MySQLзҡ„й«ҳзә§йғЁеҲҶ
1. MySQLзҡ„дәӢеҠЎ
пјҲ1пјүеӯҳеӮЁеј•ж“Һзҡ„д»Ӣз»Қ
д»Ӣз»ҚпјҡеҪ“е®ўжҲ·з«ҜеҸ‘йҖҒдёҖжқЎSQLиҜӯеҸҘз»ҷжңҚеҠЎеҷЁж—¶пјҢжңҚеҠЎеҷЁз«ҜйҖҡиҝҮзј“еӯҳгҖҒиҜӯжі•жЈҖжҹҘгҖҒж ЎйӘҢйҖҡиҝҮд№ӢеҗҺпјҢ然еҗҺдјҡйҖҡиҝҮи°ғз”Ёеә•еұӮзҡ„дёҖдәӣиҪҜ件组з»ҮпјҢеҺ»д»Һж•°жҚ®еә“дёӯжҹҘиҜўж•°жҚ®пјҢ然еҗҺе°ҶжҹҘиҜўеҲ°зҡ„з»“жһңйӣҶиҝ”еӣһз»ҷе®ўжҲ·з«ҜпјҢиҖҢиҝҷдәӣеә•еұӮзҡ„иҪҜ件组з»Үе°ұжҳҜеӯҳеӮЁеј•ж“ҺгҖӮ
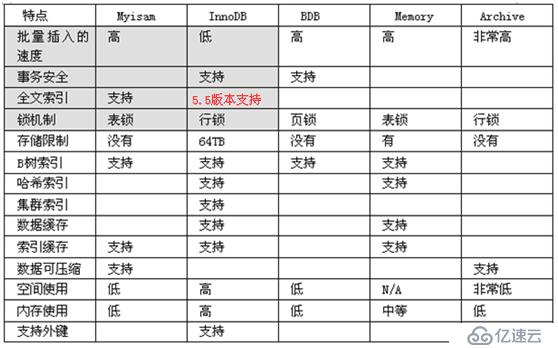
MySQLзҡ„еӯҳеӮЁеј•ж“Һпјҡ
- MySQLзҡ„ж ёеҝғе°ұжҳҜеӯҳеӮЁеј•ж“ҺпјҢMySQLеҸҜд»Ҙи®ҫзҪ®еӨҡз§ҚдёҚеҗҢзҡ„еӯҳеӮЁеј•ж“ҺпјҢдёҚеҗҢзҡ„еӯҳеӮЁеј•ж“ҺеңЁзҙўеј•гҖҒеӯҳеӮЁгҖҒд»ҘеҸҠй”Ғзҡ„зӯ–з•ҘдёҠжҳҜдёҚеҗҢзҡ„гҖӮ
- Mysql5.5д№ӢеүҚпјҢдҪҝз”Ёзҡ„жҳҜmyisamеӯҳеӮЁеј•ж“ҺпјҢж”ҜжҢҒе…Ёж–ҮжҗңзҙўпјҢдёҚж”ҜжҢҒдәӢеҠЎгҖӮ
- Mysql5.5д»ҘеҗҺпјҢдҪҝз”Ёзҡ„жҳҜinnodbеӯҳеӮЁеј•ж“ҺпјҢж”ҜжҢҒдәӢеҠЎд»ҘеҸҠиЎҢзә§й”Ғ
пјҲ2пјүMySQLдәӢеҠЎзҡ„д»Ӣз»Қ
д»Ӣз»ҚпјҡдәӢеҠЎжҳҜдёҖдёӘж“ҚдҪңеәҸеҲ—пјҢиҝҷдәӣж“ҚдҪңиҰҒд№ҲйғҪеҒҡпјҢиҰҒд№ҲйғҪдёҚеҒҡпјҢжҳҜдёҖдёӘдёҚиғҪеҲҶеүІзҡ„е·ҘдҪңеҚ•дҪҚгҖӮеңЁдёӨжқЎжҲ–дёӨжқЎд»ҘдёҠзҡ„SQLиҜӯеҸҘжүҚиғҪе®ҢжҲҗзҡ„дёҡеҠЎж—¶пјҢжүҚйңҖиҰҒз”ЁдәӢеҠЎпјҢеӣ дёәдәӢеҠЎж—¶еҗҢжӯҘеҺҹеҲҷпјҢж•ҲзҺҮжҜ”иҫғдҪҺгҖӮ
дәӢеҠЎзҡ„ACIDзү№жҖ§пјҡ
- еҺҹеӯҗжҖ§пјҡж”ҫеңЁеҗҢдёҖдәӢеҠЎзҡ„дёҖз»„ж“ҚдҪңж—¶дёҚеҸҜеҲҶеүІзҡ„
- дёҖиҮҙжҖ§пјҡеңЁдәӢеҠЎзҡ„жү§иЎҢеүҚеҗҺпјҢж•ҙдҪ“зҡ„зҠ¶жҖҒжҳҜдёҚеҸҳзҡ„
- йҡ”зҰ»жҖ§пјҡдәӢеҠЎд№Ӣй—ҙжҳҜзӢ¬з«ӢеӯҳеңЁзҡ„пјҢдёӨдёӘдёҚеҗҢдәӢеҠЎд№Ӣй—ҙдә’дёҚеҪұе“Қ
- жҢҒд№…жҖ§пјҡдәӢеҠЎжү§иЎҢд№ӢеҗҺпјҢе°Ҷдјҡж°ёд№…зҡ„еҪұе“ҚеҲ°ж•°жҚ®еә“гҖӮ
#дҫӢпјҡдёҖдёӘдәӢеҠЎж“ҚдҪң
BEGIN;
update t_account set money=money+100 where id =1;
update t_account set money=money-100 where id =2;
COMMIT;
#дёҖдёӘеӣһж»ҡж“ҚдҪң
BEGIN;
update t_account set money=money+100 where id =1;
update t_account set money=money-100 where id =2;
COMMIT;
жіЁж„ҸпјҡMySQLж•°жҚ®еә“пјҢdmlж“ҚдҪңйҮҮз”Ёзҡ„жҳҜиҮӘеҠЁжҸҗдәӨ
#жҹҘзңӢиҮӘеҠЁжҸҗдәӨ
show variables like 'autocommit';
#дҝ®ж”№иҮӘеҠЁжҸҗдәӨ
set autocommit=0;
пјҲ3пјүMySQLдәӢеҠЎе№¶еҸ‘ж—¶дә§з”ҹзҡ„й—®йўҳ
и„ҸиҜ»пјҡеңЁдёҖдёӘдәӢеҠЎзҡ„жү§иЎҢиҢғеӣҙеҶ…пјҢиҜ»еҲ°дәҶеҸҰдёҖдәӢеҠЎжңӘжҸҗдәӨзҡ„ж•°жҚ®гҖӮ
и§ЈеҶіпјҡиҜ»е·ІжҸҗдәӨпјҢдёҖдёӘж•°жҚ®еә“еҸӘиғҪиҜ»еҲ°еҸҰдёҖдёӘдәӢеҠЎжҸҗдәӨеҗҺзҡ„ж•°жҚ®гҖӮпјҲOracleй»ҳи®Өзҡ„дәӢеҠЎйҡ”зҰ»зә§еҲ«пјү
дёҚеҸҜйҮҚеӨҚиҜ»пјҡдёҖдёӘдәӢеҠЎпјҢеңЁеҸӘиҜ»иҢғеӣҙеҶ…пјҢиў«еҸҰдёҖдәӢеҠЎдҝ®ж”№е№¶жҸҗдәӨдәӢеҠЎпјҢеҜјиҮҙеӨҡж¬ЎиҜ»еҸ–зҡ„ж•°жҚ®дёҚдёҖиҮҙзҡ„й—®йўҳгҖӮ
и§ЈеҶіпјҡеҸҜйҮҚеӨҚиҜ»пјҲMySQLй»ҳи®Өзҡ„дәӢеҠЎйҡ”зҰ»зә§еҲ«пјү
иҷҡиҜ»пјҡдёҖдёӘдәӢеҠЎзҡ„еҸӘиҜ»иҢғеӣҙеҶ…пјҢиў«еҸҰдёҖдёӘдәӢеҠЎеҲ йҷӨжҲ–иҖ…ж·»еҠ ж•°жҚ®пјҢеҜјиҮҙеӨҡж¬ЎиҜ»еҸ–зҡ„ж•°жҚ®дёҚдёҖиҮҙзҡ„й—®йўҳгҖӮ
и§ЈеҶіпјҡдёІиЎҢеҢ–пјҡи§ЈеҶіжүҖжңүй—®йўҳпјҢдҪҶжҳҜйҖҹеәҰеҚҒеҲҶзј“ж…ўпјҢдёҚиғҪдҪҝ用并еҸ‘дәӢеҠЎгҖӮ
жіЁж„ҸпјҡжҹҘзңӢдәӢеҠЎзҡ„йҡ”зҰ»зә§еҲ«пјҡselect @@tx_isolation;
2. MySQLзҡ„еӯҳеӮЁзЁӢеәҸ
пјҲ1пјүMySQLзҡ„еӯҳеӮЁзЁӢеәҸзҡ„д»Ӣз»Қ
жҸҸиҝ°пјҡиҝҗиЎҢдёҺжңҚеҠЎеҷЁз«Ҝзҡ„зЁӢеәҸгҖӮ
дјҳзӮ№пјҡз®ҖеҢ–ејҖеҸ‘пјҢжү§иЎҢж•ҲзҺҮжҜ”иҫғй«ҳпјҲеңЁжңҚеҠЎеҷЁз«Ҝд»ҘйҖҡиҝҮж ЎйӘҢпјҢеҸҜзӣҙжҺҘдҪҝз”Ёпјү
зјәзӮ№пјҡжңҚеҠЎеҷЁз«ҜдҝқеӯҳиҝҷдәӣеӯҳеӮЁзЁӢеәҸйңҖиҰҒеҚ з”ЁзЈҒзӣҳз©әй—ҙпјӣж•°жҚ®иҝҒ移时пјҢйңҖиҰҒе°ҶиҝҷдәӣеӯҳеӮЁзЁӢеәҸиҝӣиЎҢиҝҒ移пјӣи°ғиҜ•е’Ңзј–еҶҷзЁӢеәҸеңЁжңҚеҠЎеҷЁз«ҜйғҪдёҚж–№дҫҝ
еӯҳеӮЁзЁӢеәҸзҡ„еҲҶзұ»пјҡеӯҳеӮЁиҝҮзЁӢгҖҒеӯҳеӮЁеҮҪж•°гҖҒи§ҰеҸ‘еҷЁ
жіЁж„ҸпјҡеӯҳеӮЁзЁӢеәҸдёҚиғҪдҪҝз”ЁдәӢеҠЎ
пјҲ2пјүеӯҳеӮЁиҝҮзЁӢ
д»Ӣз»ҚпјҡеӯҳеӮЁиҝҮзЁӢжҳҜеңЁжңҚеҠЎеҷЁз«Ҝзҡ„дёҖж®өеҸҜжү§иЎҢзҡ„д»Јз Ғеқ—гҖӮ
дҫӢпјҡ
#дҝ®ж”№з»“жқҹз¬Ұж Үеҝ—
delimiter //
#еҲӣе»әеӯҳеӮЁиҝҮзЁӢ
create procedure pro_book()
begin
#sql
select * from book;
select * from book where bid=3;
end //
#иҝҗиЎҢ
call pro_book()
#еҸӮж•°зҡ„дј е…Ҙ
delimiter //
create procedure pro_book02(num int)
begin
select * from book where bid=num;
end ; //
--и°ғз”Ё
call pro_book02(3)
#дј еҮәеҸӮж•°
delimiter //
create procedure pro_book03(num int,out v_name varchar(10))
begin
select bname into v_name from book where bid=num;
end ; //
--и°ғз”Ё,иҝҷйҮҢзҡ„@v_nameжҳҜдёҖдёӘз”ЁжҲ·еҸҳйҮҸ
call pro_book03(1,@v_name);
select @v_name;
#дј е…Ҙдј еҮәеҸӮж•°
delimiter //
create procedure pro_book04(num int)
begin
select bid into num from book where bid=num;
end ; //
--и°ғз”Ё
set @v_id=3; --з»ҷз”ЁжҲ·еҸҳйҮҸиөӢеҖј
call pro_book04(@v_id);
select @v_id;
жҺ§еҲ¶жөҒзЁӢиҜӯеҸҘ
#ifиҜӯеҸҘ
delimiter //
create procedure if_test(score int)
begin
-- е®ҡд№үеұҖйғЁеҸҳйҮҸ
declare myLevel varchar(20);
if score>80 then
set myLevel='A';
elseif score >60 then
set myLevel='B';
else
set myLevel='C';
end if;
select myLevel;
end; //
-- и°ғз”Ё
call if_test(70);
#whileеҫӘзҺҜ
delimiter //
create procedure while_test()
begin
declare i int ;
declare sum int ;
set i=1;
set sum =0;
while i<=100 do
set sum=sum+i;
set i=i+1;
end while ;
select sum;
end ;//
call while_test()
#loopеҫӘзҺҜ
delimiter //
create procedure loop_test()
begin
declare i int ;
declare sum int ;
set i=1;
set sum =0;
-- иө·еҲ«еҗҚ
lip:loop
if i>100 then
-- зҰ»ејҖloopеҫӘзҺҜ
leave lip ;
end if ;
set sum=sum+i;
set i=i+1;
end loop ;
select sum;
end ;//
call loop_test()
#repeatеҫӘзҺҜ
delimiter //
create procedure repeat_test()
begin
declare i int ;
declare sum int ;
set i=1;
set sum =0;
repeat
set sum=sum+i;
set i=i+1;
-- дёҚиҰҒеҠ еҲҶеҸ·
until i>100
end repeat ;
select sum;
end ;//
call loop_test()
пјҲ3пјүеӯҳеӮЁеҮҪж•°
еӯҳеӮЁеңЁжңҚеҠЎеҷЁз«ҜпјҢжңүиҝ”еӣһеҖјпјҢеҮҪж•°еҸҜд»ҘдҪңдёәSQLзҡ„дёҖйғЁеҲҶиҝӣиЎҢи°ғз”ЁгҖӮ
**дҫӢ**пјҡ
delimiter //
create function func_01(num int)
-- иҝ”еӣһеҖјзұ»еһӢ
returns varchar(20)
deterministic
begin
declare v_name varchar(20);
select bname into v_name from book where bid =num ;
return v_name;
end ; //
set @v_name=func_01(3);
select @v_name;
-- дҪңдёәSQLзҡ„дёҖйғЁеҲҶи°ғз”Ё
select * from book where bname=func_01(3);
еҮҪж•°е’ҢеӯҳеӮЁиҝҮзЁӢзҡ„еҢәеҲ«пјҡ
- еӯҳеӮЁиҝҮзЁӢжңүдёүз§ҚеҸӮж•°жЁЎејҸпјҲinгҖҒoutгҖҒinoutпјүе®һзҺ°ж•°жҚ®зҡ„иҫ“е…Ҙиҫ“еҮәпјҢиҖҢеҮҪж•°жҳҜйҖҡиҝҮиҝ”еӣһеҖјиҝӣиЎҢж•°жҚ®дј йҖ’гҖӮ
- е…ій”®еӯ—дёҚеҗҢ
- еӯҳеӮЁиҝҮзЁӢеҸҜд»ҘдҪңдёәзӢ¬з«ӢдёӘдҪ“жү§иЎҢпјҢеҮҪж•°еҸӘиғҪдҪңдёәSQLзҡ„дёҖйғЁеҲҶжү§иЎҢгҖӮ
пјҲ4пјүи§ҰеҸ‘еҷЁ
и§ҰеҸ‘еҷЁпјҢеӯҳеӮЁеңЁжңҚеҠЎеҷЁз«ҜпјҢз”ұдәӢ件и°ғз”ЁпјҢдёҚиғҪдј еҸӮгҖӮ
дәӢ件зұ»еһӢпјҡеўһгҖҒеҲ гҖҒж”№
иҜӯжі•пјҡ
create trigger и§ҰеҸ‘еҷЁеҗҚ
и§ҰеҸ‘ж—¶жңәпјҲafter|beforeпјү event(update|delete|insert)
on йңҖиҰҒи®ҫзҪ®и§ҰеҸ‘еҷЁзҡ„иЎЁеҗҚ for each row (и®ҫзҪ®дёәиЎҢзә§и§ҰеҸ‘еҷЁ)
begin
дёҖз»„sql
end;
дҫӢпјҡ
delimiter //;
-- еҲӣе»әдёҖдёӘи§ҰеҸ‘еҷЁ
create trigger tri_test
after delete
-- и®ҫзҪ®дёәиЎҢзә§еҲ«зҡ„и§ҰеҸ‘еҷЁ
on book for each row
begin
insert into book values(old.id,'жӮІжғЁж•°жҚ®','zzy');
end;//
жіЁж„ҸпјҡеңЁи§ҰеҸ‘еҷЁдёӯжңүдёӨдёӘеҜ№иұЎпјҡoldгҖҒnewпјҢoldиЎЁзӨәеҲ йҷӨж•°жҚ®ж—¶йӮЈжқЎеҺҹж•°жҚ®и®°еҪ•пјҢ
newиЎЁзӨәдҝ®ж”№е’ҢжҸ’е…Ҙж•°жҚ®ж—¶пјҢйӮЈжқЎж–°ж•°жҚ®и®°еҪ•гҖӮ
3. MySQLзҡ„иЎЁзҡ„и®ҫи®Ў
пјҲ1пјүж•°жҚ®еә“зҡ„дёүеӨ§иҢғејҸпјҡ
- 1NFпјҡжүҖжңүеӯ—ж®өйғҪжҳҜеҺҹеӯҗжҖ§зҡ„пјҢдёҚеҸҜеҲҶеүІзҡ„гҖӮ
- 2NFпјҡйқһдё»й”®еӯ—ж®өеҝ…йЎ»дёҺдё»й”®зӣёе…іпјҲжҜҸдёҖеј иЎЁеҸӘжҸҸиҝ°дёҖзұ»дәӢзү©пјүпјҢиҖҢдёҚиғҪдёҺдё»й”®йғЁеҲҶзӣёе…іпјҲеңЁиҒ”еҗҲдё»й”®ж—¶жңүж•Ҳпјү
- 3NFпјҡйқһдё»й”®еӯ—ж®өеҝ…йЎ»дёҺдё»й”®зӣёе…іпјҲжҜҸдёҖеј иЎЁеҸӘжҸҸиҝ°дёҖзұ»дәӢзү©пјүпјҢиҖҢдёҚиғҪдёҺдё»й”®йғЁеҲҶзӣёе…іпјҲеңЁиҒ”еҗҲдё»й”®ж—¶жңүж•Ҳпјү
пјҲ2пјүиЎЁзҡ„е…ізі»пјҡ
дёҖдёҖеҜ№еә”
#д»Ҙдәәе’ҢГ—Г—Г—дёәдҫӢ
дәәиЎЁпјҡ
CREATE TABLE `t_people` (
`id` int(11) NOT NULL,
`name` varchar(50) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
)
Г—Г—Г—иЎЁпјҡ
create table t_idcard(
card_number varchar(18) primary key,
create_date date,
p_id int unique,
foreign key (p_id) REFERENCES t_people(id)
)
жіЁж„Ҹпјҡи®ҫи®Ўж–№жі•пјҡжғіеҠһжі•и®©еӨ–й”®еӯ—ж®өеҗҢж—¶жӢҘжңүе”ҜдёҖзәҰжқҹпјҢеӨ–й”®еӯ—ж®өеңЁд»»ж„Ҹзҡ„иЎЁдёӯйғҪеҸҜд»Ҙ
дёҖеҜ№еӨҡпјҡ
д»ҘйғЁй—Ёе’Ңе‘ҳе·ҘиЎЁдёәдҫӢпјҡ
create table t_emp(
eid int PRIMARY KEY,
ename varchar(50) not null,
job varchar(50),
deptno int ,
foreign key (deptno) REFERENCES t_dept(deptno)
)
йғЁй—ЁиЎЁпјҡ
create table t_dept(
deptno int primary key,
deptname varchar(50)
)
жіЁж„Ҹпјҡи®ҫи®Ўж–№жі•пјҡеҸӘйңҖиҰҒеңЁеӨҡзҡ„йӮЈдёӘиЎЁдёӯеўһеҠ дёҖдёӘеӨ–й”®зәҰжқҹ
еӨҡеҜ№еӨҡпјҡ
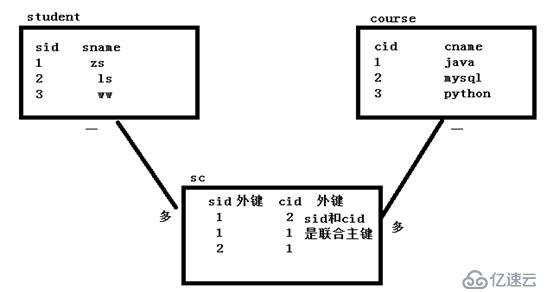
и®ҫи®Ўж–№жі•пјҡйңҖиҰҒжүҫдёҖеј дёӯй—ҙиЎЁпјҢиҪ¬еҢ–жҲҗдёӨдёӘдёҖеҜ№еӨҡзҡ„е…ізі»
пјҲ3пјүж•°жҚ®еә“зҡ„дјҳеҢ–пјҡ
- SQLзҡ„дјҳеҢ–
- еңЁжҹҘиҜўж—¶дёҖиҲ¬дёҚдҪҝз”Ё *пјҢеӣ дёәеңЁжҹҘиҜўи®°еҪ•ж—¶пјҢдёҖиҲ¬дҪҝз”Ё(*),д»–дјҡе°Ҷ*иҪ¬жҚўдёәеҲ—еҗҚпјҢ然еҗҺеңЁжҹҘиҜўпјҲиҖ—ж—¶пјү
- дҪҝз”Ё not null /null еҜ№зҙўеј•иҝӣиЎҢжҗңзҙўпјҢдјҡеҜјиҮҙзҙўеј•еӨұж•Ҳ
- зҙўеј•еҲ—дёӯдҪҝз”ЁеҮҪж•°пјҢд№ҹдјҡеҜјиҮҙзҙўеј•еӨұж•Ҳ
- зҙўеј•еҲ—дёӯиҝӣиЎҢи®Ўз®—пјҢд№ҹдјҡеҜјиҮҙзҙўеј•еӨұж•Ҳ
- зҙўеј•еҲ—дёҚиҰҒдҪҝз”Ёnot|пјҒ=|<>
- е°ҪйҮҸдёҚиҰҒдҪҝз”Ёor,дҪҝз”Ёunion
- зҙўеј•еҲ—дёӯдҪҝз”ЁlikeпјҢд№ҹдјҡеҜјиҮҙзҙўеј•еӨұж•Ҳ
- exists е’Ң inзҡ„дҪҝз”ЁйҖүжӢ©
- existsе…Ҳжү§иЎҢдё»жҹҘиҜўпјҡеҰӮжһңдё»жҹҘиҜўиҝҮж»Өзҡ„жҜ”иҫғеӨҡпјҢеҲҷдҪҝз”Ёexists
- inе…Ҳжү§иЎҢеӯҗжҹҘиҜўпјҡеҰӮжһңжҳҜеӯҗжҹҘиҜўзҡ„иҝҮж»ӨжҜ”иҫғеӨҡпјҢеҲҷдҪҝз”ЁinгҖӮ





