这篇文章给大家介绍vertica如何实现存储,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
JAVA 等通用语言缺乏结构化计算类库,即使最简单的结构化算法,比如查询、排序、聚合,也要从零开始硬编码。对于很常用的算法,比如分组汇总、关联查询,则要编写大篇幅的代码。对于复杂些的算法,甚至要设计多个类才能勉强实现。
只要多花时间,JAVA 总是可以实现算法的,但高耦合性的缺点却无法避免。存储过程本应独立于 JAVA 代码,修改存储过程本不该影响 JAVA 代码。但 JAVA 开发的存储过程会和其他 JAVA 代码紧密耦合,只要修改存储过程,就必然重新编译打包整个项目,项目的维护成本必然升高。
如果使用集算器,实现 vertica 存储过程就会容易很多。
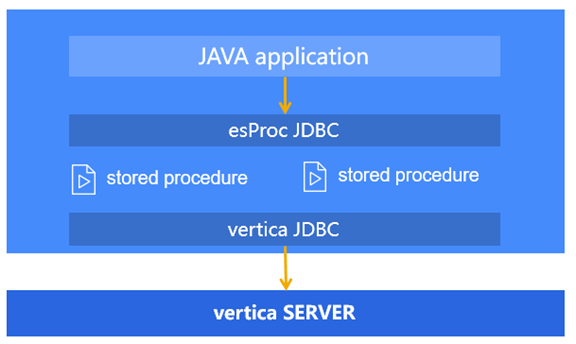
集算器具有丰富的结构化类库,无论查询、排序、聚合还是分组汇总、关联查询,都可以用内置函数直接实现。集算器也提供了针对结构化数据的分支判断、循环语句、动态语法,复杂业务逻辑也可轻松实现。集算器还提供了标准的 JDBC 接口,供 JAVA 代码调用,实际的存储过程则以脚本文件的形式存在,修改存储过程不影响 JAVA 代码。
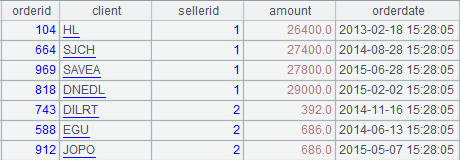
例如:vertica 中 sales 表存储销售员的订单信。
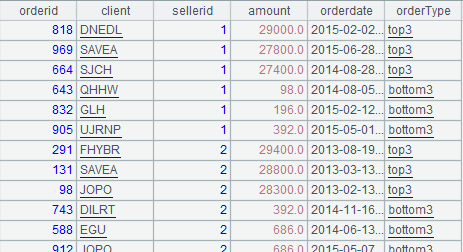
逻辑算法:对每一位销售,找到他金额最大和最小的 3 笔订单,分别打上 "top3" 和 "bottom3" 的标记,考虑到订单数太少没意义,特规定某销售的订单数小于 3 时,则不计算 top3,订单数小于 6 时,则不计算 bottom3。计算结果应当如下:
集算器代码如下:
| A | B | C | D | |
| 1 | =connect@l("verticaDB") | |||
| 2 | =A1.cursor@x("select * from sales order by sellerid,amount") | |||
| 3 | for A2;sellerid | /for each seller | ||
| 4 | if A3.len()>=3 | =A3.m(to(-1,-3)) | =C4.derive("top3":orderType) | |
| 5 | if A3.len()>=6 | =A3.m(to(3)) | =C5.derive("bottom3":orderType) | |
| 6 | =@|D4|D5 | /merge top+bottom for every seller | ||
| 7 | return B6 | |||
关于vertica如何实现存储就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





