这篇文章给大家分享的是有关JDK 1.8中HashMap数据结构的示例分析的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
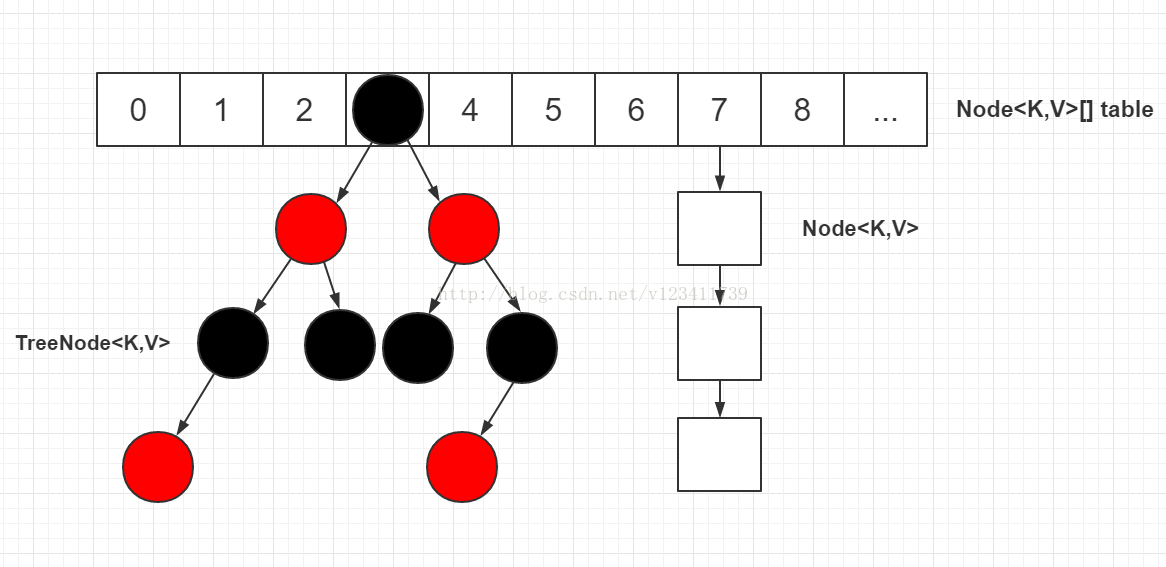
JDK 1.8对HashMap361天恒平台制作,进行了比较大的优化,底层实现由之前的“数组+链表”改为“数组+链表+红黑树”,本文就HashMap的几个常用的重要方法和JDK 1.8之前的死循环问题展开学习讨论。JDK 1.8的HashMap的数据结构如下图所示,当链表节点较少时仍然是以链表存在,当链表节点较多时(大于8)会转为红黑树。
先了解以下几个点,有利于更好的理解HashMap的源码和阅读本文。
头节点指的是table表上索引位置的节点,也就是链表的头节点。
根结点(root节点)指的是红黑树最上面的那个节点,也就是没有父节点的节点。
红黑树的根结点不一定是索引位置的头结点。
转为红黑树节点后,链表的结构还存在,通过next属性维持,红黑树节点在进行操作时都会维护链表的结构,并不是转为红黑树节点,链表结构就不存在了。
在红黑树上,叶子节点也可能有next节点,因为红黑树的结构跟链表的结构是互不影响的,不会因为是叶子节点就说该节点已经没有next节点。
源码中一些变量定义:如果定义了一个节点p,则pl为p的左节点,pr为p的右节点,pp为p的父节点,ph为p的hash值,pk为p的key值,kc为key的类等等。源码中很喜欢在if/for等语句中进行赋值并判断,请注意。
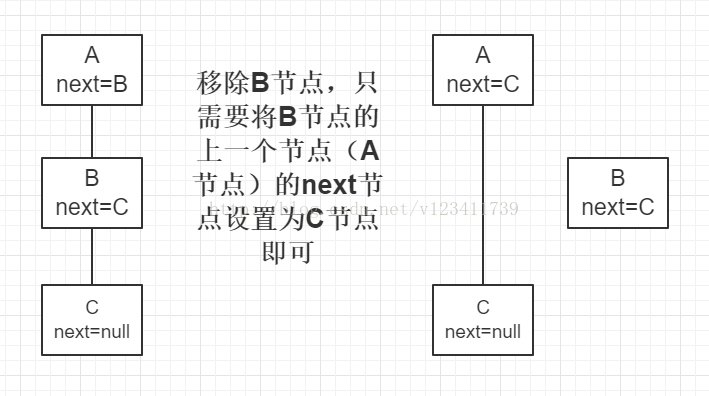
链表中移除一个节点只需如下图操作,其他操作同理。
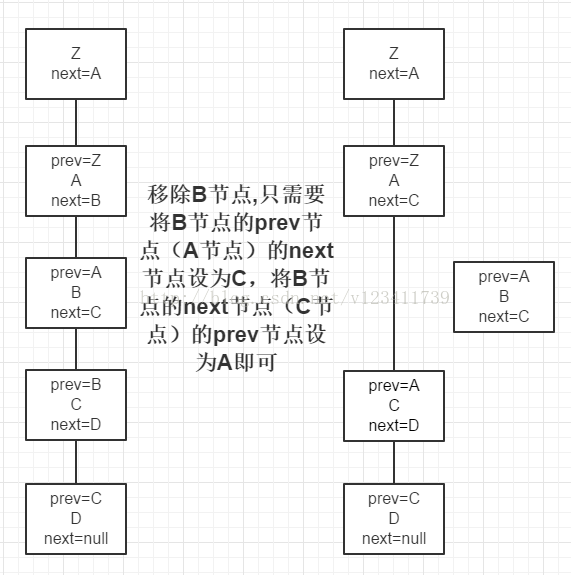
红黑树在维护链表结构时,移除一个节点只需如下图操作(红黑树中增加了一个prev属性),其他操作同理。注:此处只是红黑树维护链表结构的操作,红黑树还需要单独进行红黑树的移除或者其他操作。
源码中进行红黑树的查找时,会反复用到以下两条规则:1)如果目标节点的hash值小于p节点的hash值,则向p节点的左边遍历;否则向p节点的右边遍历。2)如果目标节点的key值小于p节点的key值,则向p节点的左边遍历;否则向p节点的右边遍历。这两条规则是利用了红黑树的特性(左节点<根结点<右节点)。
源码中进行红黑树的查找时,会用dir(direction)来表示向左还是向右查找,dir存储的值是目标节点的hash/key与p节点的hash/key的比较结果。
/** * The default initial capacity - MUST be a power of two. */static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认容量16/** * The maximum capacity, used if a higher value is implicitly specified * by either of the constructors with arguments. * MUST be a power of two <= 1<<30. */static final int MAXIMUM_CAPACITY = 1 << 30; // 最大容量/** * The load factor used when none specified in constructor. */static final float DEFAULT_LOAD_FACTOR = 0.75f; // 默认负载因子0.75/** * The bin count threshold for using a tree rather than list for a * bin. Bins are converted to trees when adding an element to a * bin with at least this many nodes. The value must be greater * than 2 and should be at least 8 to mesh with assumptions in * tree removal about conversion back to plain bins upon * shrinkage. */static final int TREEIFY_THRESHOLD = 8; // 链表节点转换红黑树节点的阈值, 9个节点转/** * The bin count threshold for untreeifying a (split) bin during a * resize operation. Should be less than TREEIFY_THRESHOLD, and at * most 6 to mesh with shrinkage detection under removal. */static final int UNTREEIFY_THRESHOLD = 6; // 红黑树节点转换链表节点的阈值, 6个节点转/** * The smallest table capacity for which bins may be treeified. * (Otherwise the table is resized if too many nodes in a bin.) * Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts * between resizing and treeification thresholds. */static final int MIN_TREEIFY_CAPACITY = 64; // 转红黑树时, table的最小长度/** * Basic hash bin node, used for most entries. (See below for * TreeNode subclass, and in LinkedHashMap for its Entry subclass.) */static class Node<K,V> implements Map.Entry<K,V> { // 基本hash节点, 继承自Entryfinal int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}public final boolean equals(Object o) {if (o == this)return true;if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>)o;if (Objects.equals(key, e.getKey()) &&Objects.equals(value, e.getValue()))return true;}return false;}}/** * Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn * extends Node) so can be used as extension of either regular or * linked node. */static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {// 红黑树节点TreeNode<K,V> parent; // red-black tree linksTreeNode<K,V> left;TreeNode<K,V> right;TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red;TreeNode(int hash, K key, V val, Node<K,V> next) {super(hash, key, val, next);}// ...}不管增加、删除、查找键值对,定位到哈希桶数组的位置都是很关键的第一步。前面说过HashMap的数据结构是“数组+链表+红黑树”的结合,所以我们当然希望这个HashMap里面的元素位置尽量分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,不用遍历链表/红黑树,大大优化了查询的效率。HashMap定位数组索引位置,直接决定了hash方法的离散性能。下面是定位哈希桶数组的源码:
// 代码1static final int hash(Object key) { // 计算key的hash值int h;// 1.先拿到key的hashCode值; 2.将hashCode的高16位参与运算return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}// 代码2int n = tab.length;// 将(tab.length - 1) 与 hash值进行&运算int index = (n - 1) & hash;整个过程本质上就是三步:
拿到key的hashCode值
将hashCode的高位参与运算,重新计算hash值
将计算出来的hash值与(table.length - 1)进行&运算
方法解读:
对于任意给定的对象,只要它的hashCode()返回值相同,那么计算得到的hash值总是相同的。我们首先想到的就是把hash值对table长度取模运算,这样一来,元素的分布相对来说是比较均匀的。
但是模运算消耗还是比较大的,我们知道计算机比较快的运算为位运算,因此JDK团队对取模运算进行了优化,使用上面代码2的位与运算来代替模运算。这个方法非常巧妙,它通过 “(table.length -1) & h” 来得到该对象的索引位置,这个优化是基于以下公式:x mod 2^n = x & (2^n - 1)。我们知道HashMap底层数组的长度总是2的n次方,并且取模运算为“h mod table.length”,对应上面的公式,可以得到该运算等同于“h & (table.length - 1)”。这是HashMap在速度上的优化,因为&比%具有更高的效率。
在JDK1.8的实现中,还优化了高位运算的算法,将hashCode的高16位与hashCode进行异或运算,主要是为了在table的length较小的时候,让高位也参与运算,并且不会有太大的开销。
感谢各位的阅读!关于“JDK 1.8中HashMap数据结构的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。