
本文节选自《架构修炼之道》,作者京东王新栋。
图 | meghan-holmes-779221-unsplash
这里说的传统,是按照网关技术演进的阶段划分的,从同步到半同步,再到全异步,我们将同步和半同步技术下的网关称为“传统”网关,同步网关的意思是从接收请求到调用API接口提供方的过程都是同步调用;半同步则是指将I/O请求线程和业务处理线程分开,但业务线程内部还是同步调用API接口;全异步的意思就比较清楚了,整个链路都是异步请求。接下来介绍“传统”网关会在什么情况下“down掉”。
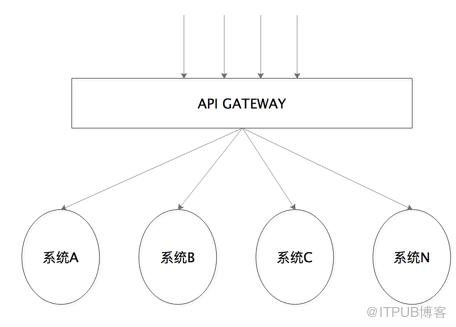
API网关系统有两大特点,一个是访问量大,另一个是依赖系统多。如下图所示,“单纯”的情况下(比如系统A提供的接口只供网关调用)网关系统要承受比被依赖的系统多数倍的流量,因为API网关是所有依赖API的集合。网关还会通过RPC调用很多底层系统,每个系统的稳定性水平参差不齐,接口的性能也会间接影响网关整体的运行稳定性。因此我们在做防范的时候就要从这两个特点入手。
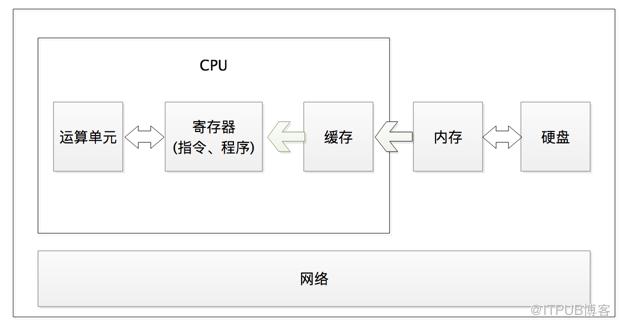
上面介绍了API网关的两大特点,这两个特点算外部因素,接着再来看一下内部因素。程序都是运行在计算机上面的,计算机的每个部件的利用率和负载水平直接影响程序的运行。比如CPU、内存、磁盘等。另外系统之间的交互还需要网络,这些都需考虑。一段程序在计算机中的运行依赖部件如下图所示。
关注CPU
用户请求在进入网关的时候我们从技术上已经把I/O请求线程和业务处理线程隔离开了,这一点可以利用Servlet3异步特性实现(下面还会详细介绍Servlet3的异步特性),如下图所示。
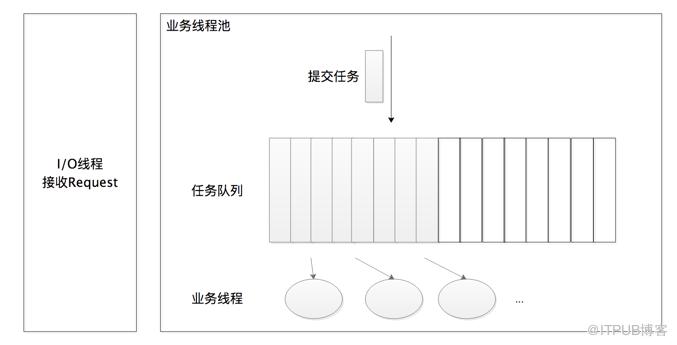
业务线程池毫无疑问是在CPU里面运行的,线程是计算机CPU最宝贵的资源,我们一定要重点关注CPU利用率和CPU负载。
CPU利用率:显示的是程序在运行期间实时占用的CPU百分比。
CPU负载:显示的是一段时间内正在使用和等待使用CPU的平均任务数。在Linux系统中,我们可以使用uptime或top(使用top会看到更详细的信息)命令来查看系统的负载情况。如果使用uptime命令则会得到如下一行:
11:36 up 23 days, 2:31, 2users, load averages: 1.74 1.58 1.60
最后的loadaverages的意思是系统平均负载,它包含三个数字,这三个数字分别表示1分钟、5分钟、15分钟内系统的负载平均值。我们可以按照1分钟的粒度取第一个数字,从而判定系统负载的大小。
上面的23days说明笔者有23天没有重启过计算机了。
注意,CPU利用率高,并不意味着负载就一定大,两者没有必然联系。

关于这两个概念的理解,我们还可以举一个例子来说明。有8个人在排队玩一个打地鼠的游戏机,要求1分钟之内要打完100个地鼠,如果有人一分钟之内没有完成这个任务,那么就需要重新排队,等待下一轮。游戏机在这里相当于CPU,正在或等待玩打地鼠游戏的人就相当于任务数量。
在玩游戏的过程中,肯定有的人在规定的1分钟之内打完100个地鼠,完成任务之后就离开了,有人没有完成任务而去重新排队,还有可能有新增的人来玩这个游戏,人数的变化相当于任务的增减。有的人拿起打地鼠的锤子就开始玩,一直打完1分钟,而有的人可能在前20秒看手机,后40秒才开始玩打地鼠。把游戏机看作CPU,排队的人数看作任务数,我们说前一种人(任务)的CPU利用率高,后一种人(任务)的CPU利用率低。
当然CPU不会在前20秒休息、后40秒工作,只是说,有的程序可能涉及的计算量比较大,CPU利用率就高,而有的程序涉及的计算少,CPU的利用率就低。不管CPU利用率是高是低,跟后面有多少人(任务)在排队没有必然的联系。
之所以花了一些篇幅来介绍CPU的这两个概念,因为这两个指标实在是太重要了,在线上生产环境中是需要重点监控的。鉴于API网关的访问量大和依赖系统多的特点,如果调用的API性能突然变差,在大访问量的情况下,线程数会逐渐升高,直至将CPU资源耗尽。蔓延到整个网关集群,这就是雪崩的效应。
关注磁盘
磁盘有两个比较重要的指标分别是磁盘使用率和磁盘负载百分比。磁盘使用率比较容易理解,我们重点说一下磁盘负载百分比这个指标。在Linux系统下查看该指标的命令为 iostat -x 1 10 (如果没有iostat ,则需要使用yum install sysstat进行安装),笔者下面的图中示例值还构不成威胁,但如果 %util 接近 100%,则说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈,如下图所示。

程序运行的过程中我们可能都不会关注磁盘的使用,如果处理不当,这有可能是一个“定时炸弹”。网关的特性访问量大,再加上有的程序里面的日志打印不规范,比如日志的级别设置得不合理,把info日志打印出来。即使在日志级别合理的情况下,比如error日志,这时又涉及网关的第二个特性,依赖系统多。当有API返回失败错误的时候,就会有大量的error日志写入磁盘,很容易把磁盘打满,尤其在容器时代,每台服务器分配的磁盘容量相对物理机来说都比较小,如果集群的所有机器磁盘被打满,对网关系统来说无疑是一场灾难。
关注网络
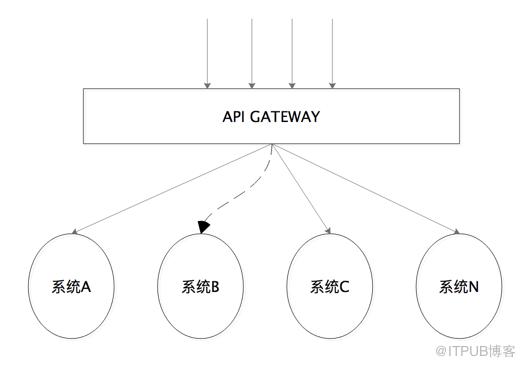
在微服务系统架构下,应用离不开网络,尤其是网关系统,它的特点之一就是依赖系统多。依赖就是RPC调用和网络。在一个RPC环境下,网络占据了一次RPC调用所耗时间的很大比重。网络质量的好坏直接影响了一次请求从进入API网关到返回给用户响应的时间长短。如下图所示,网关到依赖系统B之间的网络突然变差,调用时长增加,在请求访问量多的时候,一请求一线程的模式下,会直接导致API 网关系统的任务线程数增多,如果短时间内不能恢复,则整个API网关的集群所有机器的CPU资源都会被线程耗尽。
同时现有的线上生产环境部署并不能完全保证同机房调用,甚至还有跨地区调用,因此网络是我们要考虑的一个重要因素,同时网络的因素需要和上面讲到的CPU的线程资源相关联去考虑。
现在可以总结一个传统API网关系统会有几种“死”法了,因为依赖的某个系统的API性能突然变差导致请求线程数量逐渐升高直至线程占满了CPU,也就是API网关依赖系统多的特点因素,可以认为是被其他系统“拖死”的。线上生产环境下日志输出不规范,过度打印日志,再加上请求量突然变大,导致清理工具来不及清理日志,最后磁盘满了,可以认为是被日志“打死”的。网络一直是一个除系统本身外最不稳定的因素,在系统之间调用的时候,网络发生故障导致请求变慢,这一点和第一条被其他系统“拖死”类似,只是这次是网络。
查理.芒格有一句名言:“如果我知道我会死在哪里,我将永远不去那个地方”。同样对于一个API网关系统,如果我们知道哪些因素会导致一个网关“挂掉”,那么我们就会提前防范,以避免这种“灾难”的发生。当然并不是宣扬传统网关不好,它也有自己的优势,比如编程模型简单、开发调试运维方便等。如果业务规模较小,比如每天调用量不足千万,或者不到亿级,那么可以继续使用这种类型的网关,甚至达到亿级规模之后再配合有效的容错机制(比如Netflix的zuul1+Hystrix)也可以支撑上亿规模的访问量。不过我们有更好的异步网关解决方案,接下来介绍异步网关技术实现。
本文作者:王新栋
现就职于京东,“程序架道”公众号作者。平时热爱总结与分享,对高性能API网关、线程调优、NIO、微服务架构、容错等技术有较深的研究和实战经验。目前致力于带领团队在平台开放技术领域实现突破。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





