这篇文章主要讲解了“Flume如何部署”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Flume如何部署”吧!
Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方用于收集数据,同时Flume提供对数据的简单处理,并将数据处理结果写入各种数据接收方的能力。
Flume作为Cloudera开发的实时日志收集系统,受到了业界的认可与广泛应用。2010年11月Cloudera开源了Flume的第一个可用版本0.9.2,这个系列版本被统称为Flume-OG,重构后的版本统称为Flume-NG。改动的另一原因是将 Flume 纳入 Apache 旗下,Cloudera Flume改名为Apache Flume成为Apache核心项目。
Flume(水道)以agent为最小的独立运行单位。一个agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成,如下图:
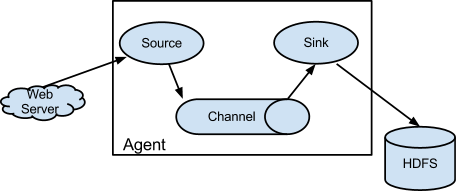
Flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。以下是Flume的一些核心概念:
| 组件 | 功能 |
|---|---|
| Agent | 使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。 |
| Client | 生产数据,运行在一个独立的线程。 |
| Source | 从Client收集数据,传递给Channel。 |
| Sink | 从Channel收集数据,运行在一个独立线程。 |
| Channel | 连接 sources 和 sinks ,这个有点像一个队列。 |
| Events | 可以是日志记录、 avro 对象等。 |
hadoop用户下
1) 下载
wgte http://archive-primary.cloudera.com/cdh6/cdh/5/flume-ng-1.6.0-cdh6.7.0.tar.gz
cdh6.7对应文档:
http://archive-primary.cloudera.com/cdh6/cdh/5/flume-ng-1.6.0-cdh6.7.0/
2) 解压到~/app,检查用户和用户组
tar -xzvf flume-ng-1.6.0-cdh6.7.0.tar.gz -C ~/app/
3) 添加到系统环境变量
vim ~/.bash_profile
export FLUME_HOME=/home/hadoop/app/apache-flume-1.6.0-cdh6.7.0-bin
export PATH=$FLUME_HOME/bin:$PATH
source ~/.bash_profile
4) 配置flume的jdk路径
$FLUME_HOME/conf/flume-env.sh
cp flume-env.sh.template flume-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_45配置flume加载的配置文件:
#从指定的网络端口上采集日志到控制台输出
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动flume:
./flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file /home/hadoop/script/flume/telnet-flume.conf \
-Dflume.root.logger=INFO,console \
-Dflume.monitoring.type=http \
-Dflume.monitoring.port=34343-Dflume.root.logger=INFO,console -- 日志级别
-Dflume.monitoring.type=http -- http输出日志
-Dflume.monitoring.port=34343 -- http 端口
未安装telnet,先安装telnet命令
[root@locahost ~]#yum install -y telnet-server
[root@locahost ~]#yum install -y telnet
由于telnet服务也是由xinetd守护的,所以安装完telnet-server,要启动telnet服务就必须重新启动xinetd
[root@locahost ~]#service xinetd restart结果测试:
[root@hadoop001 ~]# telnet localhost 44444
Trying ::1...
Connected to localhost.
Escape character is '^]'.
asd
OK
asd
OK
asd
OK
asd
OK控制台日志输出:
(LoggerSink.java:94)] Event: 数据流事件 有,由【headers】【body】构成,分别为字节数组+内容
2018-08-09 19:20:21,272 (conf-file-poller-0) [INFO - org.mortbay.log.Slf4jLog.info(Slf4jLog.java:67)] Logging to org.slf4j.impl.Log4jLoggerAdapter(org.mortbay.log) via org.mortbay.log.Slf4jLog
2018-08-09 19:20:21,338 (conf-file-poller-0) [INFO - org.mortbay.log.Slf4jLog.info(Slf4jLog.java:67)] jetty-6.1.26.cloudera.4
2018-08-09 19:20:21,391 (conf-file-poller-0) [INFO - org.mortbay.log.Slf4jLog.info(Slf4jLog.java:67)] Started SelectChannelConnector@0.0.0.0:34343
2018-08-09 19:29:15,336 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 61 73 64 0D asd. }
2018-08-09 19:29:15,337 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 61 73 64 0D asd. }
2018-08-09 19:29:15,337 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 61 73 64 0D asd. }
2018-08-09 19:29:15,338 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 61 73 64 0D asd. }
http输出:
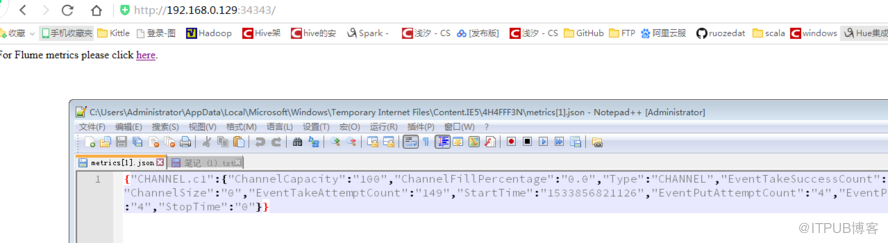
| 名称 | 含义 | 注意点 |
|---|---|---|
| avro | avro协议的数据源 | |
| exec | unix命令 | 可以命令监控文件 tail -F |
| spooldir | 监控一个文件夹 | 不能含有子文件夹,不监控windows文件夹 处理完文件不能再写数据到文件 文件名不能冲突 |
| TAILDIR | 既可以监控文件也可以监控文件夹 | 支持断点续传功能,重点使用这个 |
| netcat | 监听某个端口 | |
| kafka | 监控卡夫卡数据 |
| 名称 | 含义 | 注意点 |
|---|---|---|
| kafka | 写到kafka中 | |
| HDFS | 将数据写到HDFS中 | |
| logger | 输出到控制台 | |
| avro | avro协议 | 配合avro source使用 |
| 名称 | 含义 | 注意点 |
|---|---|---|
| memory | 存在内存中 | |
| kafka | 将数据存到kafka中 | |
| file | 存在本地磁盘文件中 |
感谢各位的阅读,以上就是“Flume如何部署”的内容了,经过本文的学习后,相信大家对Flume如何部署这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/31441024/viewspace-2199588/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



