本篇博客讲的是MySQL的索引的功能和使用 , 以及存储引擎的基本简介
一. mysql索引
索引的简介和作用
索引在MySQL中叫做"键" , 是存储引擎用于快速找到记录的一种数据结构 . 索引对良好的性能非常关键 , 尤其是当表中的数据量越来越大时 , 索引对于性能的影响愈来愈发重要 .
作用 : 通过一定的算法将数据库中的记录按一定的规律进行分组 , 这样查信息时可以缩小数据的搜索范围 , 从而提高溜了查询效率
用生活实例来说 , 索引就好像书的目录 , 清单上的列表 ; 好比人去吃火锅 , 当菜单拿到客户手上 , 客户可以根据菜单上的分类(海鲜 , 蔬菜类 , 肉类 , 饮料类等) , 根据自己的口味能第一时间找到自己想吃的菜 .
索引的分类
索引可分为 : 普通索引 , 唯一索引 , 全文索引 , 单列索引 , 多列索引 , 空间索引
语法格式:
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[索引名] (字段名[(长度)] [ASC |DESC])
);
示例 :
创建一个INDEX普通索引
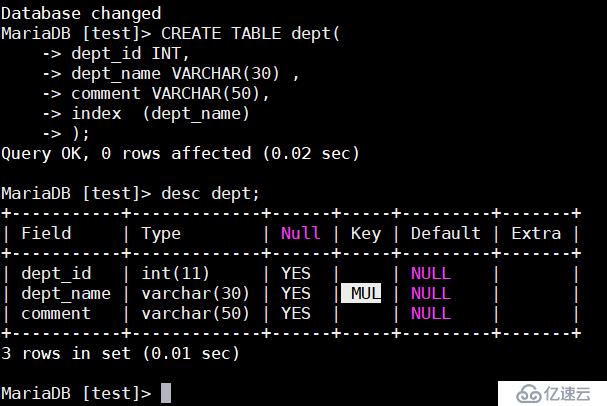
CREATE TABLE dept(
dept_id INT,
dept_name VARCHAR(30) ,
comment VARCHAR(50),
index (dept_name) # 将表中的dept_name字段指定为普通索引字段
);
创建一个UNIQUE唯一索引:
CREATE TABLE dept2 (
dept_id INT,
dept_name VARCHAR(30) ,
comment VARCHAR(50),
UNIQUE INDEX (dept_name)
);
相比普通索引来说 , 比上面的索引选项多了一个unique选项
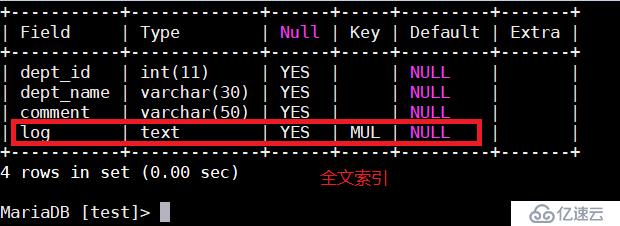
创建一个全文索引;
CREATE TABLE dept3 (
dept_id INT,
dept_name VARCHAR(30) ,
comment VARCHAR(50),
log text,
FULLTEXT INDEX (log)
)engine=myisam;
注: 只有MYISAM存储引擎支持全文索引,innodb存储引擎不支持全文索引
创建多列索引
CREATE TABLE dept13 (
dept_id INT,
dept_name VARCHAR(30) ,
comment VARCHAR(50),
INDEX (dept_name, comment)
);
相比普通索引来说 , 就是将多个字段设置为索引
对已存在的表创建索引
语法一:
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 ON 表名 (字段名[(长度)] [ASC |DESC]) ;
创建普通索引示例:此方法要指定索引名称
CREATE INDEX index_dept_name ON dept6 (dept_name);
创建唯一索引示例:
CREATE UNIQUE INDEX index_dept_name ON dept6 (dept_name);
创建全文索引示例:
CREATE FULLTEXT INDEX index_dept_name ON dept6 (dept_name);
创建多列索引示例:
CREATE INDEX index_dept_name_ comment ON dept6 (dept_name, comment);
语法二:
ALTER TABLE在已存在的表上创建索引:
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名 (字段名[(长度)] [ASC |DESC]) ;
管理索引:
查看索引: show create table 表名\G
测试索引: explain select * from 表名 where 字段名='xx';
删除索引: drop index 索引名 on 表名
索引检测实例:
要求 : 创建一个school的数据库 , 创建一张t2表 , 用存储过程脚本t2表插入1000W条数据 , 然后查询t2数据看看花费了多长时间 ; 再为t2创建一个索引 , 再次查看数据看看所花费的时间
准备:
create database school #创建school数据库
create table school.t2(id int,name varchar(30)); #创建一张t2表 , 里面记录id号和名字
定义一个插入1000W条数据的存储过程 , 并调用此存储过程
mysql> delimiter $$ //设置命令的界定符(也称为结束符)
mysql> create procedure autoinsert1() //创建autoinsert1这个存储过程(类似于shell脚本)
-> BEGIN
-> declare i int default 1;
-> while(i<100000)do
-> insert into school.t2 values(i,'ccc');
-> set i=i+1;
-> end while;
-> END$$
mysql> delimiter ;
call atuoinsert1();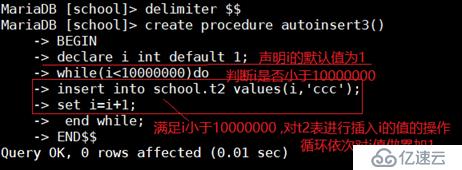
分两次查询数据 , 对比所花的时间(实验中途插入1000W条数据花了33分钟 , 插100W估计就能看出效果了):
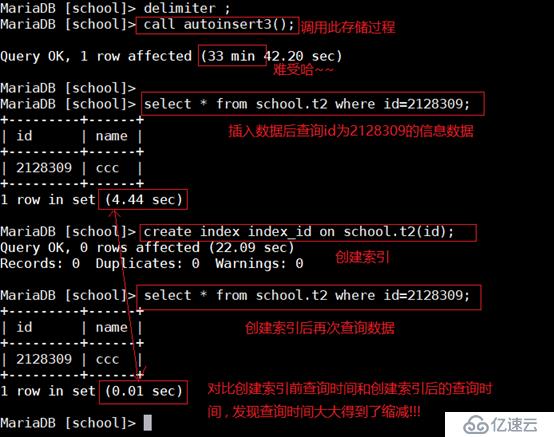
从上述实验可以看到 , 在一个存放1000W的表中 , 查询一条数据跟创建索引后查询一条数据相差了4S的时间 , 随着数据更大 , 查询时间也会不断增大 , 所以足以证明 , 创建索引会大大提高MySQL的查询工作效率!!!
二. MySQL存储引擎介绍
了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和操作此表的类型)
在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的。而MySql数据库提供了多种存储引擎。用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎。
1. 查看存储引擎
SHOW ENGINES;
SHOW ENGINES\G 查看MYSQL支持的存储引擎
SHOW VARIABLES LIKE 'storage_engine%'; 查看当前的存储引擎
SHOW VARIABLES LIKE 'auto_inc%'; 查看自增长的设置状态
show global variables like '%connet%' 查看connet环境变量设置
mysql> show variables\G 查看所有的环境变量
show variables当前的会话
show global variables\G全局
2. 选择存储引擎
方法1.
mysql> create table innodb1(
-> id int
-> )engine=innodb;
mysql> show create table innodb1;
create tables test100(id init)engine=inodb;
方法2.
/etc/my.cnf
[mysqld] 在此行下添加下面的一行内容
default-storage-engine=INNODB
MySQL常用的存储引擎
MyISAM存储引擎
由于该存储引擎不支持事务、也不支持外键,所以访问速度较快。因此当对事务完整性没有要求并以访问为主的应用适合使用该存储引擎。
InnoDB存储引擎(MYSQL默认用此存储引擎)
由于该存储引擎在事务上具有优势,即支持具有提交、回滚及崩溃恢复能力等事务特性,所以比MyISAM存储引擎占用更多的磁盘空间。
因此当需要频繁的更新、删除操作,同时还对事务的完整性要求较高,需要实现并发控制,建议选择。
MEMORY
MEMORY存储引擎存储数据的位置是内存,因此访问速度最快,但是安全上没有保障。适合于需要快速的访问或临时表。
BLACKHOLE
黑洞存储引擎,可以应用于主备复制中的分发主库。
使用BLACKHOLE存储引擎的表不存储任何数据,但如果mysql启用了二进制日志,SQL语句被写入日志(并被复制到从服务器)。这样使用BLACKHOLE存储引擎的mysqld可以作为主从复制中的中继重复器或在其上面添加过滤器机制。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



