Hadoop Yarnзҡ„иө„жәҗи°ғеәҰеҷЁжңүе“Әдәӣ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңHadoop Yarnзҡ„иө„жәҗи°ғеәҰеҷЁжңүе“ӘдәӣвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁHadoop Yarnзҡ„иө„жәҗи°ғеәҰеҷЁжңүе“Әдәӣй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқHadoop Yarnзҡ„иө„жәҗи°ғеәҰеҷЁжңүе“ӘдәӣвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
дёҖгҖҒи°ғеәҰеҷЁзҡ„йҖүжӢ©
еңЁYarnдёӯжңүдёүз§Қи°ғеәҰеҷЁеҸҜд»ҘйҖүжӢ©пјҡFIFO Scheduler
пјҢCapacity SchedulerпјҢFairS chedulerгҖӮ
FIFO SchedulerжҠҠеә”з”ЁжҢүжҸҗдәӨзҡ„йЎәеәҸжҺ’жҲҗдёҖдёӘйҳҹеҲ—пјҢиҝҷжҳҜдёҖдёӘе…Ҳиҝӣе…ҲеҮәйҳҹеҲ—пјҢеңЁиҝӣиЎҢиө„жәҗеҲҶй…Қзҡ„ж—¶еҖҷпјҢе…Ҳз»ҷйҳҹеҲ—дёӯжңҖеӨҙдёҠзҡ„еә”з”ЁиҝӣиЎҢеҲҶй…Қиө„жәҗпјҢеҫ…жңҖеӨҙдёҠзҡ„еә”з”ЁйңҖжұӮж»Ўи¶іеҗҺеҶҚз»ҷдёӢдёҖдёӘеҲҶй…ҚпјҢд»ҘжӯӨзұ»жҺЁгҖӮ
FIFO SchedulerжҳҜжңҖз®ҖеҚ•д№ҹжҳҜжңҖе®№жҳ“зҗҶи§Јзҡ„и°ғеәҰеҷЁпјҢд№ҹдёҚйңҖиҰҒд»»дҪ•й…ҚзҪ®пјҢдҪҶе®ғ并дёҚйҖӮз”ЁдәҺе…ұдә«йӣҶзҫӨгҖӮеӨ§зҡ„еә”з”ЁеҸҜиғҪдјҡеҚ з”ЁжүҖжңүйӣҶзҫӨиө„жәҗпјҢиҝҷе°ұеҜјиҮҙе…¶е®ғеә”з”Ёиў«йҳ»еЎһгҖӮеңЁе…ұдә«йӣҶзҫӨдёӯпјҢжӣҙйҖӮеҗҲйҮҮз”ЁCapacity SchedulerжҲ–Fair SchedulerпјҢиҝҷдёӨдёӘи°ғеәҰеҷЁйғҪе…Ғи®ёеӨ§д»»еҠЎе’Ңе°Ҹд»»еҠЎеңЁжҸҗдәӨзҡ„еҗҢж—¶иҺ·еҫ—дёҖе®ҡзҡ„зі»з»ҹиө„жәҗгҖӮ
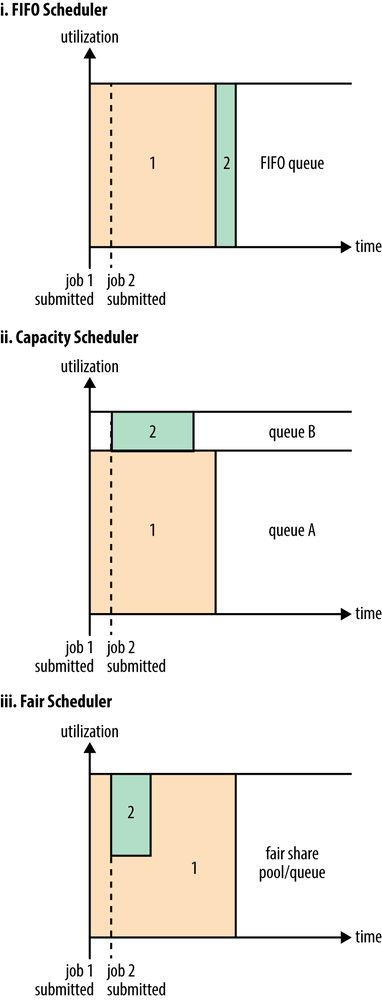
дёӢйқўвҖңYarnи°ғеәҰеҷЁеҜ№жҜ”еӣҫвҖқеұ•зӨәдәҶиҝҷеҮ дёӘи°ғеәҰеҷЁзҡ„еҢәеҲ«пјҢд»ҺеӣҫдёӯеҸҜд»ҘзңӢеҮәпјҢеңЁFIFO и°ғеәҰеҷЁдёӯпјҢе°Ҹд»»еҠЎдјҡиў«еӨ§д»»еҠЎйҳ»еЎһгҖӮ
иҖҢеҜ№дәҺCapacityи°ғеәҰеҷЁпјҢжңүдёҖдёӘдё“й—Ёзҡ„йҳҹеҲ—з”ЁжқҘиҝҗиЎҢе°Ҹд»»еҠЎпјҢдҪҶжҳҜдёәе°Ҹд»»еҠЎдё“й—Ёи®ҫзҪ®дёҖдёӘйҳҹеҲ—дјҡйў„е…ҲеҚ з”ЁдёҖе®ҡзҡ„йӣҶзҫӨиө„жәҗпјҢиҝҷе°ұеҜјиҮҙеӨ§д»»еҠЎзҡ„жү§иЎҢж—¶й—ҙдјҡиҗҪеҗҺдәҺдҪҝз”ЁFIFOи°ғеәҰеҷЁж—¶зҡ„ж—¶й—ҙгҖӮ
еңЁFairи°ғеәҰеҷЁдёӯпјҢжҲ‘们дёҚйңҖиҰҒйў„е…ҲеҚ з”ЁдёҖе®ҡзҡ„зі»з»ҹиө„жәҗпјҢFairи°ғеәҰеҷЁдјҡдёәжүҖжңүиҝҗиЎҢзҡ„jobеҠЁжҖҒзҡ„и°ғж•ҙзі»з»ҹиө„жәҗгҖӮеҰӮдёӢеӣҫжүҖзӨәпјҢеҪ“第дёҖдёӘеӨ§jobжҸҗдәӨж—¶пјҢеҸӘжңүиҝҷдёҖдёӘjobеңЁиҝҗиЎҢпјҢжӯӨж—¶е®ғиҺ·еҫ—дәҶжүҖжңүйӣҶзҫӨиө„жәҗпјӣеҪ“第дәҢдёӘе°Ҹд»»еҠЎжҸҗдәӨеҗҺпјҢFairи°ғеәҰеҷЁдјҡеҲҶй…ҚдёҖеҚҠиө„жәҗз»ҷиҝҷдёӘе°Ҹд»»еҠЎпјҢи®©иҝҷдёӨдёӘд»»еҠЎе…¬е№ізҡ„е…ұдә«йӣҶзҫӨиө„жәҗгҖӮ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеңЁдёӢеӣҫFairи°ғеәҰеҷЁдёӯпјҢд»Һ第дәҢдёӘд»»еҠЎжҸҗдәӨеҲ°иҺ·еҫ—иө„жәҗдјҡжңүдёҖе®ҡзҡ„延иҝҹпјҢеӣ дёәе®ғйңҖиҰҒзӯүеҫ…第дёҖдёӘд»»еҠЎйҮҠж”ҫеҚ з”Ёзҡ„ContainerгҖӮе°Ҹд»»еҠЎжү§иЎҢе®ҢжҲҗд№ӢеҗҺд№ҹдјҡйҮҠж”ҫиҮӘе·ұеҚ з”Ёзҡ„иө„жәҗпјҢеӨ§д»»еҠЎеҸҲиҺ·еҫ—дәҶе…ЁйғЁзҡ„зі»з»ҹиө„жәҗгҖӮжңҖз»Ҳзҡ„ж•Ҳжһңе°ұжҳҜFairи°ғеәҰеҷЁеҚіеҫ—еҲ°дәҶй«ҳзҡ„иө„жәҗеҲ©з”ЁзҺҮеҸҲиғҪдҝқиҜҒе°Ҹд»»еҠЎеҸҠж—¶е®ҢжҲҗгҖӮ
Yarnи°ғеәҰеҷЁеҜ№жҜ”еӣҫ:
дәҢгҖҒCapacity SchedulerпјҲе®№еҷЁи°ғеәҰеҷЁпјүзҡ„й…ҚзҪ®
2.1 е®№еҷЁи°ғеәҰд»Ӣз»Қ
Capacity
и°ғеәҰеҷЁе…Ғи®ёеӨҡдёӘз»„з»Үе…ұдә«ж•ҙдёӘйӣҶзҫӨпјҢжҜҸдёӘз»„з»ҮеҸҜд»ҘиҺ·еҫ—йӣҶзҫӨзҡ„дёҖйғЁеҲҶи®Ўз®—иғҪеҠӣгҖӮйҖҡиҝҮдёәжҜҸдёӘз»„з»ҮеҲҶй…Қдё“й—Ёзҡ„йҳҹеҲ—пјҢ然еҗҺеҶҚдёәжҜҸдёӘйҳҹеҲ—еҲҶй…ҚдёҖе®ҡзҡ„йӣҶзҫӨиө„жәҗпјҢиҝҷж ·ж•ҙдёӘйӣҶзҫӨе°ұеҸҜд»ҘйҖҡиҝҮи®ҫзҪ®еӨҡдёӘйҳҹеҲ—зҡ„ж–№ејҸз»ҷеӨҡдёӘз»„з»ҮжҸҗдҫӣжңҚеҠЎдәҶгҖӮйҷӨжӯӨд№ӢеӨ–пјҢйҳҹеҲ—еҶ…йғЁеҸҲеҸҜд»ҘеһӮзӣҙеҲ’еҲҶпјҢиҝҷж ·дёҖдёӘз»„з»ҮеҶ…йғЁзҡ„еӨҡдёӘжҲҗе‘ҳе°ұеҸҜд»Ҙе…ұдә«иҝҷдёӘйҳҹеҲ—иө„жәҗдәҶпјҢеңЁдёҖдёӘйҳҹеҲ—еҶ…йғЁпјҢиө„жәҗзҡ„и°ғеәҰжҳҜйҮҮз”Ёзҡ„жҳҜе…Ҳиҝӣе…ҲеҮә(FIFO)зӯ–з•ҘгҖӮ
йҖҡиҝҮдёҠйқўйӮЈе№…еӣҫпјҢжҲ‘们已з»ҸзҹҘйҒ“дёҖдёӘjobеҸҜиғҪдҪҝз”ЁдёҚдәҶж•ҙдёӘйҳҹеҲ—зҡ„иө„жәҗгҖӮ然иҖҢеҰӮжһңиҝҷдёӘйҳҹеҲ—дёӯиҝҗиЎҢеӨҡдёӘjobпјҢеҰӮжһңиҝҷдёӘйҳҹеҲ—зҡ„иө„жәҗеӨҹз”ЁпјҢйӮЈд№Ҳе°ұеҲҶй…Қз»ҷиҝҷдәӣjobпјҢеҰӮжһңиҝҷдёӘйҳҹеҲ—зҡ„иө„жәҗдёҚеӨҹз”ЁдәҶе‘ўпјҹе…¶е®һCapacityи°ғеәҰеҷЁд»ҚеҸҜиғҪеҲҶй…ҚйўқеӨ–зҡ„иө„жәҗз»ҷиҝҷдёӘйҳҹеҲ—пјҢиҝҷе°ұжҳҜвҖңеј№жҖ§йҳҹеҲ—вҖқ(queue elasticity)зҡ„жҰӮеҝөгҖӮ
еңЁжӯЈеёёзҡ„ж“ҚдҪңдёӯпјҢCapacityи°ғеәҰеҷЁдёҚдјҡејәеҲ¶йҮҠж”ҫContainerпјҢеҪ“дёҖдёӘйҳҹеҲ—иө„жәҗдёҚеӨҹз”Ёж—¶пјҢиҝҷдёӘйҳҹеҲ—еҸӘиғҪиҺ·еҫ—е…¶е®ғйҳҹеҲ—йҮҠж”ҫеҗҺзҡ„Containerиө„жәҗгҖӮеҪ“然пјҢжҲ‘们еҸҜд»ҘдёәйҳҹеҲ—и®ҫзҪ®дёҖдёӘжңҖеӨ§иө„жәҗдҪҝз”ЁйҮҸпјҢд»Ҙе…ҚиҝҷдёӘйҳҹеҲ—иҝҮеӨҡзҡ„еҚ з”Ёз©әй—Іиө„жәҗпјҢеҜјиҮҙе…¶е®ғйҳҹеҲ—ж— жі•дҪҝз”Ёиҝҷдәӣз©әй—Іиө„жәҗпјҢиҝҷе°ұжҳҜвҖқеј№жҖ§йҳҹеҲ—вҖқйңҖиҰҒжқғиЎЎзҡ„ең°ж–№гҖӮ
2.2 е®№еҷЁи°ғеәҰзҡ„й…ҚзҪ®
еҒҮи®ҫжҲ‘们жңүеҰӮдёӢеұӮж¬Ўзҡ„йҳҹеҲ—пјҡ
root
в”ңв”Җв”Җ prod
в””в”Җв”Җ dev
в”ңв”Җв”Җ eng
в””в”Җв”Җ science123456
дёӢйқўжҳҜдёҖдёӘз®ҖеҚ•зҡ„Capacityи°ғеәҰеҷЁзҡ„й…ҚзҪ®ж–Ү件пјҢж–Ү件еҗҚдёәcapacity-scheduler.xmlгҖӮеңЁиҝҷдёӘй…ҚзҪ®дёӯпјҢеңЁrootйҳҹеҲ—дёӢйқўе®ҡд№үдәҶдёӨдёӘеӯҗйҳҹеҲ—prodе’ҢdevпјҢеҲҶеҲ«еҚ 40%е’Ң60%зҡ„е®№йҮҸгҖӮйңҖиҰҒжіЁж„ҸпјҢдёҖдёӘйҳҹеҲ—зҡ„й…ҚзҪ®жҳҜйҖҡиҝҮеұһжҖ§yarn.sheduler.capacity.<queue-path>.<sub-property>жҢҮе®ҡзҡ„пјҢ<queue-path>д»ЈиЎЁзҡ„жҳҜйҳҹеҲ—зҡ„继жүҝж ‘пјҢеҰӮroot.prodйҳҹеҲ—пјҢ<sub-property>дёҖиҲ¬жҢҮcapacityе’Ңmaximum-capacityгҖӮ

жҲ‘们еҸҜд»ҘзңӢеҲ°пјҢdevйҳҹеҲ—еҸҲиў«еҲҶжҲҗдәҶengе’ҢscienceдёӨдёӘзӣёеҗҢе®№йҮҸзҡ„еӯҗйҳҹеҲ—гҖӮdevзҡ„maximum-capacityеұһжҖ§иў«и®ҫзҪ®жҲҗдәҶ75%пјҢжүҖд»ҘеҚідҪҝprodйҳҹеҲ—е®Ңе…Ёз©әй—Іdevд№ҹдёҚдјҡеҚ з”Ёе…ЁйғЁйӣҶзҫӨиө„жәҗпјҢд№ҹе°ұжҳҜиҜҙпјҢprodйҳҹеҲ—д»Қжңү25%зҡ„еҸҜз”Ёиө„жәҗз”ЁжқҘеә”жҖҘгҖӮжҲ‘们注ж„ҸеҲ°пјҢengе’ҢscienceдёӨдёӘйҳҹеҲ—жІЎжңүи®ҫзҪ®maximum-capacityеұһжҖ§пјҢд№ҹе°ұжҳҜиҜҙengжҲ–scienceйҳҹеҲ—дёӯзҡ„jobеҸҜиғҪдјҡз”ЁеҲ°ж•ҙдёӘdevйҳҹеҲ—зҡ„жүҖжңүиө„жәҗпјҲжңҖеӨҡдёәйӣҶзҫӨзҡ„75%пјүгҖӮиҖҢзұ»дјјзҡ„пјҢprodз”ұдәҺжІЎжңүи®ҫзҪ®maximum-capacityеұһжҖ§пјҢе®ғжңүеҸҜиғҪдјҡеҚ з”ЁйӣҶзҫӨе…ЁйғЁиө„жәҗгҖӮ
Capacityе®№еҷЁйҷӨдәҶеҸҜд»Ҙй…ҚзҪ®йҳҹеҲ—еҸҠе…¶е®№йҮҸеӨ–пјҢжҲ‘们иҝҳеҸҜд»Ҙй…ҚзҪ®дёҖдёӘз”ЁжҲ·жҲ–еә”з”ЁеҸҜд»ҘеҲҶй…Қзҡ„жңҖеӨ§иө„жәҗж•°йҮҸгҖҒеҸҜд»ҘеҗҢж—¶иҝҗиЎҢеӨҡе°‘еә”з”ЁгҖҒйҳҹеҲ—зҡ„ACLи®ӨиҜҒзӯүгҖӮ
2.3 йҳҹеҲ—зҡ„и®ҫзҪ®
е…ідәҺйҳҹеҲ—зҡ„и®ҫзҪ®пјҢиҝҷеҸ–еҶідәҺжҲ‘们具дҪ“зҡ„еә”з”ЁгҖӮжҜ”еҰӮпјҢеңЁMapReduceдёӯпјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮmapreduce.job.queuenameеұһжҖ§жҢҮе®ҡиҰҒз”Ёзҡ„йҳҹеҲ—гҖӮеҰӮжһңйҳҹеҲ—дёҚеӯҳеңЁпјҢжҲ‘们еңЁжҸҗдәӨд»»еҠЎж—¶е°ұдјҡ收еҲ°й”ҷиҜҜгҖӮеҰӮжһңжҲ‘们没жңүе®ҡд№үд»»дҪ•йҳҹеҲ—пјҢжүҖжңүзҡ„еә”з”Ёе°Ҷдјҡж”ҫеңЁдёҖдёӘdefaultйҳҹеҲ—дёӯгҖӮ
жіЁж„ҸпјҡеҜ№дәҺCapacityи°ғеәҰеҷЁпјҢжҲ‘们зҡ„йҳҹеҲ—еҗҚеҝ…йЎ»жҳҜйҳҹеҲ—ж ‘дёӯзҡ„жңҖеҗҺдёҖйғЁеҲҶпјҢеҰӮжһңжҲ‘们дҪҝз”ЁйҳҹеҲ—ж ‘еҲҷдёҚдјҡиў«иҜҶеҲ«гҖӮжҜ”еҰӮпјҢеңЁдёҠйқўй…ҚзҪ®дёӯпјҢжҲ‘们дҪҝз”Ёprodе’ҢengдҪңдёәйҳҹеҲ—еҗҚжҳҜеҸҜд»Ҙзҡ„пјҢдҪҶжҳҜеҰӮжһңжҲ‘们用root.dev.engжҲ–иҖ…dev.engжҳҜж— ж•Ҳзҡ„гҖӮ
дёүгҖҒFair SchedulerпјҲе…¬е№іи°ғеәҰеҷЁпјүзҡ„й…ҚзҪ®
3.1 е…¬е№іи°ғеәҰ
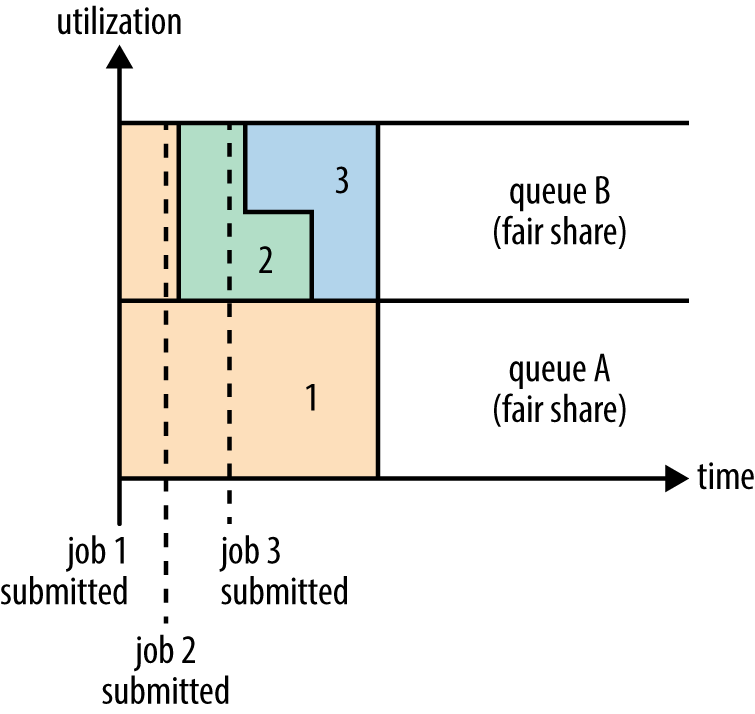
Fairи°ғеәҰеҷЁзҡ„и®ҫи®Ўзӣ®ж ҮжҳҜдёәжүҖжңүзҡ„еә”з”ЁеҲҶй…Қе…¬е№ізҡ„иө„жәҗпјҲеҜ№е…¬е№ізҡ„е®ҡд№үеҸҜд»ҘйҖҡиҝҮеҸӮж•°жқҘи®ҫзҪ®пјүгҖӮеңЁдёҠйқўзҡ„вҖңYarnи°ғеәҰеҷЁеҜ№жҜ”еӣҫвҖқеұ•зӨәдәҶдёҖдёӘйҳҹеҲ—дёӯдёӨдёӘеә”з”Ёзҡ„е…¬е№іи°ғеәҰпјӣеҪ“然пјҢе…¬е№іи°ғеәҰеңЁд№ҹеҸҜд»ҘеңЁеӨҡдёӘйҳҹеҲ—й—ҙе·ҘдҪңгҖӮдёҫдёӘдҫӢеӯҗпјҢеҒҮи®ҫжңүдёӨдёӘз”ЁжҲ·Aе’ҢBпјҢ他们еҲҶеҲ«жӢҘжңүдёҖдёӘйҳҹеҲ—гҖӮеҪ“AеҗҜеҠЁдёҖдёӘjobиҖҢBжІЎжңүд»»еҠЎж—¶пјҢAдјҡиҺ·еҫ—е…ЁйғЁйӣҶзҫӨиө„жәҗпјӣеҪ“BеҗҜеҠЁдёҖдёӘjobеҗҺпјҢAзҡ„jobдјҡ继з»ӯиҝҗиЎҢпјҢдёҚиҝҮдёҖдјҡе„ҝд№ӢеҗҺдёӨдёӘд»»еҠЎдјҡеҗ„иҮӘиҺ·еҫ—дёҖеҚҠзҡ„йӣҶзҫӨиө„жәҗгҖӮеҰӮжһңжӯӨж—¶BеҶҚеҗҜеҠЁз¬¬дәҢдёӘjob并且其е®ғjobиҝҳеңЁиҝҗиЎҢпјҢеҲҷе®ғе°Ҷдјҡе’ҢBзҡ„第дёҖдёӘjobе…ұдә«BиҝҷдёӘйҳҹеҲ—зҡ„иө„жәҗпјҢд№ҹе°ұжҳҜBзҡ„дёӨдёӘjobдјҡз”ЁдәҺеӣӣеҲҶд№ӢдёҖзҡ„йӣҶзҫӨиө„жәҗпјҢиҖҢAзҡ„jobд»Қ然用дәҺйӣҶзҫӨдёҖеҚҠзҡ„иө„жәҗпјҢз»“жһңе°ұжҳҜиө„жәҗжңҖз»ҲеңЁдёӨдёӘз”ЁжҲ·д№Ӣй—ҙе№ізӯүзҡ„е…ұдә«гҖӮиҝҮзЁӢеҰӮдёӢеӣҫжүҖзӨәпјҡ
3.2 еҗҜз”ЁFair Scheduler
и°ғеәҰеҷЁзҡ„дҪҝз”ЁжҳҜйҖҡиҝҮyarn-site.xmlй…ҚзҪ®ж–Ү件дёӯзҡ„yarn.resourcemanager.scheduler.classеҸӮж•°иҝӣиЎҢй…ҚзҪ®зҡ„пјҢй»ҳи®ӨйҮҮз”ЁCapacity Schedulerи°ғеәҰеҷЁгҖӮеҰӮжһңжҲ‘们иҰҒдҪҝз”ЁFairи°ғеәҰеҷЁпјҢйңҖиҰҒеңЁиҝҷдёӘеҸӮж•°дёҠй…ҚзҪ®FairSchedulerзұ»зҡ„е…Ёйҷҗе®ҡеҗҚпјҡ
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairSchedulerгҖӮ
3.3 йҳҹеҲ—зҡ„й…ҚзҪ®
Fairи°ғеәҰеҷЁзҡ„й…ҚзҪ®ж–Ү件дҪҚдәҺзұ»и·Ҝеҫ„дёӢзҡ„fair-scheduler.xmlж–Ү件дёӯпјҢиҝҷдёӘи·Ҝеҫ„еҸҜд»ҘйҖҡиҝҮyarn.scheduler.fair.allocation.fileеұһжҖ§иҝӣиЎҢдҝ®ж”№гҖӮиӢҘжІЎжңүиҝҷдёӘй…ҚзҪ®ж–Ү件пјҢFairи°ғеәҰеҷЁйҮҮз”Ёзҡ„еҲҶй…Қзӯ–з•ҘпјҢиҝҷдёӘзӯ–з•Ҙе’Ң3.1иҠӮд»Ӣз»Қзҡ„зұ»дјјпјҡи°ғеәҰеҷЁдјҡеңЁз”ЁжҲ·жҸҗдәӨ第дёҖдёӘеә”з”Ёж—¶дёәе…¶иҮӘеҠЁеҲӣе»әдёҖдёӘйҳҹеҲ—пјҢйҳҹеҲ—зҡ„еҗҚеӯ—е°ұжҳҜз”ЁжҲ·еҗҚпјҢжүҖжңүзҡ„еә”з”ЁйғҪдјҡиў«еҲҶй…ҚеҲ°зӣёеә”зҡ„з”ЁжҲ·йҳҹеҲ—дёӯгҖӮ
жҲ‘们еҸҜд»ҘеңЁй…ҚзҪ®ж–Ү件дёӯй…ҚзҪ®жҜҸдёҖдёӘйҳҹеҲ—пјҢ并且еҸҜд»ҘеғҸCapacity и°ғеәҰеҷЁдёҖж ·еҲҶеұӮж¬Ўй…ҚзҪ®йҳҹеҲ—гҖӮжҜ”еҰӮпјҢеҸӮиҖғcapacity-scheduler.xmlжқҘй…ҚзҪ®fair-schedulerпјҡ

йҳҹеҲ—зҡ„еұӮж¬ЎжҳҜйҖҡиҝҮеөҢеҘ—<queue>е…ғзҙ е®һзҺ°зҡ„гҖӮжүҖжңүзҡ„йҳҹеҲ—йғҪжҳҜrootйҳҹеҲ—зҡ„еӯ©еӯҗпјҢеҚідҪҝжҲ‘们没жңүй…ҚеҲ°<root>е…ғзҙ йҮҢгҖӮеңЁиҝҷдёӘй…ҚзҪ®дёӯпјҢжҲ‘们жҠҠdevйҳҹеҲ—жңүеҲҶжҲҗдәҶengе’ҢscienceдёӨдёӘйҳҹеҲ—гҖӮ
Fairи°ғеәҰеҷЁдёӯзҡ„йҳҹеҲ—жңүдёҖдёӘжқғйҮҚеұһжҖ§пјҲиҝҷдёӘжқғйҮҚе°ұжҳҜеҜ№е…¬е№ізҡ„е®ҡд№үпјүпјҢ并жҠҠиҝҷдёӘеұһжҖ§дҪңдёәе…¬е№іи°ғеәҰзҡ„дҫқжҚ®гҖӮеңЁиҝҷдёӘдҫӢеӯҗдёӯпјҢеҪ“и°ғеәҰеҷЁеҲҶй…ҚйӣҶзҫӨ40:60иө„жәҗз»ҷprodе’Ңdevж—¶дҫҝи§ҶдҪңе…¬е№іпјҢengе’ҢscienceйҳҹеҲ—жІЎжңүе®ҡд№үжқғйҮҚпјҢеҲҷдјҡиў«е№іеқҮеҲҶй…ҚгҖӮиҝҷйҮҢзҡ„жқғйҮҚ并дёҚжҳҜзҷҫеҲҶжҜ”пјҢжҲ‘们жҠҠдёҠйқўзҡ„40е’Ң60еҲҶеҲ«жӣҝжҚўжҲҗ2е’Ң3пјҢж•Ҳжһңд№ҹжҳҜдёҖж ·зҡ„гҖӮжіЁж„ҸпјҢеҜ№дәҺеңЁжІЎжңүй…ҚзҪ®ж–Ү件时жҢүз”ЁжҲ·иҮӘеҠЁеҲӣе»әзҡ„йҳҹеҲ—пјҢе®ғ们д»ҚжңүжқғйҮҚ并且жқғйҮҚеҖјдёә1гҖӮ
жҜҸдёӘйҳҹеҲ—еҶ…йғЁд»ҚеҸҜд»ҘжңүдёҚеҗҢзҡ„и°ғеәҰзӯ–з•ҘгҖӮйҳҹеҲ—зҡ„й»ҳи®Өи°ғеәҰзӯ–з•ҘеҸҜд»ҘйҖҡиҝҮйЎ¶зә§е…ғзҙ <defaultQueueSchedulingPolicy>иҝӣиЎҢй…ҚзҪ®пјҢеҰӮжһңжІЎжңүй…ҚзҪ®пјҢй»ҳи®ӨйҮҮз”Ёе…¬е№іи°ғеәҰгҖӮ
е°Ҫз®ЎжҳҜFairи°ғеәҰеҷЁпјҢе…¶д»Қж”ҜжҢҒеңЁйҳҹеҲ—зә§еҲ«иҝӣиЎҢFIFOи°ғеәҰгҖӮжҜҸдёӘйҳҹеҲ—зҡ„и°ғеәҰзӯ–з•ҘеҸҜд»Ҙиў«е…¶еҶ…йғЁзҡ„<schedulingPolicy>
е…ғзҙ иҰҶзӣ–пјҢеңЁдёҠйқўиҝҷдёӘдҫӢеӯҗдёӯпјҢprodйҳҹеҲ—е°ұиў«жҢҮе®ҡйҮҮз”ЁFIFOиҝӣиЎҢи°ғеәҰпјҢжүҖд»ҘпјҢеҜ№дәҺжҸҗдәӨеҲ°prodйҳҹеҲ—зҡ„д»»еҠЎе°ұеҸҜд»ҘжҢүз…§FIFO规еҲҷйЎәеәҸзҡ„жү§иЎҢдәҶгҖӮйңҖиҰҒжіЁж„ҸпјҢprodе’Ңdevд№Ӣй—ҙзҡ„и°ғеәҰд»Қ然жҳҜе…¬е№іи°ғеәҰпјҢеҗҢж ·engе’Ңscienceд№ҹжҳҜе…¬е№іи°ғеәҰгҖӮ
е°Ҫз®ЎдёҠйқўзҡ„й…ҚзҪ®дёӯжІЎжңүеұ•зӨәпјҢжҜҸдёӘйҳҹеҲ—д»ҚеҸҜй…ҚзҪ®жңҖеӨ§гҖҒжңҖе°Ҹиө„жәҗеҚ з”Ёж•°е’ҢжңҖеӨ§еҸҜиҝҗиЎҢзҡ„еә”з”Ёзҡ„ж•°йҮҸгҖӮ
3.4 йҳҹеҲ—зҡ„и®ҫзҪ®
Fairи°ғеәҰеҷЁйҮҮз”ЁдәҶдёҖеҘ—еҹәдәҺ规еҲҷзҡ„зі»з»ҹжқҘзЎ®е®ҡеә”з”Ёеә”иҜҘж”ҫеҲ°е“ӘдёӘйҳҹеҲ—гҖӮеңЁдёҠйқўзҡ„дҫӢеӯҗдёӯпјҢ<queuePlacementPolicy>
е…ғзҙ е®ҡд№үдәҶдёҖдёӘ规еҲҷеҲ—иЎЁпјҢе…¶дёӯзҡ„жҜҸдёӘ规еҲҷдјҡиў«йҖҗдёӘе°қиҜ•зӣҙеҲ°еҢ№й…ҚжҲҗеҠҹгҖӮдҫӢеҰӮпјҢдёҠдҫӢ第дёҖдёӘ规еҲҷspecifiedпјҢеҲҷдјҡжҠҠеә”з”Ёж”ҫеҲ°е®ғжҢҮе®ҡзҡ„йҳҹеҲ—дёӯпјҢиӢҘиҝҷдёӘеә”з”ЁжІЎжңүжҢҮе®ҡйҳҹеҲ—еҗҚжҲ–йҳҹеҲ—еҗҚдёҚеӯҳеңЁпјҢеҲҷиҜҙжҳҺдёҚеҢ№й…ҚиҝҷдёӘ规еҲҷпјҢ然еҗҺе°қиҜ•дёӢдёҖдёӘ规еҲҷгҖӮprimaryGroup规еҲҷдјҡе°қиҜ•жҠҠеә”з”Ёж”ҫеңЁд»Ҙз”ЁжҲ·жүҖеңЁзҡ„Unixз»„еҗҚе‘ҪеҗҚзҡ„йҳҹеҲ—дёӯпјҢеҰӮжһңжІЎжңүиҝҷдёӘйҳҹеҲ—пјҢдёҚеҲӣе»әйҳҹеҲ—иҪ¬иҖҢе°қиҜ•дёӢдёҖдёӘ规еҲҷгҖӮеҪ“еүҚйқўжүҖжңү规еҲҷдёҚж»Ўи¶іж—¶пјҢеҲҷи§ҰеҸ‘default规еҲҷпјҢжҠҠеә”з”Ёж”ҫеңЁdev.engйҳҹеҲ—дёӯгҖӮ
еҪ“然пјҢжҲ‘们еҸҜд»ҘдёҚй…ҚзҪ®queuePlacementPolicy规еҲҷпјҢи°ғеәҰеҷЁеҲҷй»ҳи®ӨйҮҮз”ЁеҰӮдёӢ规еҲҷпјҡ
<queuePlacementPolicy>
<rule name="specified" />
<rule name="user" />
</queuePlacementPolicy>12345
дёҠйқўи§„еҲҷеҸҜд»ҘеҪ’з»“жҲҗдёҖеҸҘиҜқпјҢйҷӨйқһйҳҹеҲ—иў«еҮҶзЎ®зҡ„е®ҡд№үпјҢеҗҰеҲҷдјҡд»Ҙз”ЁжҲ·еҗҚдёәйҳҹеҲ—еҗҚеҲӣе»әйҳҹеҲ—гҖӮ
иҝҳжңүдёҖдёӘз®ҖеҚ•зҡ„й…ҚзҪ®зӯ–з•ҘеҸҜд»ҘдҪҝеҫ—жүҖжңүзҡ„еә”з”Ёж”ҫе…ҘеҗҢдёҖдёӘйҳҹеҲ—пјҲdefaultпјүпјҢиҝҷж ·е°ұеҸҜд»Ҙи®©жүҖжңүеә”з”Ёд№Ӣй—ҙе№ізӯүе…ұдә«йӣҶзҫӨиҖҢдёҚжҳҜеңЁз”ЁжҲ·д№Ӣй—ҙгҖӮиҝҷдёӘй…ҚзҪ®зҡ„е®ҡд№үеҰӮдёӢпјҡ
<queuePlacementPolicy>
<rule name="default" />
</queuePlacementPolicy>1234
е®һзҺ°дёҠйқўеҠҹиғҪжҲ‘们иҝҳеҸҜд»ҘдёҚдҪҝз”Ёй…ҚзҪ®ж–Ү件пјҢзӣҙжҺҘи®ҫзҪ®yarn.scheduler.fair.user-as-default-queue=falseпјҢиҝҷж ·еә”з”Ёдҫҝдјҡиў«ж”ҫе…Ҙdefault йҳҹеҲ—пјҢиҖҢдёҚжҳҜеҗ„дёӘз”ЁжҲ·еҗҚйҳҹеҲ—гҖӮеҸҰеӨ–пјҢжҲ‘们иҝҳеҸҜд»Ҙи®ҫзҪ®yarn.scheduler.fair.allow-undeclared-pools=falseпјҢиҝҷж ·з”ЁжҲ·е°ұж— жі•еҲӣе»әйҳҹеҲ—дәҶгҖӮ
3.5 жҠўеҚ пјҲPreemptionпјү
еҪ“дёҖдёӘjobжҸҗдәӨеҲ°дёҖдёӘз№ҒеҝҷйӣҶзҫӨдёӯзҡ„з©әйҳҹеҲ—ж—¶пјҢjob并дёҚдјҡ马дёҠжү§иЎҢпјҢиҖҢжҳҜйҳ»еЎһзӣҙеҲ°жӯЈеңЁиҝҗиЎҢзҡ„jobйҮҠж”ҫзі»з»ҹиө„жәҗгҖӮдёәдәҶдҪҝжҸҗдәӨjobзҡ„жү§иЎҢж—¶й—ҙжӣҙе…·йў„жөӢжҖ§пјҲеҸҜд»Ҙи®ҫзҪ®зӯүеҫ…зҡ„и¶…ж—¶ж—¶й—ҙпјүпјҢFairи°ғеәҰеҷЁж”ҜжҢҒжҠўеҚ гҖӮ
жҠўеҚ е°ұжҳҜе…Ғи®ёи°ғеәҰеҷЁжқҖжҺүеҚ з”Ёи¶…иҝҮе…¶еә”еҚ д»Ҫйўқиө„жәҗйҳҹеҲ—зҡ„containersпјҢиҝҷдәӣcontainersиө„жәҗдҫҝеҸҜиў«еҲҶй…ҚеҲ°еә”иҜҘдә«жңүиҝҷдәӣд»Ҫйўқиө„жәҗзҡ„йҳҹеҲ—дёӯгҖӮйңҖиҰҒжіЁж„ҸжҠўеҚ дјҡйҷҚдҪҺйӣҶзҫӨзҡ„жү§иЎҢж•ҲзҺҮпјҢеӣ дёәиў«з»Ҳжӯўзҡ„containersйңҖиҰҒиў«йҮҚж–°жү§иЎҢгҖӮ
еҸҜд»ҘйҖҡиҝҮи®ҫзҪ®дёҖдёӘе…ЁеұҖзҡ„еҸӮж•°yarn.scheduler.fair.preemption=trueжқҘеҗҜз”ЁжҠўеҚ еҠҹиғҪгҖӮжӯӨеӨ–пјҢиҝҳжңүдёӨдёӘеҸӮж•°з”ЁжқҘжҺ§еҲ¶жҠўеҚ зҡ„иҝҮжңҹж—¶й—ҙпјҲиҝҷдёӨдёӘеҸӮж•°й»ҳи®ӨжІЎжңүй…ҚзҪ®пјҢйңҖиҰҒиҮіе°‘й…ҚзҪ®дёҖдёӘжқҘе…Ғи®ёжҠўеҚ Containerпјүпјҡ
- minimum share preemption timeout
- fair share preemption timeout123
еҰӮжһңйҳҹеҲ—еңЁminimum share preemption timeoutжҢҮе®ҡзҡ„ж—¶й—ҙеҶ…жңӘиҺ·еҫ—жңҖе°Ҹзҡ„иө„жәҗдҝқйҡңпјҢи°ғеәҰеҷЁе°ұдјҡжҠўеҚ containersгҖӮжҲ‘们еҸҜд»ҘйҖҡиҝҮй…ҚзҪ®ж–Ү件дёӯзҡ„йЎ¶зә§е…ғзҙ <defaultMinSharePreemptionTimeout>дёәжүҖжңүйҳҹеҲ—й…ҚзҪ®иҝҷдёӘи¶…ж—¶ж—¶й—ҙпјӣжҲ‘们иҝҳеҸҜд»ҘеңЁ<queue>е…ғзҙ еҶ…й…ҚзҪ®<minSharePreemptionTimeout>е…ғзҙ жқҘдёәжҹҗдёӘйҳҹеҲ—жҢҮе®ҡи¶…ж—¶ж—¶й—ҙгҖӮ
дёҺд№Ӣзұ»дјјпјҢеҰӮжһңйҳҹеҲ—еңЁfair share preemption timeoutжҢҮе®ҡж—¶й—ҙеҶ…жңӘиҺ·еҫ—е№ізӯүзҡ„иө„жәҗзҡ„дёҖеҚҠпјҲиҝҷдёӘжҜ”дҫӢеҸҜд»Ҙй…ҚзҪ®пјүпјҢи°ғеәҰеҷЁеҲҷдјҡиҝӣиЎҢжҠўеҚ containersгҖӮиҝҷдёӘи¶…ж—¶ж—¶й—ҙеҸҜд»ҘйҖҡиҝҮйЎ¶зә§е…ғзҙ <defaultFairSharePreemptionTimeout>е’Ңе…ғзҙ зә§е…ғзҙ <fairSharePreemptionTimeout>еҲҶеҲ«й…ҚзҪ®жүҖжңүйҳҹеҲ—е’ҢжҹҗдёӘйҳҹеҲ—зҡ„и¶…ж—¶ж—¶й—ҙгҖӮдёҠйқўжҸҗеҲ°зҡ„жҜ”дҫӢеҸҜд»ҘйҖҡиҝҮ<defaultFairSharePreemptionThreshold>(й…ҚзҪ®жүҖжңүйҳҹеҲ—)е’Ң<fairSharePreemptionThreshold>(й…ҚзҪ®жҹҗдёӘйҳҹеҲ—)иҝӣиЎҢй…ҚзҪ®пјҢй»ҳи®ӨжҳҜ0.5гҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңHadoop Yarnзҡ„иө„жәҗи°ғеәҰеҷЁжңүе“ӘдәӣвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





