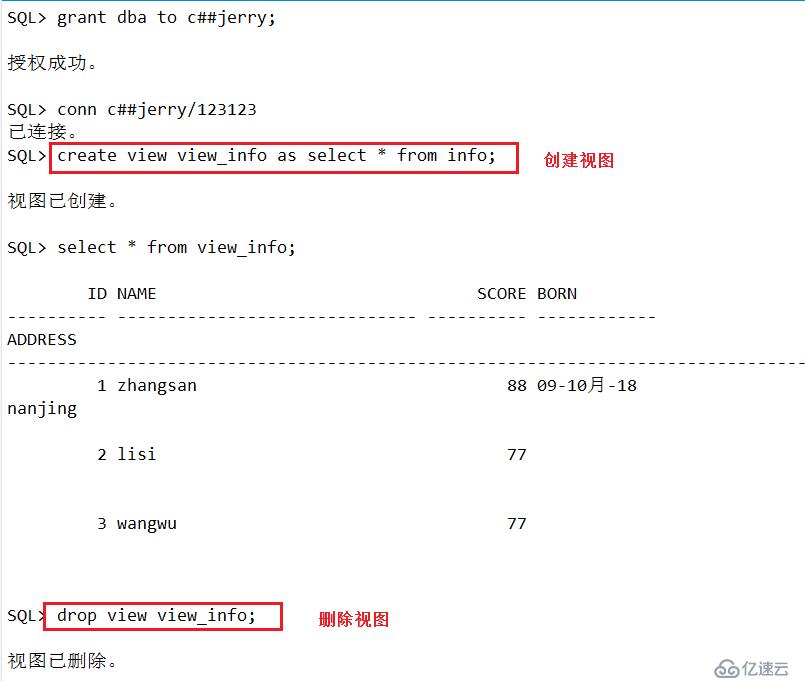
物化视图是包括一个查询结果的数据库对像,它是远程数据的的本地副本,或者用来生成基于数据表求和的汇总表。物化视图存储基于远程表的数据,也可以称为快照。
SQL>conn sys/abc123 as sysdba #切换到管理员
grant create materialized view to c##jerry; #创建物化视图
grant query rewrite to c##jerry; #查询重写
grant create any table to c##jerry; #创建任何表
grant select any table to c##jerry; #查看任何表
SQL>create materialized view log on info;
SQL>create materialized view mtrlview_info #建立物化视图名称
build immediate #立马生成数据
refresh fast #刷新(不开启此功能=快照)
on commit #开启提交功能
enable query rewrite #开启查询重写
as
select语句;SQL>drop materialized view mtrlview_info;
索引是一种可以提高查询性能的数据结构,分为以下几类:
SQL>create index score_index on info(score);
SQL>create unique index uni_index_info on info(id);
SQL>create index re_index_info on info(score) reverse;
SQL>create bitmap index bit_index_info on info(address);
SQL>create index upp_index_info on info(upper(name)); #大写函数索引
SQL>select index_name,index_type,table_name,tablespace_name from user_indexes;

SQL>alter index 索引名称 rebuild;
SQL>alter index 索引名称 rebuild tablespace 表空间
SQL>alter index 索引名称 coalesce;
SQL>drop index 索引名称
Oracle序列是一个连续的数字生成器。序列常用于人为的关键字,或给数据行排序否则数据行是无序的。
SQL>create sequence toy_seq
start with 10 #初始值
increment by 1 #增量
maxvalue 2000 #最大值
nocycle #非循环(超过2000不重新开始)
cache 30; #缓存30个序列数字SQL>create table toy
2 (
3 id number(4) constraint PK_id primary key,
4 name varchar2(10),
5 score number(5,2),
6 born date,
7 );
SQL>insert into toy values (toy_seq.nextval,'zhangsan',88); #nextval:指针(固定) .为调用
SQL>insert into toy values (toy_seq.nextval,'zhangsan',77);
SQL>select toy_seq.currval from dual;
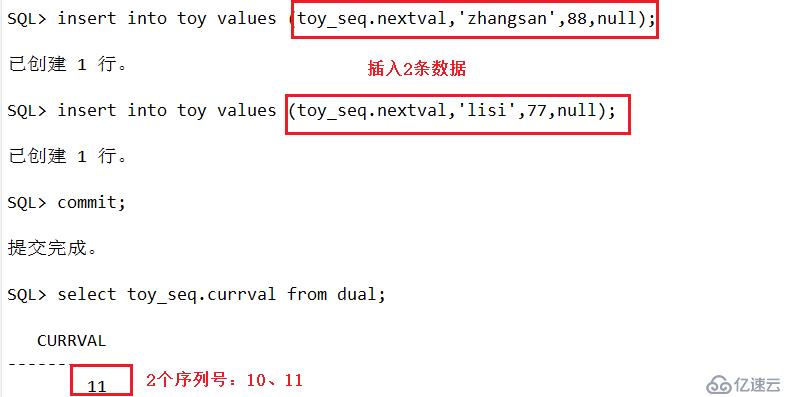
drop sequence toy_seq;
SQL>create synonym pr_info for info;
SQL>select * from pr_info; #通过同义词查看
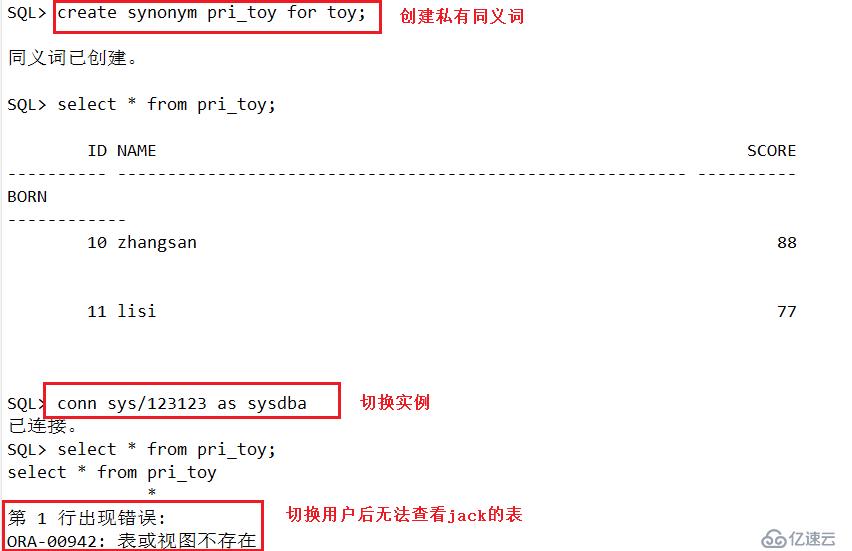
SQL>create public synonym pub_info for info;
SQL> select * from pub_info; #查看

为解决海量数据存储问题
SQL>create tablespace tmp01
datafile '/orc/app/oracle/oradata/tmp01.dbf'
size 100M;
SQL>create tablespace tmp02
datafile '/orc/app/oracle/oradata/tmp02.dbf'
size 100M;
SQL>create tablespace tmp03
datafile '/orc/app/oracle/oradata/tmp03.dbf'
size 100M;
SQL>create tablespace tmp04
datafile '/orc/app/oracle/oradata/tmp04.dbf'
size 100M;
create table sales
(
sales_id number,
product_id vachar2(5),
sales_date date
)
partition by range (sales_date)
(
partition p1 values less than (to_date('2018-04-03','yyyy-mm-dd')) tablespace tmp01,
partition p2 values less than (to_date('2018-05-03','yyyy-mm-dd')) tablespace tmp02,
partition p3 values less than (to_date('2018-06-03','yyyy-mm-dd')) tablespace tmp03,
partition p4 values less than (maxvalue) tablespace tmp04
);//插入数据,查看是否实现分布式存储
insert into sales values(1,'abc',to_date('2018-05-23','yyyy-mm-dd'));
select * from sales partition(p3);
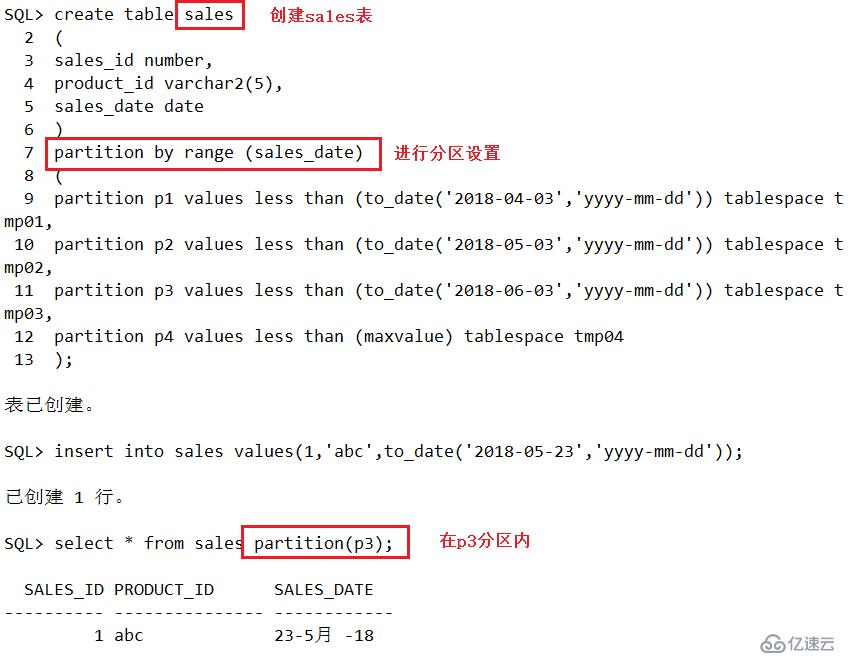
#结果显示:输入数据日期为2018-05-23,应该存储在p3分区内,而其他分区没有此条数据!
感谢大家的阅读,希望共同进步!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





