Puppet监控速查问题的原因及解决方案是什么,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
Puppet是基于C/S架构的集中配置管理系统,基于自有描述性语言,可以实现对配置文件、用户、定时任务、软件包、系统服务等管理,保证大规模集群基础配置一致性。
我们用Puppet管理了上千台服务器,经过多次优化监控,自动化灰度发布保证了所有集群基础配置一致性。本文探讨了如何对Puppet系统进行监控,也将典型问题和解决方案一并分享给大家。
监控选型
Foreman提供了较全面的交互设施,包括Web前端、CLI和RESTful API。在此基础之上,可以构建监控管理系统,以及实现报警等功能。
核心业务流程
可以简单将Puppet的工作流程抽象为四部分:
请求阶段:Agent基于SSL将自身信息发送给Server;
响应阶段:Server基于客户端信息解析相应的配置,并最终将伪代码(catalog)发送回Agent;
执行阶段:Agent接收catalog并执行命令或者更新文件;
汇报阶段:Agent把结果汇报给Server。
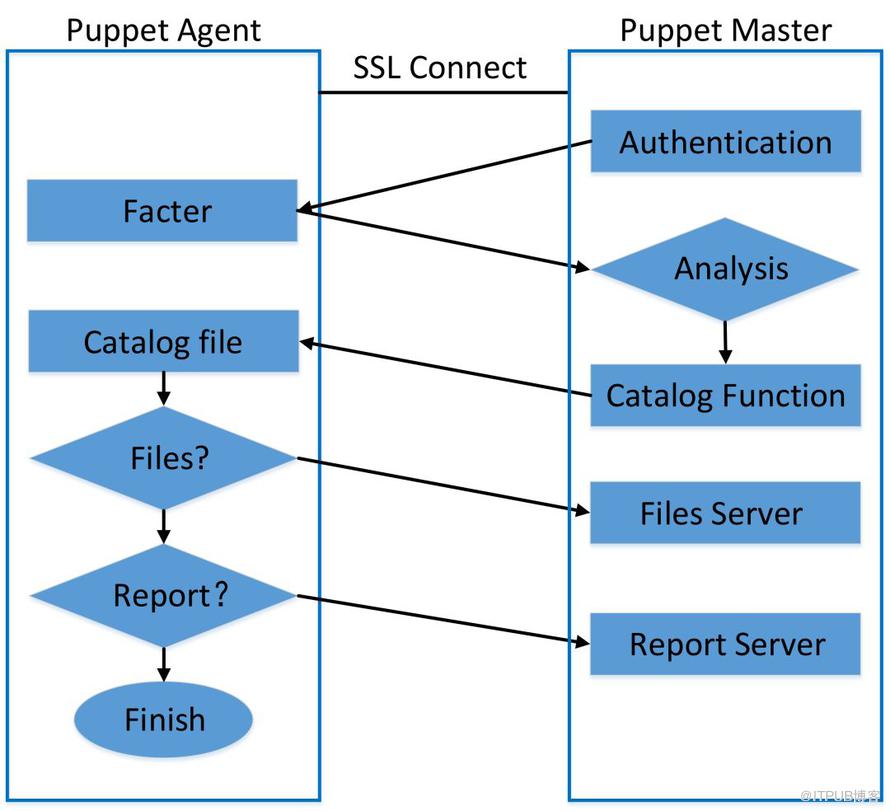
图1 Puppet工作流程
监控概览
对Puppet的核心监控主要覆盖如下环节:
Agent与Master通信是否正常;
Agent策略执行是否生效;
Puppet发布的策略生效时间及范围;
Master及其所管理集群的运行状态。
黑盒监控
Puppet黑盒监控指标不符合预期,说明集群不能正常工作或出现异常,黑盒监控指标有:所有策略是否都生效,策略生效范围是否符合预期,策略生效结果是否符合预期。
所有策略是否都生效
说明:将一批测试节点,加入到线上Puppet集群,通过定期运行检查脚本验证所有策略是否都生效。
策略生效范围
说明:策略上线后,需要确认其生效范围是否符合预期,即策略是否仅在指定的节点生效。
实现:通过Puppet模块MCollective定时执行检查任务(检查实际生效的机器列表和服务树机器列表是否一致),如下图,集群hn-xdata 有98%的机器符合预期,2%不符合。
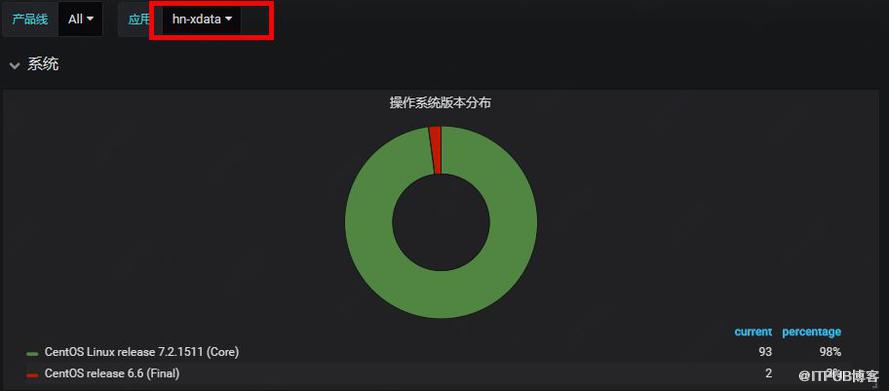
图2 Puppet策略生效范围监控
策略生效结果是否符合预期
说明:策略上线后,需要确保所有策略在所有机器都生效。
实现:通过Puppet模块MCollective定时执行检查任务,(检查实际生效的机器列表和服务树机器列表是否一致),如下图,每一个策略有一张饼图。
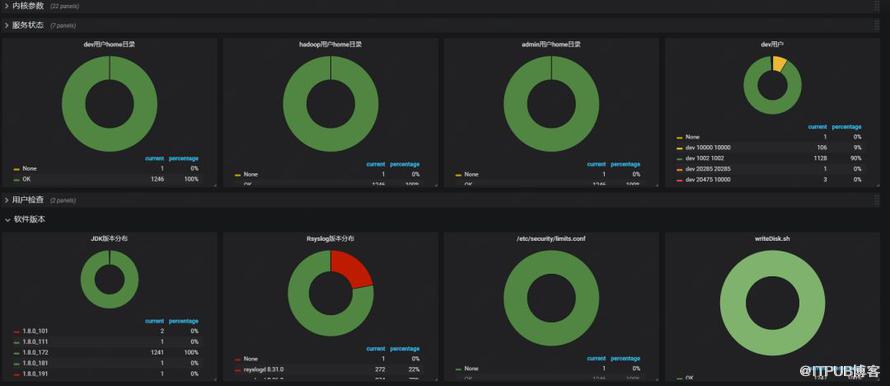
图3 Puppet策略结果监控
白盒监控
白盒监控是黑盒监控的补充,服务于故障定位,从集群容量、流量、延迟、错误四个方面梳理。
数据采集方式:
通过Foreman API
Master日志分析
表1 通过Foreman API获取采集的白盒指标概览
指标 | 说明 |
No reports | 没有汇报的主机 |
Error | 连上了但是执行策略出错 |
Out of sync | 执行策略超时;主机名重复;主机连不上 |
Active | Agent拉取策略正常 |
Pending | 容量指标,Master处理不过来 |
No changes | Agent正常拉取策略但是没有变更 |
puppet_report_time_total | Agent执行策略总时间 |
Pv | 每分钟访问量 |
容量
Master所在实例的CPU,网络连接数指标,网卡
流量
Agent PV,基于Puppet Master的访问日志puppetserver-access.log来计算流量
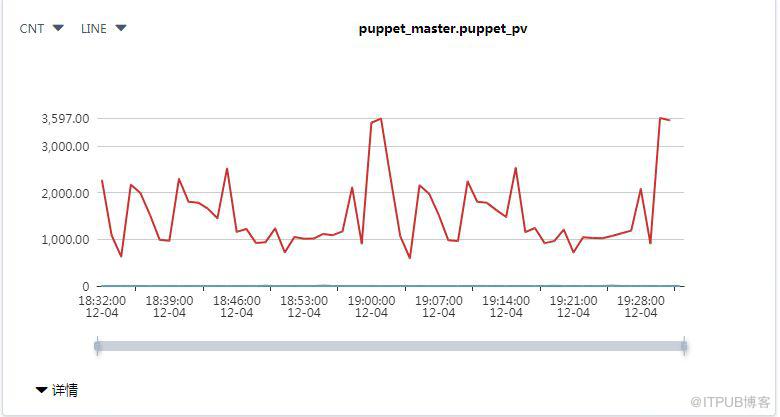
图4 Agent PV流量图
延迟
单个Agent更新策略需要的时间:puppet_report_time_total
说明:puppet_report_time_total 是Agent从连接Master到发送报告给Master总时间,0-3s的占50%,0-11s的占90%,0-15s占99%。
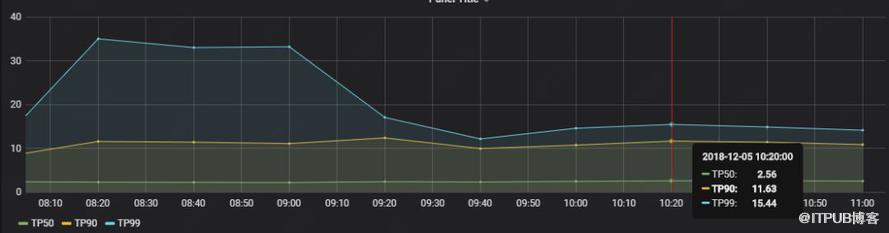
图5 Agent 延迟
错误
No reports:没有报告的实例数量;
Error agent:执行策略出错的实例数量;
Out of sync:执行策略超时、主机名重复、主机连不上Master的实例数量。
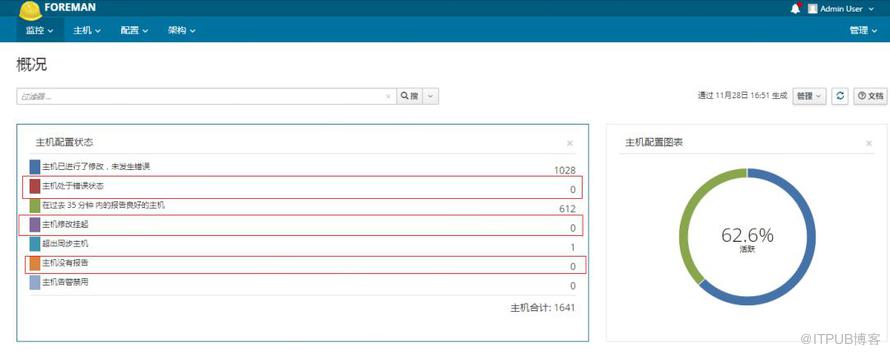
图6 Foreman错误监控指标
Puppet监控发现的问题
Agent覆盖所有机器
问题:不能保证所有机器Agent都正常运行。
解决方案:基于服务树或者CMDB相关系统将所有机器填加Agent进程监控。
Agent执行策略超时
问题:大文件并发下载时,出现超时告警。
排查方法:在Agent上执行命令“puppet agent -t --debug”, 发现在拉取文件时超时,由于文件较大,在Master上同时很多Agent拉取,导致超时。
解决方案:将大文件存放在云存储上,提高下载速度。
分组不止仅限于现有Facter属性
问题:策略分组和灰度发布分组现有Facter属性不满足。
原因:随着接入业务越来越多,业务分组也越多。
解决方案:自定义Facter。
Agent不同步(Out of Sync)
问题:Agent报不同步。
原因及解决方案:
表二
原因 | 解决方案 |
主机名重复 | 修改Agent Hostname后重新认证 |
主机认证后重命名 | 直接在Foreman控制台中删除原名称认证的机器 |
Agent服务异常 | 在Agent上重启Puppet服务 |
Agent磁盘打满 | 清理磁盘后,Agent会自行启动并恢复 |
Agent端证书error | 在Agent上删除/etc/puppetlabs/puppet/ssl文件夹后,执行puppet agent –t重新认证 |
Agent端puppet.conf文件为空 | 将相应的[Agent]配置写入puppet.conf文件中即可恢复 |
Master端puppe.conf文件为空 | 将相应[Master]配置写入puppet.conf文件中即可恢复 |
Foreman服务down掉 | 在Foreman机器上执行service httpd restart、service foreman restart |
Could not request certificate | 1)Agent与Master时间不同步,ntpdate master –IP同步时间;2)Agent与Master端网络不通;3)Master端8140端口不通 |
策略发布到非预期集群
问题:策略生效范围出错。
原因:Puppet Master入口文件统一为site.pp,由于策略分组多,在灰度发布阶段,相应分支也会很多,运维工程师很容易操作出错。
解决方案:将site.pp作为一个策略模块进行管理,策略模块中包含默认default分组,以及需要灰度发布的分组。manifest文件夹下的site.pp只需include该模块即可。
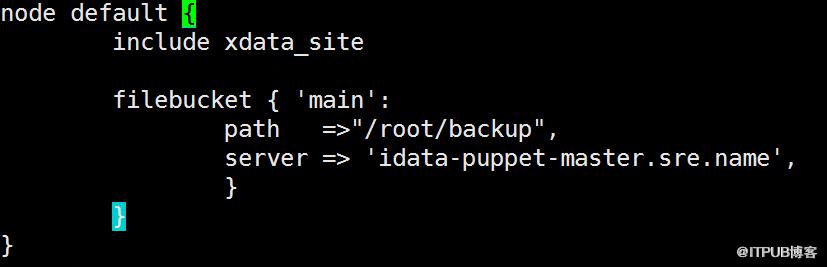
图7 site.pp优化后default分组策略
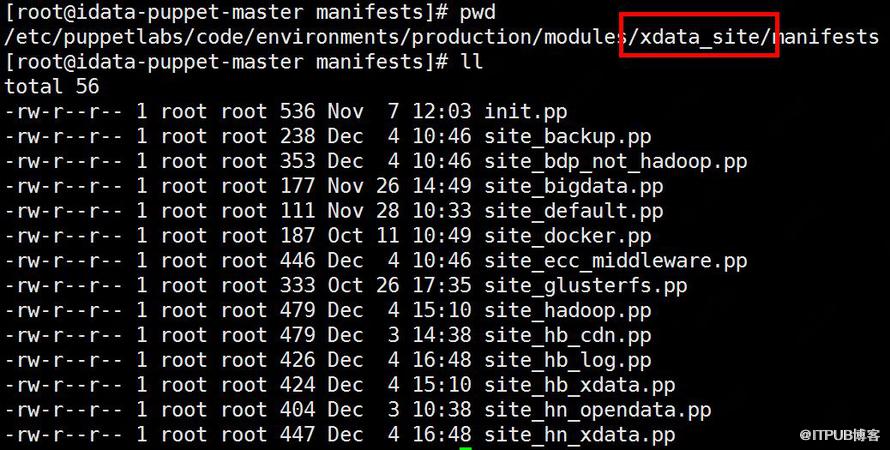
图8 策略发布灰度阶段分组
功能监控发现所同步的文件非预期
问题:Master采用集群方式部署,在策略变更期间多台Master上数据可能不同步,此时,同一Agent拉取到的文件可能不一致 。
原因:由于有多台Master,其中一台Master没有更新文件,LB通过轮询策略进行转发,当Agent请求Master时是Master A,再拉取文件时请求的可能是Master B,两台Master数据不一致。
解决方案:LB策略更新为源IP哈希。
看完上述内容,你们掌握Puppet监控速查问题的原因及解决方案是什么的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/31557889/viewspace-2284410/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



