写在前面
在当今信息爆炸的时代,单台计算机已经无法负载日益增长的业务发展,虽然也有性能强大的超级计算机,但是这种高端机不仅费用高昂,也不灵活,一般的企业是负担不起的,而且也损失不起,那么将一群廉价的普通计算机组合起来,让它们协同工作就像一台超级计算机一样地对外提供服务,就成了顺其自然的设想,但是这又增加了软件的复杂度,要求开发的软件需要具备横向扩展能力,比如:Kafka、Elasticsearch、Zookeeper等就属于这一类软件,它们天生都是"分布式的",即可以通过添加机器节点来共同地分摊数据存储和负载压力。
为什么需要集群?
分布在不同区域的计算机,彼此之间通过网络建立通信,相互协作作为一个整体对外提供服务,这就是集群,如果我们开发的系统具备这样的能力,那么理论上就具备无限横向扩容的能力,系统的吞吐量就会随着机器数增加而增长,那么未来当系统出现高负载的时候,就可以很好地应对这种情况。
为什么CAP不能同时满足?
通过上面分析,我们知道实现集群,其实就是采用多台计算机来共同承担和负载系统压力,那么就涉及到多台计算机需要参与一起处理数据,为了保证可用性,一般都会在每台计算机上备份一份数据,这样只要有一个节点保持同步状态,那么数据就不会丢失,比如kafka分区多副本、Elasticsearch的副本分片,由于同一数据块及其副本位于不用的机器,随着时间的推移,再加上不可靠的网络通信,所有机器上的数据必然会不完全一致,这个时候假如发生一种极端情况,所有的机器宕机了,又如何保证数据不丢失呢(其实只有两种方法)?
1、保证可用性:选择第一台恢复正常服务的机器(不一定拥有全部数据)作为可信的数据来源,快速恢复集群,即停机时间优于同步。
2、保证数据一致性:等待第一台拥有全部数据的机器恢复正常,再恢复集群,即同步优于停机时间,比如禁用kafka的unclean leader选举机制就是这种策略。
其实当大多数机器不可用时,就需要在可用性和一致性之间进行妥协了,所以另一个更符合分布式系统的Base理论又被创造出来了。
如何解决分布式存储问题?
当由多台计算机组成的集群对外提供服务时,其实就是对外提供读、写的能力。
数据块技术(data block)
为了将数据合理、均匀地写到各个机器上,提高集群写能力;为了将读请求负载均衡到不同的节点,提高集群的读能力;为了解耦数据存储和物理节点,提高分布式读写并行处理的能力,聪明的工程师引入了一个逻辑数据存储单位,统称为数据块,比如Kafka的分区(partion)、Elasticsearch的分片(shard),这样的虚拟化大大提高了集群读写的灵活性。
备注:所以啊,名字不重要,知其所以然最重要。
协调节点(coordination node)
实际上当集群作为一个整体处理数据时,可能每一个节点都会收到读写请求,但是数据又是分散在不同的节点上,所以就需要每个节点都清楚地知道集群中任意一个数据块的位置,然后再将请求转发到相应的节点,这就是“协调节点”的工作。比如:Elasticsearch的master节点管理集群范围内的所有变更,主分片管理数据块范围内的所有变更。
大多数投票机制(quorum)
百度百科:quorum,翻译法定人数,指举行会议、通过议案、进行选举或组织某种专门机构时,法律所规定的必要人数,未达法定人数无效。
由于网络分区的存在,这个机制被广泛地应用于分布式系统中,比如集群节点之间选举Master;数据块之间选举Header等;在分布式存储中,也被称为Quorum读写机制,即写入的时候,保证大多数节点都写入成功(一般的做法会选举一个主数据块(header),保证它写成功,然后再同步到冗余的副本数据块);读取的时候保证读取大多数节点的数据(一般的做法是由协调节点分发请求到不同的节点,然后将所有检索到的数据进行全局汇总排序后再返回);由于读写都是大多数,那么中间肯定存在最新的重叠数据,这样就能保证一定能读到最新的数据。
从上面分析可以得出,只要大多数节点处于活跃可用状态,那么整个集群的可用性就不会受到影响;只要大多数据块处于活跃可用的状态,那么就能持续地提供读写服务;只要有一个数据块完成了同步状态,那么数据就不会丢失;这其实就是通过一种冗余机制来尝试处理fail/recover模式的故障,通俗点讲就是容忍单点故障,至少需要部署3个节点;容忍2点故障,至少需要部署5个节点,机器节点越多分区容忍性就越强,顿悟了吧,嘿嘿,所以保证集群可用的前提就是有奇数个节点、奇数个数据块保持活跃可用状态,不然就无法选举出master或header。
大多数投票机制运用起来也非常灵活,当分布式系统追求强一致性时,需要等待所有的数据快及其副本全部写入成功才算完成一次写操作,即写全部(write all),可以理解一种事务保证,要么全部写入,要么一个都不写入,比如:kafka从0.11.0.0 版本开始, 当producer发送消息到多个topic partion时,就运用了这种机制,来保证消息交付的exactly-once语义,是不是很帅,而且这种情况下,从任意一个节点都能读到最新的数据,读性能最高;当分布式系统追求最终一致性时,只需等待主数据块(leader)写入成功即可,再由主数据块通过消息可达的方式同步到副本数据块。
为了能够满足不同场景下对数据可靠性和系统吞吐量的要求,最大化数据持久性和系统可用性,很多组件都提供了配置项,允许用户定义这个大多数的法定数量,下面我们就来谈谈一些常用组件的配置:
Elasticsearch
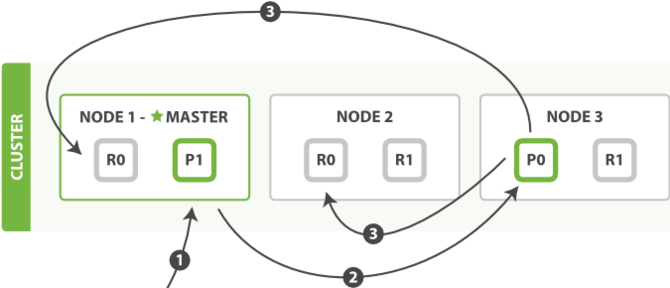
由上图可以看到,整个集群由三个运行了Elasticsearch实例的节点组成,有两个主分片,每个分片又有两个副分片,总共有6个分片拷贝,Elasticsearch内部自动将相同的分片放到了不同的节点,非常合理和理想。当我们新建一个文档时:
1、客户端向 Node 1 发送新建文档的写请求。
2、节点使用文档的 _id 确定文档属于分片 0 。请求会被转发到 Node 3,因为分片 0 的主分片目前被分配在 Node 3 上。
3、Node 3 在主分片上面执行请求。如果成功了,它将请求并行转发到 Node 1 和 Node 2 的副本分片上。一旦所有的副本分片都报告成功, Node 3 将向协调节点报告成功,协调节点向客户端报告成功。
这就是Elasticsearch处理写请求的典型步骤顺序,同时每种业务场景对数据可靠性的要求和系统性能也不一样,所以Elasticsearch提供了Consistence配置项:
1、one:主分片处于活跃可用状态就可以处理写请求。系统吞吐量最高,但数据可能会丢失,对数据可靠性要求不是很高的场景非常适合,比如实时的时序数据处理(日志)。
2、all:主分片和所有副本分片处于活跃可用状态才允许处理写请求。系统吞吐量最低,但数据不会丢失。处理关键的业务数据非常合适。
3、quorum:必须有大多数的分片拷贝处于活跃可用状态才允许处理写请求。平衡系统吞吐量和数据可靠性,一般业务系统都使用这个配置。
Kafka
当向Kafka 写数据时,producers可以通过设置ack来自定义数据可靠性的级别:
0:不等待broker返回确认消息。
1: leader保存成功返回。
-1(all): 所有备份都保存成功返回。
备注:默认情况下,为了保证分区的最大可用性,当acks=all时,只要ISR集合中的副本分区写入成功,kafka就会返回消息写入成功。如果要真正地保证写全部(write all),那么我们需要更改配置transaction.state.log.min.isr来指定topic最小的ISR集合大小,即设置ISR集合长度等于topic的分区数。
如果所有的节点都挂掉,还有Unclean leader选举机制的保证,建议大家下去阅读kafka《官方指南》设计部分,深入理解kafka是如何通过引入ISR集合来变通大多数投票机制,从而更好地保证消息交付的不同语义。
什么是集群脑裂?
对于分布式系统,自动处理故障的关键就是能够精准地知道节点的存活状态(alive)。有时候,节点不可用,不一定就是其本身挂掉了,极有可能是暂时的网络故障;在这种情况下,如果马上选举一个master节点,那么等到网络通信恢复正常的时候,岂不是同时存在两个master,这种现象被形象地称为“集群脑裂”,先留给大家下去思考吧。呵呵,明天要早起,碎觉了,大家晚安。
备注:设计一个正在高可用的分布式系统,需要考虑的故障情况往往会很复杂,大多数组件都只是处理了fail/recover模式的故障,即容忍一部分节点不可用,然后等待恢复;并不能处理拜占庭故障(Byzantine),即节点间的信任问题,也许区块链可以解决吧,大家可以下去多多研究,然后我们一起讨论,共同学习,一起进步。
写在最后
分享了这么多,请大家总结一下大多数投票机制的优点和缺点?欢迎评论区留言,哈哈,真的要睡觉了,晚安。
原文作者:无痴迷,不成功
原文链接:https://www.cnblogs.com/justmine/p/9275730.html
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





