只有光头才能变强
今天继续来学习Redis,上一篇从零单排学Redis【青铜】已经将Redis常用的数据结构过了一遍了。如果还没看的同学可以先去看一遍再回来~
这篇主要讲的内容有:
Redis服务器的数据库
Redis对过期键的处理
Redis持久化策略(RDB和AOF)
本文力求简单讲清每个知识点,希望大家看完能有所收获
我们应该都用过MySQL,MySQL我们可以在里边创建好几个库:
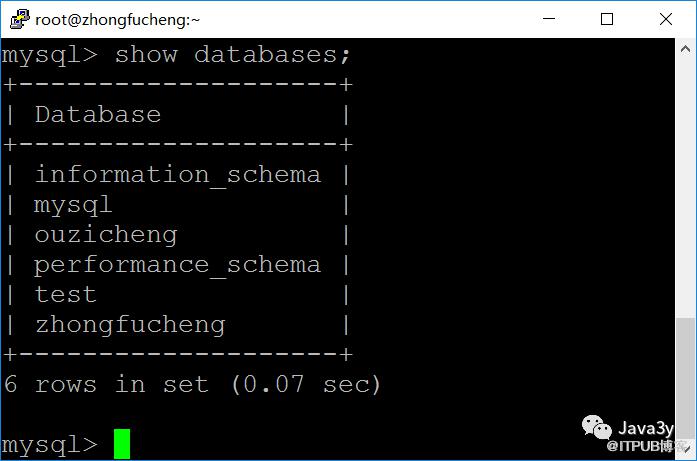
同样地,Redis服务器中也有数据库这么一个概念。如果不指定具体的数量,默认会有16个数据库。
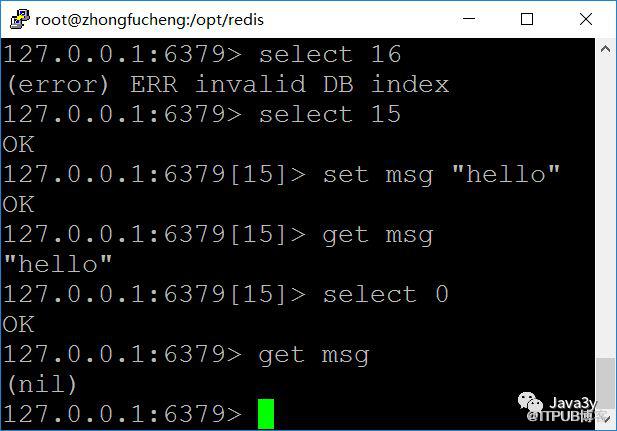
上面的命令我们也可以发现:当切换到15号数据库,存进15号库的数据,再切换到0号数据库时,是获取不到的!
这说明,数据库与数据库之间的数据是隔离的。
Redis服务器用redisServer结构体来表示,其中redisDb是一个数组,用来保存所有的数据库,dbnum代表数据库的数量(这个可以配置,默认是16)
struct redisServer{
//redisDb数组,表示服务器中所有的数据库
redisDb *db;
//服务器中数据库的数量
int dbnum;
};
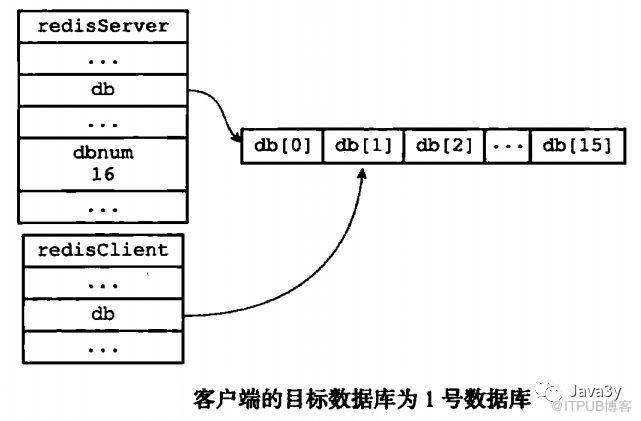
我们知道Redis是C/S结构,Redis客户端通过redisClient结构体来表示:
typedef struct redisClient{
//客户端当前所选数据库
redisDb *db;
}redisClient;
Redis客户端连接Redis服务端时的示例图:
Redis中对每个数据库用redisDb结构体来表示:
typedef struct redisDb {
int id; // 数据库ID标识
dict *dict; // 键空间,存放着所有的键值对
dict *expires; // 过期哈希表,保存着键的过期时间
dict *watched_keys; // 被watch命令监控的key和相应client
long long avg_ttl; // 数据库内所有键的平均TTL(生存时间)
} redisDb;
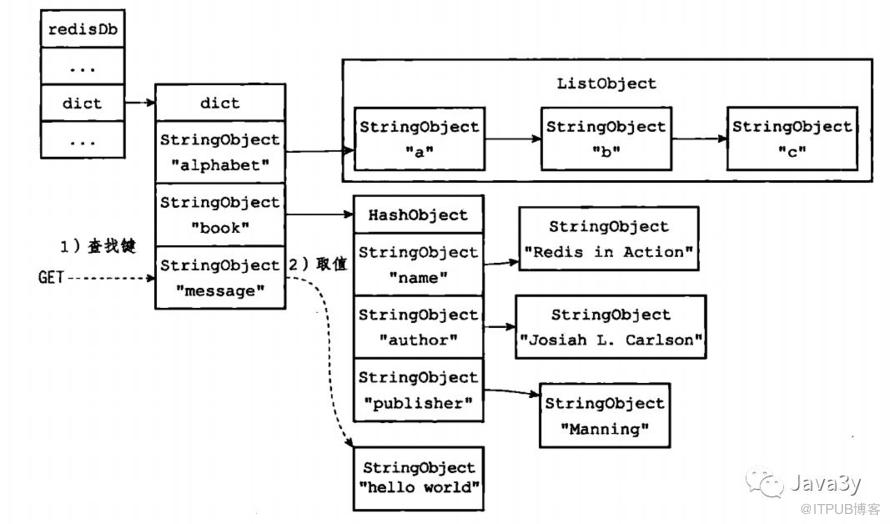
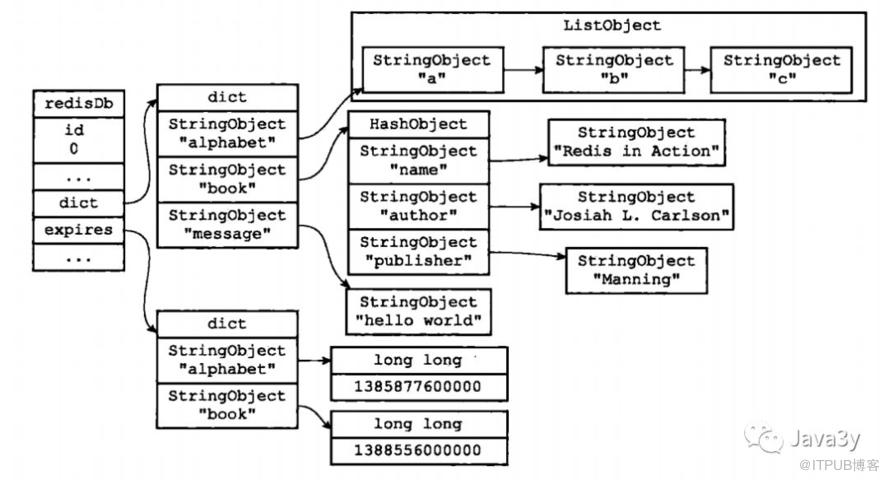
从代码上我们可以发现最重要的应该是dict *dict,它用来存放着所有的键值对。对于dict数据结构(哈希表)我们在上一篇也已经详细说了。一般我们将存储所有键值对的dict称为键空间。
键空间示意图:
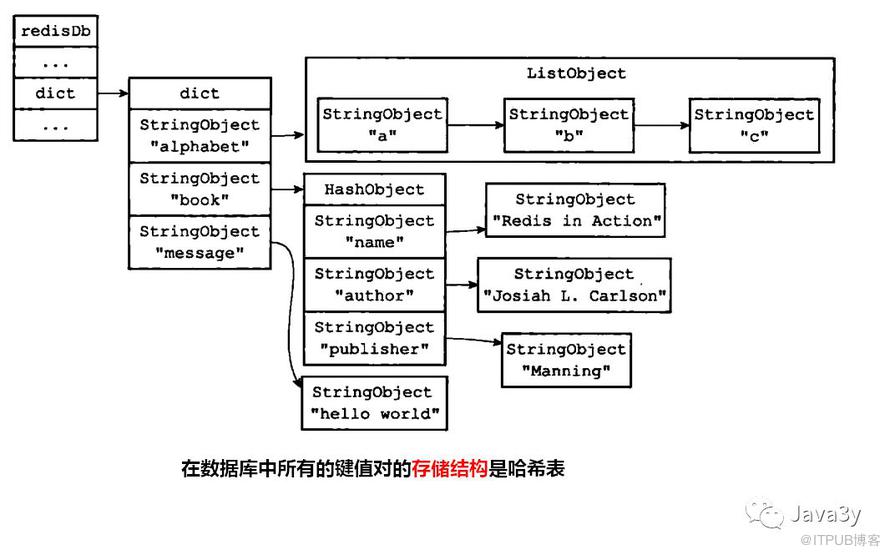
Redis的数据库就是使用字典(哈希表)来作为底层实现的,对数据库的增删改查都是构建在字典(哈希表)的操作之上的。
例如:
redis > GET message
"hello world"
Redis是基于内存,内存是比较昂贵的,容量肯定比不上硬盘的。就我们现在一台普通的机子,可能就8G内存,但硬盘随随便便都1T了。
因为我们的内存是有限的。所以我们会干掉不常用的数据,保留常用的数据。这就需要我们设置一下键的过期(生存)时间了。
设置键的生存时间可以通过EXPIRE或者PEXPIRE命令。
设置键的过期时间可以通过EXPIREAT或者PEXPIREAT命令。
其实EXPIRE、PEXPIRE、EXPIREAT这三个命令都是通过PEXPIREAT命令来实现的。
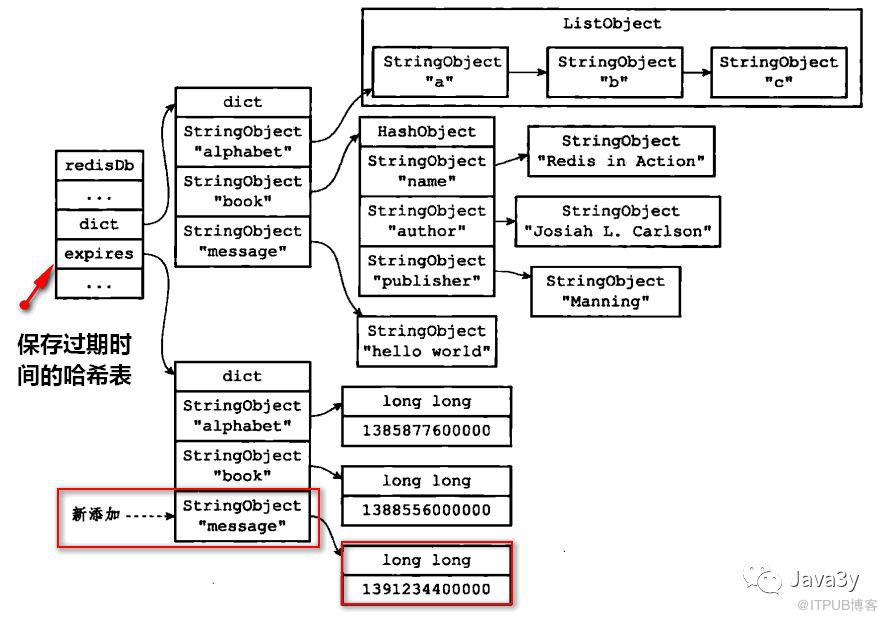
我们在redisDb结构体中还发现了dict *expires;属性,存放所有键过期的时间。
举个例子基本就可以理解了:
redis > PEXPIREAT message 1391234400000
(integer) 1
设置了message键的过期时间为1391234400000
既然有设置过期(生存)时间的命令,那肯定也有移除过期时间,查看剩余生存时间的命令了:
PERSIST(移除过期时间)
TTL(Time To Live)返回剩余生存时间,以秒为单位
PTTL以毫秒为单位返回键的剩余生存时间
上面我们已经能够了解到:过期键是保存在哈希表中了。那这些过期键到了过期的时间,就会立马被删除掉吗??
要回答上面的问题,需要我们了解一下删除策略的知识,删除策略可分为三种
定时删除(对内存友好,对CPU不友好)
到时间点上就把所有过期的键删除了。
惰性删除(对CPU极度友好,对内存极度不友好)
每次从键空间取键的时候,判断一下该键是否过期了,如果过期了就删除。
定期删除(折中)
每隔一段时间去删除过期键,限制删除的执行时长和频率。
Redis采用的是惰性删除+定期删除两种策略,所以说,在Redis里边如果过期键到了过期的时间了,未必被立马删除的!
如果定期删除漏掉了很多过期key,也没及时去查(没走惰性删除),大量过期key堆积在内存里,导致redis内存块耗尽了,咋整?
我们可以设置内存最大使用量,当内存使用量超出时,会施行数据淘汰策略。
Redis的内存淘汰机制有以下几种:
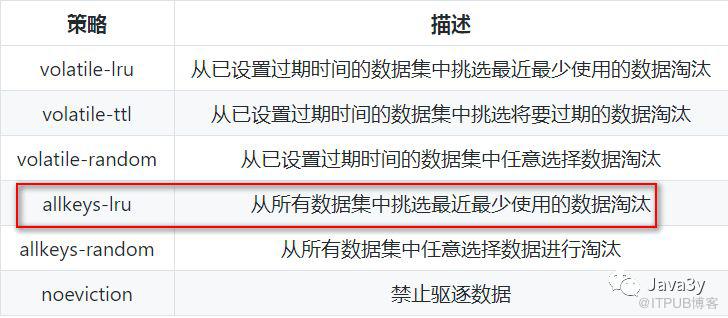
一般场景:
使用 Redis 缓存数据时,为了提高缓存命中率,需要保证缓存数据都是热点数据。可以将内存最大使用量设置为热点数据占用的内存量,然后启用allkeys-lru淘汰策略,将最近最少使用的数据淘汰
Redis是基于内存的,如果不想办法将数据保存在硬盘上,一旦Redis重启(退出/故障),内存的数据将会全部丢失。
我们肯定不想Redis里头的数据由于某些故障全部丢失(导致所有请求都走MySQL),即便发生了故障也希望可以将Redis原有的数据恢复过来,这就是持久化的作用。
Redis提供了两种不同的持久化方法来讲数据存储到硬盘里边:
RDB(基于快照),将某一时刻的所有数据保存到一个RDB文件中。
AOF(append-only-file),当Redis服务器执行写命令的时候,将执行的写命令保存到AOF文件中。
RDB持久化可以手动执行,也可以根据服务器配置定期执行。RDB持久化所生成的RDB文件是一个经过压缩的二进制文件,Redis可以通过这个文件还原数据库的数据。

有两个命令可以生成RDB文件:
SAVE会阻塞Redis服务器进程,服务器不能接收任何请求,直到RDB文件创建完毕为止。
BGSAVE创建出一个子进程,由子进程来负责创建RDB文件,服务器进程可以继续接收请求。
Redis服务器在启动的时候,如果发现有RDB文件,就会自动载入RDB文件(不需要人工干预)
服务器在载入RDB文件期间,会处于阻塞状态,直到载入工作完成。
除了手动调用SAVE或者BGSAVE命令生成RDB文件之外,我们可以使用配置的方式来定期执行:
在默认的配置下,如果以下的条件被触发,就会执行BGSAVE命令
save 900 1 #在900秒(15分钟)之后,至少有1个key发生变化,
save 300 10 #在300秒(5分钟)之后,至少有10个key发生变化
save 60 10000 #在60秒(1分钟)之后,至少有10000个key发生变化
原理大概就是这样子的(结合上面的配置来看):
struct redisServer{
// 修改计数器
long long dirty;
// 上一次执行保存的时间
time_t lastsave;
// 参数的配置
struct saveparam *saveparams;
};
遍历参数数组,判断修改次数和时间是否符合,如果符合则调用besave()来生成RDB文件

总结:通过手动调用SAVE或者BGSAVE命令或者配置条件触发,将数据库某一时刻的数据快照,生成RDB文件实现持久化。
上面已经介绍了RDB持久化是通过将某一时刻数据库的数据“快照”来实现的,下面我们来看看AOF是怎么实现的。
AOF是通过保存Redis服务器所执行的写命令来记录数据库的数据的。
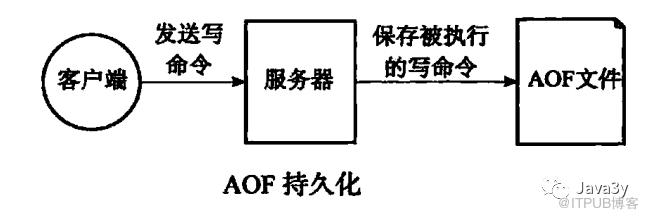
比如说我们对空白的数据库执行以下写命令:
redis> SET meg "hello"
OK
redis> SADD fruits "apple" "banana" "cherry"
(integer) 3
redis> RPUSH numbers 128 256 512
(integer) 3
Redis会产生以下内容的AOF文件:

这些都是以Redis的命令请求协议格式保存的。Redis协议规范(RESP)参考资料:
https://www.cnblogs.com/tommy-huang/p/6051577.html
AOF持久化功能的实现可以分为3个步骤:
命令追加:命令写入aof_buf缓冲区
文件写入:调用flushAppendOnlyFile函数,考虑是否要将aof_buf缓冲区写入AOF文件中
文件同步:考虑是否将内存缓冲区的数据真正写入到硬盘
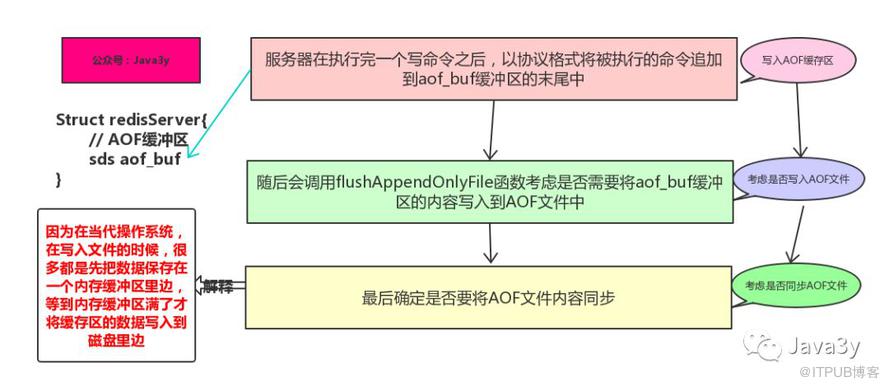
flushAppendOnlyFile函数的行为由服务器配置的appendfsyn选项来决定的:
appendfsync always # 每次有数据修改发生时都会写入AOF文件。
appendfsync everysec # 每秒钟同步一次,该策略为AOF的默认策略。
appendfsync no # 从不同步。高效但是数据不会被持久化。
从字面上应该就更好理解了,这里我就不细说了…
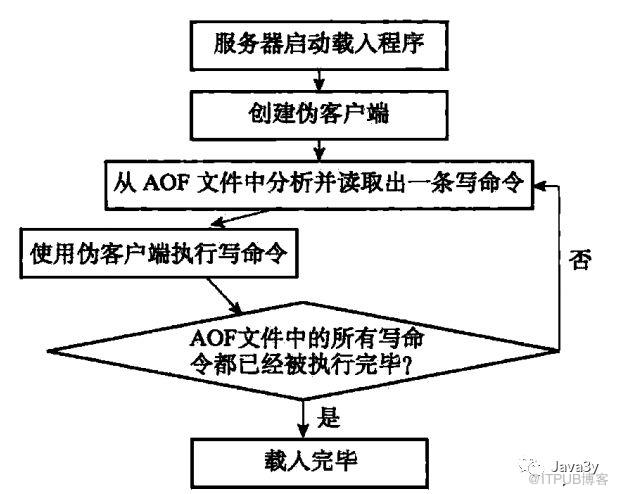
下面来看一下AOF是如何载入与数据还原的:
创建一个伪客户端(本地)来执行AOF的命令,直到AOF命令被全部执行完毕。
从前面的示例看出,我们写了三条命令,AOF文件就保存了三条命令。如果我们的命令是这样子的:
redis > RPUSH list "Java" "3y"
(integer)2
redis > RPUSH list "Java3y"
integer(3)
redis > RPUSH list "yyy"
integer(4)
同样地,AOF也会保存3条命令。我们会发现一个问题:上面的命令是可以合并起来成为1条命令的,并不需要3条。这样就可以让AOF文件的体积变得更小。
AOF重写由Redis自行触发(参数配置),也可以用BGREWRITEAOF命令手动触发重写操作。
要值得说明的是:AOF重写不需要对现有的AOF文件进行任何的读取、分析。AOF重写是通过读取服务器当前数据库的数据来实现的!
比如说现在有一个Redis数据库的数据如下:
新的AOF文件的命令如下,没有一条是多余的!

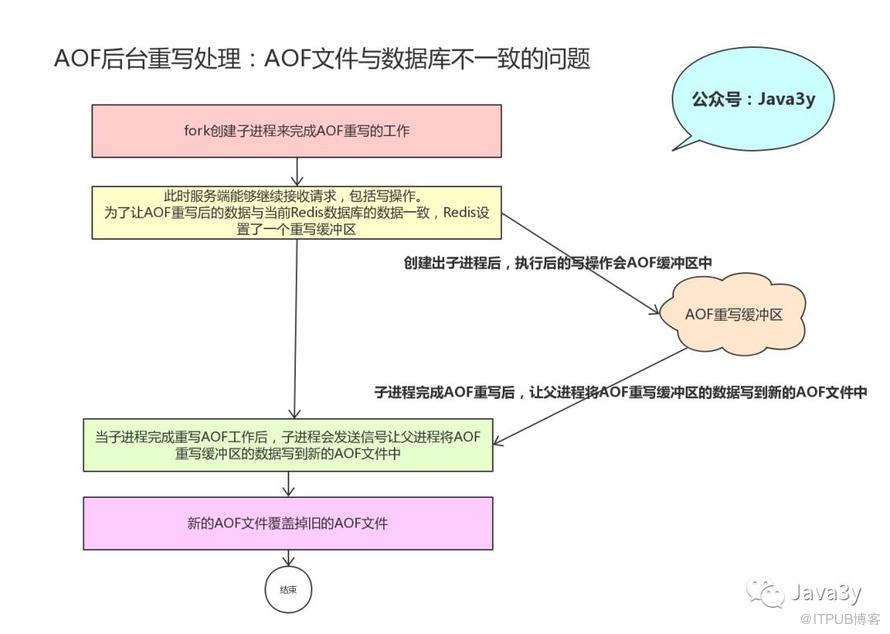
Redis将AOF重写程序放到子进程里执行(BGREWRITEAOF命令),像BGSAVE命令一样fork出一个子进程来完成重写AOF的操作,从而不会影响到主进程。
AOF后台重写是不会阻塞主进程接收请求的,新的写命令请求可能会导致当前数据库和重写后的AOF文件的数据不一致!
为了解决数据不一致的问题,Redis服务器设置了一个AOF重写缓冲区,这个缓存区会在服务器创建出子进程之后使用。
RDB持久化对过期键的策略:
执行SAVE或者BGSAVE命令创建出的RDB文件,程序会对数据库中的过期键检查,已过期的键不会保存在RDB文件中。
载入RDB文件时,程序同样会对RDB文件中的键进行检查,过期的键会被忽略。
RDB持久化对过期键的策略:
如果数据库的键已过期,但还没被惰性/定期删除,AOF文件不会因为这个过期键产生任何影响(也就说会保留),当过期的键被删除了以后,会追加一条DEL命令来显示记录该键被删除了
重写AOF文件时,程序会对RDB文件中的键进行检查,过期的键会被忽略。
复制模式:
主服务器来控制从服务器统一删除过期键(保证主从服务器数据的一致性)
RDB和AOF并不互斥,它俩可以同时使用。
RDB的优点:载入时恢复数据快、文件体积小。
RDB的缺点:会一定程度上丢失数据(因为系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。)
AOF的优点:丢失数据少(默认配置只丢失一秒的数据)。
AOF的缺点:恢复数据相对较慢,文件体积大
如果Redis服务器同时开启了RDB和AOF持久化,服务器会优先使用AOF文件来还原数据(因为AOF更新频率比RDB更新频率要高,还原的数据更完善)
可能涉及到RDB和AOF的配置:
redis持久化,两种方式
1、rdb快照方式
2、aof日志方式
----------rdb快照------------
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir /var/rdb/
-----------Aof的配置-----------
appendonly no # 是否打开 aof日志功能
appendfsync always #每一个命令都立即同步到aof,安全速度慢
appendfsync everysec
appendfsync no 写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到aof 同步频率低,速度快
no-appendfsync-on-rewrite yes 正在导出rdb快照的时候不要写aof
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
./bin/redis-benchmark -n 20000
官网文档:
https://redis.io/topics/persistence#rdb-advantages
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





