本篇文章给大家主要讲的是关于如何实现Percona Mysql Galera多读写集群的部署的内容,感兴趣的话就一起来看看这篇文章吧,相信看完如何实现Percona Mysql Galera多读写集群的部署对大家多少有点参考价值吧。
一、部署MySQL:
yum install https://www.percona.com/redir/downloads/percona-release/redhat/latest/percona-release-0.1-6.noarch.rpm -y 安装percona的仓库文件。
yum install Percona-XtraDB-Cluster-57 percona-toolkit -y 安装数据库
修改配置文件:/etc/my.cnf
[mysqld]
datadir = /storage/DBdata #数据库存放的目录
pid-file = /usr/local/mysql/mysqld.pid
port = 3306
socket = /var/lib/mysql/mysql.sock
user = mysql
#####修改事务隔离级别####
transaction-isolation = READ-COMMITTED
default_storage_engine = InnoDB
default-time_zone = '+8:00' #修改mysql日志中的时区。
log_timestamps=SYSTEM
#InnoDB
innodb_file_per_table = 1
innodb_flush_method = O_DIRECT
#name-resolve
skip-host-cache
explicit_defaults_for_timestamp = true
#character-set
character-set-server = utf8
collation-server = utf8_general_ci
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
max_connections = 5000 #允许的最大连接数
#fix up table open cache too small
table_open_cache = 1024
open_files_limit = 65535
ignore-db-dir=lost+found
#LOG
log-error=/var/log/mysqld.log
general_log_file=/var/log/mysql-general.log #调试时开启下面的general_log=ON,正常运行后需要关闭
general_log=OFF
slow_query_log=ON
long_query_time = 5
slow_query_log_file = /var/log/mysql-slow.log
log_queries_not_using_indexes=false
server-id = 1 #集群中每个主机的ID需要不一样。
log-bin = /usr/local/mysql/binlogs/mysql-bin #binlog的日志,最好和数据库目录放在不同的物理磁盘中。日志作用是用来做数据同步的。
expire_logs_days = 10 #保存的时间,如果其它节点宕机10天以后启动加入集群将会做数据的完全同步。如果在宕机后的第九天加入集群将会接着关机时的状态进行数据同步。
skip-name-resolve
relay-log = mysqld-relay-bin
innodb_support_xa = 1
relay_log_purge = 0
innodb_print_all_deadlocks = on
sync_binlog=2
#slave-skip-errors = all
#优化配置
join_buffer_size = 2M
sort_buffer_size = 2M
key_buffer_size=512M
read_rnd_buffer_size=2M
query_cache_type=1
query_cache_size=6M
tmp_table_size = 512M
innodb_thread_concurrency=64
innodb_buffer_pool_size=10G
max_binlog_size = 1G
max_relay_log_size = 1G
innodb_lock_wait_timeout=120
#innodb_data_file_path = ibdata1:1G:autoextend
#审计日志配置 审计的配置第一次需要注释掉,启动完以后进入到mysql里面命令安装插件等操作
#audit_log_file='/var/log/mysql-audit.json'
#audit_log_format=JSON
#audit_log_policy=QUERIES
#audit_log_rotate_on_size=4096
#audit_log_rotations=7
#audit_log_include_commands='create,update,insert,drop,grant,delete,select' #审计日志的sql命令类型。
#新增配置
innodb_log_file_size=20M
binlog_stmt_cache_size=1M
binlog_cache_size=1M
table_open_cache=5000
#Start For Mysql Zabbix plugin
binlog_stmt_cache_size=1M
binlog_cache_size=1M
#End For Mysql Zabbix plugin
log-queries-not-using-indexes = false
gtid_mode=ON
enforce_gtid_consistency=on
master_info_repository=TABLE
relay_log_info_repository=TABLE
binlog_checksum=NONE
log_slave_updates=ON
#galera config 集群相关配置
wsrep_provider=/usr/lib64/libgalera_smm.so
wsrep_cluster_address=gcomm://192.168.2.181,192.168.2.183,192.168.2.185 #集群中的主机,根据实际情况填写。
wsrep_slave_threads=16
innodb_autoinc_lock_mode=2
wsrep_node_address=192.168.2.181 #本机用来做数据同步的IP地址,这里的地址可以和用来做服务的地址在不同网段。
wsrep_sst_method=xtrabackup-v2 #同步方式
pxc_strict_mode=MASTER #同步模式
wsrep_cluster_name=mysql-cluster #集群名称
wsrep_sst_auth="sstuser:s3creV9228s@#%" #用于检查同步情况的帐号和密码,可以只授权本地主机访问。
[client]
socket = /var/lib/mysql/mysql.sock
port = 3306
配置完第一台主机后需要使用service mysql@bootstrap start启动第一台主机。注意这个命令只在初始化集群的时候使用,如果集群已经启动过以后请使用service mysql start命令正常启动。包括集群中所有主机宕机以后的恢复。
centos7以上的系统请使用systemctl start mysql@bootstrap.service 和systemctl start mysql命令。
启动完成以后创建同步帐号:
CREATE USER 'sstuser'@'localhost' IDENTIFIED BY 's3creV9228s@#%';
GRANT RELOAD, LOCK TABLES,REPLICATION CLIENT ON . TO'sstuser'@'localhost';
请注意数据库目录和binlog等目录的权限,一定要是mysql。修改权限请使用chown mysql:mysql 目录名 -R 命令修改。启动具体报错请查看日志文件。
如果是从其它版本的数据库中迁移过来的数据,请使用mysql_upgrade -u root -p命令对数据库文件进行更新。否则可能无法正常访问数据表。
检查日志文件以后全部正常,数据库能正常操作访问以后第一台主机就启动完成了。
接下来是加入新节点。
在其它主机上安装好程序,创建好相关的文件目录把配置文件/etc/my.cnf复制过去。修改配置文件中的server-id、wsrep_node_address两个参数。然后使用service mysql start 或systemctl start mysql命令启动数据库,新加入的节点将会自动从主数据库中同步所有数据到新节点中。可以访问主数据库performance_schema.pxc_cluster_view表查看集群中节点的状态。SYNCED表示可用,JOIN表示正在加入,DONOR表示正在同步。具体请查看percona的官方文档。
新节点加入时请监控新节点的启动日志文件,排查相关错误。
启动同步节点报错
WSREP_SST: [ERROR] xtrabackup_checkpoints missing, failed innobackupex/SST on donor
检查主数据库目录下的innobackup.backup.log 日志文件查看具体原因。
所有节点全部加入集群以后,请把第一台节点使用service mysql@bootstrap stop 或者systemctl stop mysql@bootstrap.service停止。再使用正常的命令启动。这样整个percona的galare集群就配置完成了。
二、部署负载均衡服务haproxy和keepalive高可用
yum install haproxy keepalive -y 安装程序包。这里需要两个主机,配置不用太高。最好是数据库以外的主机来进行安装部署。这里需要规划出一个浮动地址用于高可用。
配置vi /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 50000 #整个服务的最大链接数
user root
group root
daemon
#turn on stats unix socket 做zabbix监控时需要
stats socket /var/lib/haproxy/stats
defaults
mode http
log global
option tcplog
option dontlognull
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout server 60m #做数据库需要配置1小时左右,60m可以是1h效果一样
timeout client 60m #做数据库需要配置1小时左右
timeout http-keep-alive 10s
timeout check 3s
listen stats #网页监控相关配置
bind :9099
stats uri /nstatus
stats enable
stats realm HAPorxy\ Stats\ Page
stats auth monitor:Hawatch3.tz.Com
stats admin if TRUE
listen mysql-cluster #负载均衡的服务配置
bind 0.0.0.0:3306
mode tcp
fullconn 13500 #提供的最大后端总链接数
balance leastconn #负载均衡的模式,经过测试这个模式是最适合mysql服务的。最小链接数优先
option httpchk
option tcplog
server db01 192.168.2.181:3306 maxqueue 30 maxconn 4500 check port 9200 inter 1000 rise 3 fall 3
server db02 192.168.2.183:3306 maxqueue 30 maxconn 4500 check port 9200 inter 1000 rise 3 fall 3
server db03 192.168.2.185:3306 maxqueue 30 maxconn 4500 check port 9200 inter 1000 rise 3 fall 3
db01可以是任意内容,每行代表一个后端主机不能重复。db01.example.com:3306 主机域名或者IP地址端口。maxqueue 建立后端连接时的最大列队,防止云服务器处理不过来后台被宕机。maxconn云服务器最大链接数,需要小于数据库的真实链接数配置。check port 9200 检查后端服务是否正常的端口。
通过以上配置后可以正常启动haproxy服务了。service haproxy start 或systemctl start haproxy。然后打开网页后端进行查看云服务器状态。这时可能还无法正常提供服务,需要对mysql的后端做一些配置。
到后端的数据库云服务器上安装xinetd。
yum install xinetd -y
/etc/xinetd.d/mysqlchk #提供检查端口的配置文件。
/usr/bin/clustercheck #检查结果的脚本,需要修改这个脚本中两个参数。
MYSQL_USERNAME="${1-sstuser}"
MYSQL_PASSWORD="${2-s3creV9228s@#%}" 检查状态的帐号密码可以用数据库同步的帐号密码。
然后启动xinetd服务,service xinetd start或者systemctl start xinetd。启动成功后再查看haproxy的监控页面就会发现后端服务变成可用状态了。
haproxy的日志需要配置rsyslog服务。
vi /etc/rsyslog.conf
$ModLoad imudp
$UDPServerRun 514
.info;mail.none;authpriv.none;cron.none;local2.none /var/log/messages
local2. /var/log/haproxy.log
上面的local2编号需要和haproxy配置文件中的一样。配置完以后重启service rsyslog restart。然后在/var/log/haproxy.log中就有日志文件了。
把上面haproxy的复制一份到另外一台主机上。配置rsyslog以后重启rsyslog服务,再启动haproxy就拥有了两台主机了。
配置keepalived实现高可用:
编辑vi /etc/keepalived/keepalived.conf 文件。
global_defs {
router_id mysql
}
vrrp_script check_ha {
script "/opt/share/selfTools/check_haproxy" #用于检测服务的脚本。需要自己编写,成功返回0失败返回非0的值,目录可以自己定义。
interval 2
}
vrrp_instance ha01 { #这个编号需要每个主机不一样
state BACKUP #两个都设置成BACKUP模式,可以避免频繁切换引发应用不稳定。
interface eth0 #绑定的网卡名称
virtual_router_id 22 #两个主机需要一样。
priority 100
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
check_ha
}
virtual_ipaddress {
192.168.2.191/24 dev eth0 scope global #浮动地址配置
}
}
脚本配置:/opt/share/selfTools/check_haproxy
#!/bin/bash
nc -z 127.0.0.1 3306 #检查本机的haproxy服务端口是否存在
status=$?
nc -z 127.0.0.1 9099 #检查haproxy的状态监控端口是否存在
status=$(($?+$status))
exit $status #返回脚本运行的退出值
这里需要在主机上安装nc。yum install nc -y
启动keepalived,service keepalived start 。然后检查浮动地址情况。把配置文件复制一份到另外的主机上,修改vrrp_instance ha01的名称。其它保持不变,启动keepalived服务即可。
到这里就算配置完成了,业务访问浮动地址就能直接分配到后端的数据库云服务器上。
三、监控服务
数据库集群监控,安装percona-zabbix-templates-1.1.8-1.noarch 、php包。
复制userparameter_percona_mysql.conf文件到/etc/zabbix/zabbix_agentd.d/目录下。
编辑文件vi /var/lib/zabbix/percona/scripts/ss_get_mysql_stats.php 填写mysql的监控帐号和密码然后保存。
检查zabbix.conf文件中是否有Include=/etc/zabbix/zabbix_agentd.d/.conf这个配置。没有请添加。
模版需要自己到zabbix监控里面配置,我的模版无法把文件上传上来。
percona的监控脚本还不能用于监控集群状态。需要自行编写脚本来监控。在zabbix的配置文件中添加两个内容。
UserParameter=Galera.discovery,/opt/share/shell/galera/galera_discovery.sh
UserParameter=Galera.[],/opt/share/shell/galera/galera_status.sh $1
脚本/opt/share/shell/galera/galera_discovery.sh内容:
#!/bin/bash
sql="show status like 'wsrep%';"
galeras=(echo "set names utf8;$sql" |HOME=/var/lib/zabbix mysql -N | awk '{print $1}')
text=(wsrep_local_state_uuid wsrep_flow_control_interval wsrep_local_state_comment wsrep_incoming_addresses wsrep_ist_receive_status wsrep_evs_repl_latency wsrep_evs_state wsrep_gcomm_uuid wsrep_cluster_state_uuid wsrep_cluster_status wsrep_connected wsrep_provider_name wsrep_provider_vendor wsrep_provider_version wsrep_ready)
float=(wsrep_cert_interval wsrep_commit_window wsrep_commit_oool wsrep_commit_oooe wsrep_apply_window wsrep_apply_oool wsrep_apply_oooe wsrep_cert_deps_distance wsrep_flow_control_paused wsrep_local_recv_queue_avg wsrep_local_send_queue_avg)
printf '{"data":['
i=1
for option in ${galeras[@]}
do
if [[ echo "${text[@]}" | grep "\b$option\b" ]] ;then
printf '{"{#TEXT}":"'$option
elif [[ echo "${float[@]}" | grep "\b$option\b" ]] ;then
printf '{"{#FLOAT}":"'$option
else
printf '{"{#OTNAME}":"'$option
fi
if [ $i -lt ${#galeras[@]} ];then
printf '"},'
else
printf '"}]}\n'
fi
i=$(($i+1))
done
脚本/opt/share/shell/galera/galera_status.sh内容:
#!/bin/bash
sql="show status like '$1';"
if [ -z $2 ];then
echo "set names utf8;$sql" |HOME=/opt/share/shell/galera mysql -N | awk '{print $2}'
else
echo "set names utf8;$sql" |HOME=/opt/share/shell/galera mysql -h$2 -N | awk '{print $2}'
fi
四、扩展解决方案
1、在使用HAproxy以后mysql中日志与客户端IP相关的信息将全部变成haproxy云服务器的地址。
启用haproxy的透传功能,把客户端IP通过haproxy传给realserver。数据包到达realserver以后将无法直接把数据返回给客户端的真实IP,这将无法建立tcp的链接。所以需要把数据包返回给haproxy云服务器。haproxy拿到数据包以后需要截取到相关数据包传给haproxy进程处理才能完成整个tcp的链接建立。具体看图: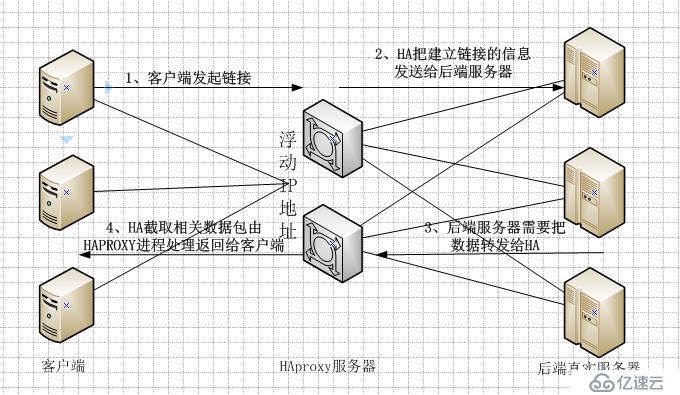
需要完成图中的几步才能完成整个建立过程。具体配置方法:
1)、配置haproxy。在配置的listen中加入source 0.0.0.0 usesrc clientip这样的配置。
2)、配置数据包截取:
配置/etc/sysctl.conf,添加 一下内容
net.ipv4.ip_forward = 1
net.ipv4.conf.default.rp_filter = 2
net.ipv4.conf.all.rp_filter = 2
net.ipv4.conf.eth0.rp_filter = 0
执行命令,执行完以后还需要配置开启自动运行。iptables相关规则可以保存后执行加载,路由表需要每次开机都进行创建。
iptables -t mangle -N MYSQL #单独在mangle表中创建一个名为MYSQL的链表
iptables -t mangle -A PREROUTING -m state --state RELATED,ESTABLISHED -j CONNMARK --restore-mark
iptables -t mangle -A PREROUTING -m mark ! --mark 0 -j ACCEPT
iptables -t mangle -A PREROUTING -p tcp -m socket -j MYSQL #从mangle表中的PREROUTING链中截取数据包是tcp协议,并且为socket的数据包。转发到MYSQL链表中。
iptables -t mangle -A MYSQL -j MARK --set-mark 1 #在MYSQL链表中把进来的数据包打上标签为1
iptables -t mangle -A MYSQL -j ACCEPT #接受所有数据包通过。
ip rule add fwmark 1 lookup 3306 #经过上面的数据包标记,在系统内核中就能分辨相关的数据包内容。这里新建一个路由表编号3306为数据包标记为1的路由。
ip route add local 0.0.0.0/0 dev lo table 3306 #在3306路由表中创建一条路由规则,把进入3306表中的数据包默认路由给本地环回口。这样haproxy就能拿到相关的数据包进行处理了。
3)、以上两步是在HAROXY的云服务器上配置。这步将在后端的真实云服务器上进行配置。
iptables -t mangle -N MYSQL #添加链表,意义同上
iptables -t mangle -A OUTPUT -p tcp --sport 3306 -j MYSQL #这里需要从OUTPUT链表中截取数据包,其它链表无效。具体原因请看下面的LINUX数据包转发图。获取源端口为3306的数据包,因为是OUTPUT出方向所以是源端口。
iptables -t mangle -A MYSQL -j MARK --set-mark 1 #进行数据包标记。
iptables -t mangle -A MYSQL -j ACCEPT #接受所有数据包通过
ip rule add fwmark 1 table 3306 #功能同上,创建新的路由表。
ip route add default via 192.168.2.191 table 3306 #添加默认路由,下一跳给到HAPROXY。
这里可以不进行数据包的截取标记也可以让业务正常,只需要添加一跳默认路由,ip route default via HAPROXY_IP。这样就能实现,但是ssh等其它服务将不能正常连接。
4)、可以代替第三节。主要是如果直接更改就没有对比了。下面的命令也是直接在数据库云服务器上做的。
iptables -t mangle -A PREROUTING -m state --state RELATED,ESTABLISHED -j CONNMARK --restore-mark #已经建立的链接自动附上标记
iptables -t mangle -A PREROUTING -m mark ! --mark 0 -j ACCEPT # 已经有标记的数据包直接放行,不进入下面匹配。提高处理效率。
iptables -t mangle -A PREROUTING -p tcp -m tcp --dport 3306 -m mac --mac-source 00:50:56:a0:13:a2 -j MARK --set-mark 1 #这里的MAC地址是HAPROXY云服务器的网卡地址。
iptables -t mangle -A PREROUTING -p tcp -m tcp --dport 3306 -m mac --mac-source 00:50:56:81:4F:08 -j MARK --set-mark 2 #我们有两个haproxy所以要两个标记
iptables -t mangle -A PREROUTING -j CONNMARK --save-mark #把这个做好标记的链路上所有数据包都保存好标记。
iptables -t mangle -A OUTPUT -j CONNMARK --restore-mark #前面做的都是客户端访问到主机时数据包的入方向,这句如果不加将无法路由出去。OUTPUT链是把数据包按照入方向标记好的记录,重新赋予相关的标记。让路由可以正确拿到出去的数据包。
ip rule add fwmark 1 table 3301
ip route add default via 192.168.2.150 table 3301 #这两条是对数据包进行路由,IP地址是haproxy的真实网卡地址。也就是上面mac地址为00:50:56:a0:13:a2主机IP地址,非浮动地址。
ip rule add fwmark 2 table 3302
ip route add default via 192.168.2.153 table 3302 #这两条和上面功能一样,IP地址是mac地址为00:50:56:81:4F:08的主机IP地址。
这里不用填写浮动地址,这样不管浮动地址在哪里。或者访问任何一个主机都可以正常连接数据库。
如果按照前面第三节的方法处理以后,客户端无法直接链接数据库、而且正常情况下也无法去访问没有浮动地址的那个云服务器。第四节的方法处理以后将和没有使用集群一样,链接和访问没有任何差异。
2、haproxy云服务器的状态监控。
在云服务器zabbix中配置两项/etc/zabbix/zabbix_agentd.conf。
UserParameter=ha.discovery,/opt/share/shell/zabbix-script/haproxy/haproxy_discovery.sh
UserParameter=Haproxy.[*],/opt/share/shell/zabbix-script/haproxy/haproxy_get.sh $1
haproxy_discovery.sh:
#!/bin/bash
node=(echo "show stat" | socat /var/lib/haproxy/stats stdio | sed "s/#//g" | awk 'BEGIN {FS=","}{print $2}' |sed '/FRONTEND/d;/BACKEND/d;1d;$d')
options=(qcur qmax scur smax stot status)
printf '{"data":['
i=1
for name in ${node[@]}
do
n=1
for op in ${options[@]}
do
if [ $n -lt ${#options[@]} ];then
printf '{"{#NODE}":"'$name-$op
else
printf '{"{#TEXT}":"'$name-$op
fi
if [ $i -lt ${#node[@]} ] || [ $n -lt ${#options[@]} ];then
printf '"},'
else
printf '"}]}\n'
fi
n=$(($n+1))
done
i=$(($i+1))
done
haproxy_get.sh:
#!/bin/bash
cd dirname $0
values=(echo $1|awk 'BEGIN{FS="-"}{print $1" "$2}')
case ${values[1]} in
"qcur")
grep ${values[0]} status.txt | awk '{print $2}'
;;
"qmax")
grep ${values[0]} status.txt | awk '{print $3}'
;;
"scur")
grep ${values[0]} status.txt | awk '{print $4}'
;;
"smax")
grep ${values[0]} status.txt | awk '{print $5}'
;;
"stot")
grep ${values[0]} status.txt | awk '{print $6}'
;;
"status")
grep ${values[0]} status.txt | awk '{print $7}'
;;
esac
为减少对haproxy的冲击。创建一个定时计划任务,定期获取状态数据保存到文件中。
haproxy_status.sh:
#!/bin/bash
cd dirname $0
echo "show stat" | socat /var/lib/haproxy/stats stdio | sed "s/#//g" | awk 'BEGIN {FS=","}{print $2"\t"$3"\t"$4"\t"$5"\t"$6"\t"$8"\t"$18}' > status.txt
如果没有socat命令需要使用yum安装。/var/lib/haproxy/stats这个文件需要有权限访问,用chmod 606来调整。
zabbix的调试可以在zabbix-server云服务器上使用zabbix_get命令进行调试。如:
zabbix_get -s 192.168.2.150 -k 'Haproxy.[db02-scur]' 其中的key是被监控主机自定义的字段名称。
同样模版的建立,请大家自行处理。无法上传模版文件共享。
以上关于如何实现Percona Mysql Galera多读写集群的部署详细内容,对大家有帮助吗?如果想要了解更多相关,可以继续关注我们的行业资讯板块。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





