本篇内容主要讲解“怎么在SAP Cloud Platform上创建HANA并使用”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“怎么在SAP Cloud Platform上创建HANA并使用”吧!
本文使用的csv文件

SAP HANA XS) enables you to create database schema, tables, views, and sequences as design-time files in the repository.
这个练习里,我们将会使用SAP HANA Extended Application Services (XS)提供的database schema,tables和views来实现数据导入的效果。
The HDBtable syntax is a collective term which includes the different configuration schema for each of the various design-time data artifacts, for example: schema (.hdbschema), sequence (.hdbsequence), table (.hdbtable), and view (.hdbview).
This is why we will be using the SAP HANA HDBtable syntax including Core Data Service (CDS) artifacts instead, which only requires the SAP HANA Web-based Development Workbench available with any SAP HANA MDC on the SAP Cloud Platform. All the objects will be created as design-time and will allow us to adapt the structure easily without reloading the data.
首先在SAP Cloud Platform Neo环境的HANA MDC实例里,打开HANA Web-based development workbench,切换到Catalog视图:

点击SQL,使用SQL语句创建一个新的user: MOVIELENS_USER

DROP USER MOVIELENS_USER CASCADE;
CREATE USER MOVIELENS_USER PASSWORD Welcome18Welcome18 NO FORCE_FIRST_PASSWORD_CHANGE;
ALTER USER MOVIELENS_USER DISABLE PASSWORD LIFETIME;
call _SYS_REPO.GRANT_ACTIVATED_ROLE ('sap.hana.ide.roles::CatalogDeveloper' ,'MOVIELENS_USER');
call _SYS_REPO.GRANT_ACTIVATED_ROLE ('sap.hana.ide.roles::Developer' ,'MOVIELENS_USER');
call _SYS_REPO.GRANT_ACTIVATED_ROLE ('sap.hana.ide.roles::EditorDeveloper' ,'MOVIELENS_USER');
call _SYS_REPO.GRANT_ACTIVATED_ROLE ('sap.hana.xs.ide.roles::CatalogDeveloper' ,'MOVIELENS_USER');
call _SYS_REPO.GRANT_ACTIVATED_ROLE ('sap.hana.xs.ide.roles::Developer' ,'MOVIELENS_USER');
call _SYS_REPO.GRANT_ACTIVATED_ROLE ('sap.hana.xs.ide.roles::EditorDeveloper' ,'MOVIELENS_USER');
GRANT EXECUTE on _SYS_REPO.GRANT_ACTIVATED_ROLE TO MOVIELENS_USER WITH GRANT OPTION;
GRANT EXECUTE on _SYS_REPO.GRANT_SCHEMA_PRIVILEGE_ON_ACTIVATED_CONTENT TO MOVIELENS_USER WITH GRANT OPTION;
GRANT EXECUTE on _SYS_REPO.GRANT_PRIVILEGE_ON_ACTIVATED_CONTENT TO MOVIELENS_USER WITH GRANT OPTION;
GRANT EXECUTE on _SYS_REPO.REVOKE_ACTIVATED_ROLE TO MOVIELENS_USER WITH GRANT OPTION;
GRANT EXECUTE on _SYS_REPO.REVOKE_SCHEMA_PRIVILEGE_ON_ACTIVATED_CONTENT TO MOVIELENS_USER WITH GRANT OPTION;
GRANT EXECUTE on _SYS_REPO.REVOKE_PRIVILEGE_ON_ACTIVATED_CONTENT TO MOVIELENS_USER WITH GRANT OPTION;
GRANT "CREATE SCHEMA" TO MOVIELENS_USER;
GRANT REPO.READ on "public" TO MOVIELENS_USER;
GRANT REPO.MAINTAIN_IMPORTED_PACKAGES on "public" TO MOVIELENS_USER;
GRANT REPO.MAINTAIN_NATIVE_PACKAGES on "public" TO MOVIELENS_USER;
GRANT REPO.EDIT_NATIVE_OBJECTS on "public" TO MOVIELENS_USER;
GRANT REPO.EDIT_IMPORTED_OBJECTS on "public" TO MOVIELENS_USER;
GRANT REPO.ACTIVATE_NATIVE_OBJECTS on "public" TO MOVIELENS_USER;
GRANT REPO.ACTIVATE_IMPORTED_OBJECTS on "public" TO MOVIELENS_USER;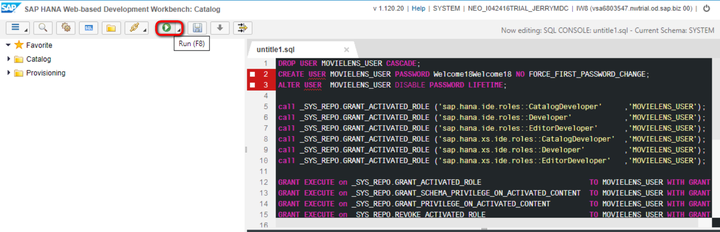
执行后,该用户创建成功:

注销SYSTEM用户,使用新创建的用户登录:


切换到Editor视图:

在content节点下,右键菜单,新建一个Application:


Package维护成public.aa.movielens:

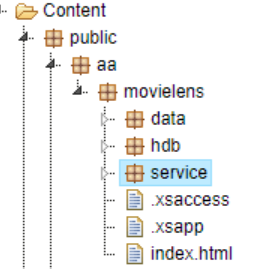
新建三个package,分别为data, hdb和service:

将之前链接里提供的csv文件导入data package内:

HANA schema是存放HANA数据库对象诸如表,视图,存储过程等的容器。
新建一个.hdbschema文件,内容如下:

再创建一个user.hdbrole文件:

内容如下:
role public.aa.movielens.hdb::user extends catalog role "sap.pa.apl.base.roles::APL_EXECUTE", "AFLPM_CREATOR_ERASER_EXECUTE", "AFL__SYS_AFL_AFLPAL_EXECUTE"
{
schema public.aa.movielens.hdb:MOVIELENS.hdbschema: SELECT, EXECUTE, CREATE ANY;
}这个role定义了我们创建的这个应用工作时需要的权限:


最后创建CDS artifacts:
新建一个 data.hdbdd文件:
namespace public.aa.movielens.hdb;
@Schema : 'MOVIELENS'
context "data" {
@Catalog.tableType : #COLUMN
Entity LINKS {
key MOVIEID : Integer;
IMDBID : Integer;
TMDBID : Integer;
};
@Catalog.tableType : #COLUMN
Entity MOVIES {
key MOVIEID : Integer;
TITLE : String(255);
GENRES : String(255);
};
@Catalog.tableType : #COLUMN
Entity RATINGS {
key USERID : Integer;
key MOVIEID : Integer;
RATING : hana.SMALLDECIMAL;
TIMESTAMP : Integer;
};
@Catalog.tableType : #COLUMN
Entity TAGS {
key USERID : Integer;
key MOVIEID : Integer;
key TAG : String(255);
TIMESTAMP : Integer;
};
};
使用下列的SQL语句将新创建的user role分配给用户MOVIELENS_USER:

创建一个table-import配置文件,在里面指定存储于csv文件里的数据,按照怎样的逻辑写入HANA MDC的持久化对象,比如数据库表里。
hdb package里创建一个新的文件 data.hdbti :
import = [
{
table = "public.aa.movielens.hdb::data.LINKS";
schema = "MOVIELENS" ;
file = "public.aa.movielens.data:links.csv";
header = true;
delimField = ",";
delimEnclosing= "\"";
},
{
table = "public.aa.movielens.hdb::data.MOVIES";
schema = "MOVIELENS" ;
file = "public.aa.movielens.data:movies.csv";
header = true;
delimField = ",";
delimEnclosing = "\"";
},
{
table = "public.aa.movielens.hdb::data.RATINGS";
schema = "MOVIELENS" ;
file = "public.aa.movielens.data:ratings.csv";
header = true;
delimField = ",";
delimEnclosing= "\"";
},
{
table = "public.aa.movielens.hdb::data.TAGS";
schema = "MOVIELENS" ;
file = "public.aa.movielens.data:tags.csv";
header = true;
delimField = ",";
delimEnclosing= "\"";
}
];此时执行下列SQL语句,就可以成功从HANA MDC实例的数据库表里读取源自csv文件里的数据了:
select 'links' as "table name", count(1) as "row count" from "MOVIELENS"."public.aa.movielens.hdb::data.LINKS" union all select 'movies' as "table name", count(1) as "row count" from "MOVIELENS"."public.aa.movielens.hdb::data.MOVIES" union all select 'ratings' as "table name", count(1) as "row count" from "MOVIELENS"."public.aa.movielens.hdb::data.RATINGS" union all select 'tags' as "table name", count(1) as "row count" from "MOVIELENS"."public.aa.movielens.hdb::data.TAGS";

到此,相信大家对“怎么在SAP Cloud Platform上创建HANA并使用”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





