索引是一种数据结构,以其特有的记录数据的方式,为用户提供高性能的查询。索引就像是一本新华字典的目录,通过目录可以快速的找到我们想要找到的数据。
普通索引:MySQL中基本索引类型,仅有加速查询功能,允许在定义索引的列中插入重复的值和空值。
主键索引:有两个功能:加速查询 和 唯一约束(不可含null)
唯一索引:有两个功能:加速查询 和 唯一约束(可含null)
组合索引:组合索引是将n个列组合成一个索引part1:创建表时创建索引
create table user(
nid int not null auto_increment primary key,
name varchar(50) not null,
passwd varchar(100) not null,
extra text,
index idx1(name)
)note:如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。
part2:创建索引
create index idx2 on user(name);show index from user;drop index idx2 on user;part1:创建表时创建索引
create table user(
nid int not null auto_increment primary key,
name varchar(50) not null,
passwd varchar(100) not null,
extra text,
unique idx1(name)
)part2:创建索引
create unique idx2 on user(name);show index from user;drop index idx2 on user;part1:创建表时创建索引
create table user(
nid int not null auto_increment ,
name varchar(50) not null,
passwd varchar(100) not null,
extra text,
primary key(nid),
index idx1(name)
)part2:创建索引
alter table idx2 add primary key(nid);alter table user drop primary key;
alter table user modify nid int, drop primary key;part1:创建表时创建索引
create table user(
nid int not null auto_increment primary key,
name varchar(50) not null,
passwd varchar(100) not null,
index idx(nid,name,passwd)
)
part2:创建索引
create index idx on user(nid,name,passwd);show index from user;drop index idx on user;组合索引查询遵循最左匹配:如查询:
nid and name :使用索引
nid and passwd :使用索引
passwd:不适用索引
上述4种MySQL常用的索引,其查找数据的顺序都是先在索引中找,再去数据表中找。如果一个查询只在索引中便能完成,而不需要去数据表中找,这种索引被称为覆盖索引。覆盖索引必须要求存储索引的列,所以只有btree索引能使用更为高效的覆盖索引。
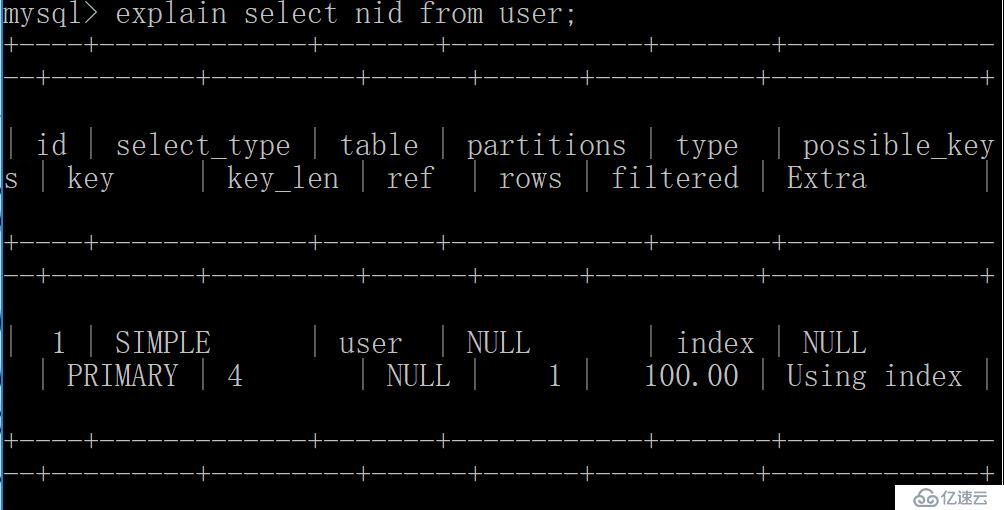
explain用于显示SQL执行信息参数,根据参考信息可以进行SQL优化
mysql> explain select * from t1;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)EXPLAIN列的解释:
select_type :查询类型
table:正在访问的表名
type:连接类型,性能:all < index < range < index_merge < ref_or_null < ref < eq_ref < system/const
possible_keys:显示可能应用在这张表中的索引,也可以是where语句后合适的语句
key:实际使用的索引
key_len:实际使用的索引的字节长度
rows:为了找到所需的内容预估要读取的行数
extra:描述信息如下
Using index:要查询的列数据仅使用索引中的信息,而没有读取数据表中的信息
Using temporary:mysql需要创建一个临时表来存储结果,这通常发生在对不同的列集进行order by上,而不是group by上,这种情况下,需要优化查询
Using filesort:这意味着mysql会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。mysql有两种文件排序算法,这两种排序方式都可以在内存或者磁盘上完成,explain不会告诉你mysql将使用哪一种文件排序,也不会告诉你排序会在内存里还是磁盘上完成。
Range checked for each record(index map: #):没有找到合适的索引,因此对从前面表中来的每一个行组合,#是显示在possible_keys列中索引的位图,并且是冗余的。
更多详细信息参见:MySQL官方文档
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





