
论文链接:https://static.aminer .cn/misc/pdf/minrror.pdf
常规的神经机器翻译(NMT)需要大量平行语料,这对于很多语种来说真是太难了。所幸的是,原始的非平行语料极易获得。但即便如此,现有基于非平行语料的方法仍旧未将非平行语料在训练和解码中发挥得淋漓尽致。
为此,本文提出一种镜像生成式机器翻译模型:MGNMT(mirror-generative NMT)。
MGNMT是一个统一的框架,该框架同时集成了source-target和target-source的翻译模型及其各自语种的语言模型。MGNMT中的翻译模型和语言模型共享隐语义空间,所以能够从非平行语料中更有效地学习两个方向上的翻译。此外,翻译模型和语言模型还能够联合协作解码,提升翻译质量。实验表明本文方法确实有效,MGNMT在各种场景和语言(包括resource rich和 low-resource语言)中始终优于现有方法。
当下神经机器翻译大行其道,但严重依赖于大量的平行语料。然而,在大多数机器翻译场景中,获取大量平行语料并非易事。此外,由于领域之间平行语料差异太大,特定领域内有限的并行语料(例如,医疗领域),NMT通常很难将其应用于其他领域。因此,当平行语料不足时,充分利用非平行双语数据(通常获取成本很低)对于获得令人满意的翻译性能就至关重要了。
当下的NMT系统在训练和解码阶段上都尚未将非平行语料发挥极致。对于训练阶段,一般是用回译法(back-translation )。回译法分别更新两个方向的机器翻译模型,这显得不够高效。给定source语种数据x和target语种数据y,回译法先利用tgt2src翻译模型将y翻译到xˆ。再用上述生成的伪翻译对(xˆ,y) 更新src2tgt翻译模型。同理可以用数据x更新反方向的翻译模型。需要注意的是,这里两个方向上的翻译模型相互独立,各自独立更新。也就是说,一方模型每次的更新都于另一方无直接益处。对此,有学者提出联合回译法和对偶学习(dual learning),在迭代训练中使二者隐含地相互受益。但是,这些方法中的翻译模型仍然各自独立。理想状态下,当两个方向的翻译模型相关,则非平行语料所带来的增益能够进一步提高。此时,一方每一步的更新都能够提升另一方的性能,反之亦然。这将更大地发挥非平行语料的效用。
对于解码,有学者提出在翻译模型x->y中直接 插入独自在target语种上训练的外部语言模型。这种引入target语种知识的方法确实能够取得更好的翻译结果,特别是对于特定领域。但是,在解码的时候直接引入独立语言模型似乎不是最好的。原因如下:
(1)采用的语言模型来自于外部,独立于翻译模型的学习。这种简单的 插入方式可能使得两个模型无法良好协作,甚至带来冲突;
(2)语言模型仅在解码中使用,而训练过程没有。这导致训练和解码不一致,可能会影响性能。
本文提出镜像生成式NMT(MGNMT)尝试解决上述问题,进而更高效地利用非平行语料。MGNMT在一个统一的框架中联合翻译模型(两个方向)和语言模型(两个语种)。受生成式NMT(GNMT)的启发,MGNMT中引入一个在x和y之间共享的隐语义变量z。本文利用对称性或者说镜像性质来分解条件联合概率p(x, y | z):
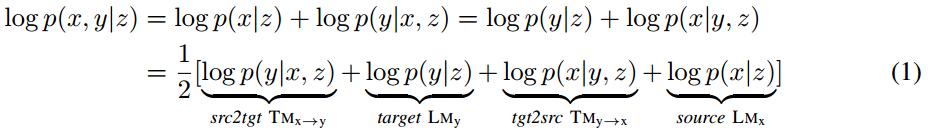
MGNMT的概率图模型如Figure 1所示:
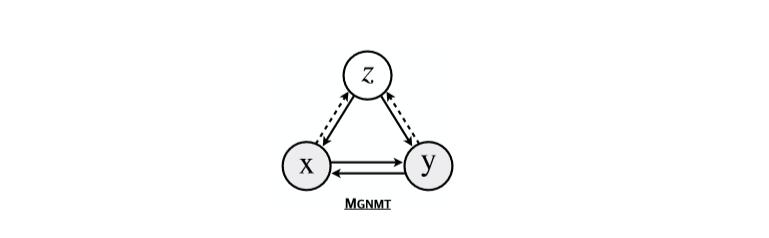
Figure 1:MGNMT的概率图模型
通过共享的隐语义变量将两个语种的双向翻译模型和语言模型分别对齐,如Figure 2所示:
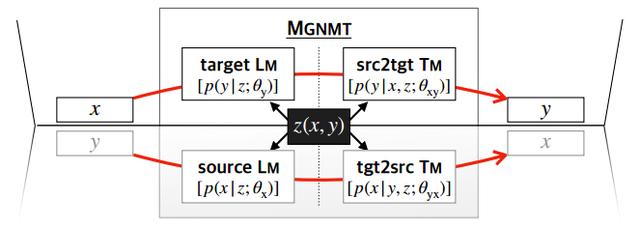
Figure 2:MGNMT的镜像性质
引入隐变量后,将各个模型关联起来,且在给定z下条件独立。如此的MGNMT有如下2个优势:
(1)训练时,由于隐变量的作用,两个方向的翻译模型不再各自独立,而是相互关联。因此一个方向上的更新直接有益于另一个方向的翻译模型。这提升了非平行语料的利用效率;
(2)解码时,MGNMT能够天然地利用其内部target端的语言模型。这个语言模型是与翻译模型联合学习的,联合语言模型和翻译模型有助于获得更好的生成结果。
实验表明MGNMT在平行语料上取得具有竞争力的结果,甚至在一些场景和语种对上(包括resource-rich语种、 resource-poor语种和跨领域翻译)优于数个健壮的基准模型。此外还发现,翻译模型和语言模型的联合学习确实能够提升MGNMT的翻译质量。本文还证明MGNMT是一种自由体系结构,可以应用于任何神经序列模型如 Transformer和RNN。
MGNMT的整体框架如Figure 3所示:
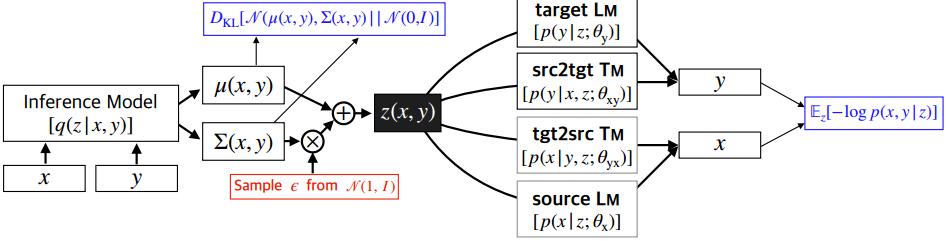
Figure 3:MGNMT的框架示意图
其中(x,y)表示source-target语言对,θ表示模型参数,D_xy $表示平行语料,D_x和D_y分别表示各自的非平行单语语料。
MGNMT对双语句对进行联合建模,具体是利用联合概率的镜像性质:

其中隐变量z(本文选用标准高斯分布)表示x和y之间的语义共享。隐变量桥接了两个方向的翻译模型和语言模型。下面分别介绍平行语料和非平行语料的训练及其解码。
给定平行语料对(x,y),使用随机梯度变分贝叶斯法(stochastic gradient variational Bayes,SGVB)得到log p(x,y)的近似最大似然估计。近似后验可以参数化为:
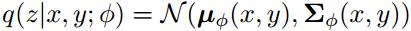
从方程(1)中可以得出联合概率对数似然的证据下界(Evidence Lower BOund,ELBO):
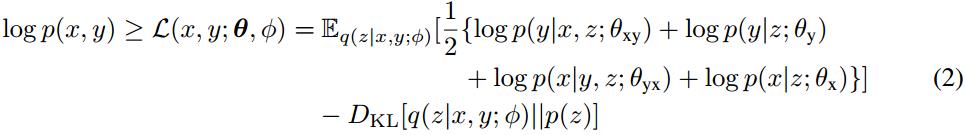
方程(2)中第一项表示句子对log似然的期望,该期望用蒙特卡洛采样获得。第二项是隐变量的近似后验和先验分布之间的KL散度。通过重新参数化的技巧,使用基于梯度的算法联合训练所有部分。
本文在MGNMT中设计一种迭代训练方法以利用非平行语料。在该训练过程中两个方向的翻译都能够受益于各自的单语种数据集,且能够相互促进。非平行语料上的训练方法如 Algorithm 1所示:

给定两个非平行句子:source语种中的句子x^s和target语种中的句子y^t。目标是使它们的边际分布似然的下界相互最大化:
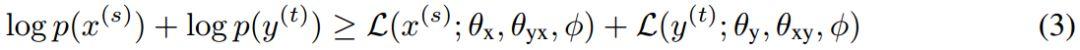
其中小于等于号右边的两项分别表示source和target的边际对数似然的下界。
以上述第二项为例。用p(x|y^t)在source语种中采样出的x作为y^t的翻译结果(即回译)。如此可以获得伪平行句子对(x, y^t)。在方程(4)中直接给出该项的表达式:
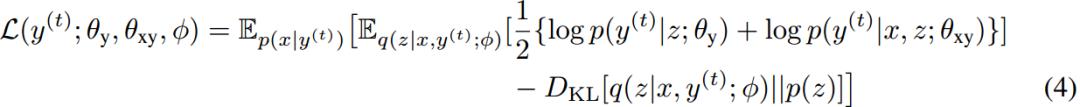
同理可以得到另一项的表达式:
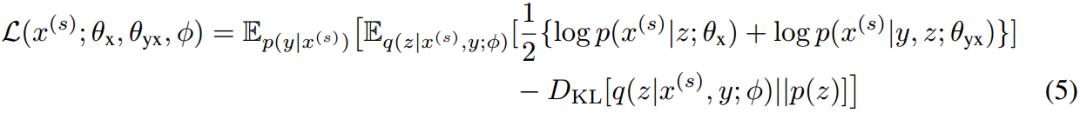
具体的证明过程,感兴趣的童鞋可以看原始论文的附录。
根据上述两个公式可以得到2个方向的伪平行语料,再将二者联合起来训练MGNMT。方程(3)可以用基于梯度的方法进行更新,计算如方程(6)所示:
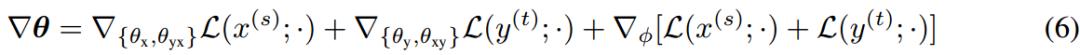
上述利用非平行语料的整个训练过程在某种程度上与联合回译相似。但是联合回译每次迭代只利用非平行语料的一个方向来更新一个方向的翻译模型。由于隐变量来自于共享近似后验q(z|x, y;Φ),所以可充当促进MGNMT中两个方向单语种性能的桥梁。
MGNMT在解码中同时对翻译模型和语言模型建模,所以在解码时能够获得更流畅更高质量的翻译结果。给定句子x(或者target句子y),通过y=argmax_{y} p(y|x)=argmax_{y} p(x, y)找到相应的翻译结果。具体的解码流程如 Algorithm 2所示:

以srg2tgt翻译模型为例。对给定的source句子x做如下操作:
(1)从标准高斯先验分布中采样一个初始化的隐变量z,然后得到一个初始翻译y~=arg max_y p(y| x, z);
(2)从后验近似分布q(z|x, y~; Φ)不断采样隐变量,用beam search重解码以最大化ELBO。从而迭代生成y~:

每个步骤的解码得分由x->y翻译模型和y的语言模型决定,这有助于翻译结果更像target语种。重建的重排得分由y->x和x的语言模型决定。重排是指翻译后对候选的重新排序。在重排中引入重建得分确实有助于翻译效果的提升。
实验数据集:WMT16 En-Ro,IWSLT16 EN-DE, WMT14 EN-DE 和 NIST EN-ZH。
• MGNMT能更充分地利用非平行语料
对所有的语言,使用的非平行语料如下Table 1所示:

Table 1:每个翻译任务数据集的统计结果
下面两个Table是模型在各个数据集上的实验结果。可以看出,MGNMT+非平行语料在所有实验上取得最好结果。
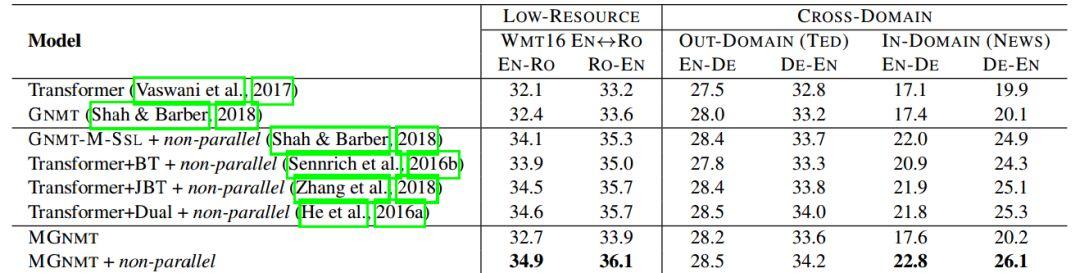
Table 2:在low-resource和跨领域翻译任务上的BLEU得分
在Table 2中值得注意的是,在跨领域数据集中使用非平行语料的MGNMT取得了最好的结果。
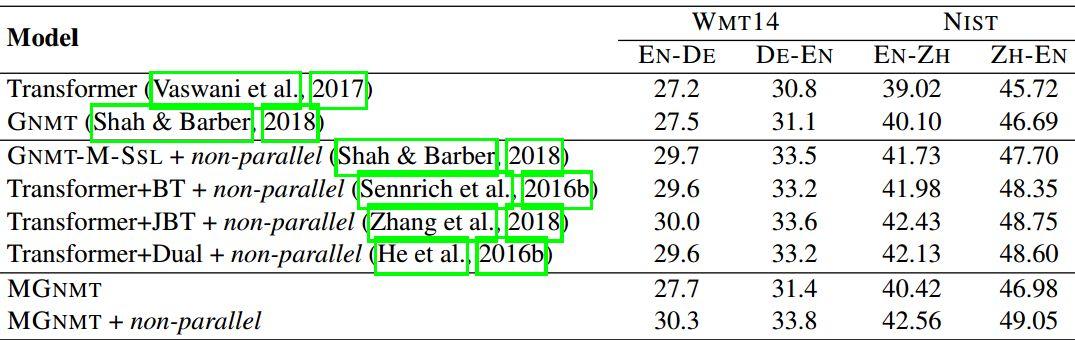
Table 3:resource-rich语种数据集上的BLEU得分
综合这两张Table,无论是low-resource还是resource-rich,MG-NMT都能取得很好的效果,尤其是加了非平行语料之后。
• MGNMT中引入语言模型性能更好
Table 4展示在解码中引入语言模型的影响。表中的LM-FUSION表示 插入一个预训练的语言模型,而不是像MG-NMT一样一起训练。可以看到,常规直接 插入LM的效果不如本文的方法。

Table 4:在解码中引入语言模型的实验结果
• 非平行语料的影响
无论是Transformer还是MGNMT,都能从更多的非平行语料中获益,但总的来看,MGNMT从中汲取的收益更大。
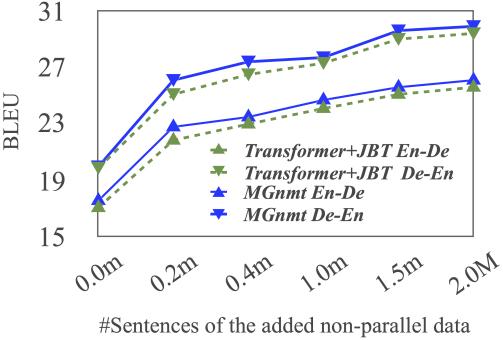
Figure 4:BLEU受非平行语料数据集规模的影响
再来看看只用单语非平行语料是否也同时有助于MGNMT两个方向上的翻译。从实验结果可以看到,只添加单语非平行语料,模型的BLEU值确实得到提升。这说明这两个方向的翻译模型的确相互促进。
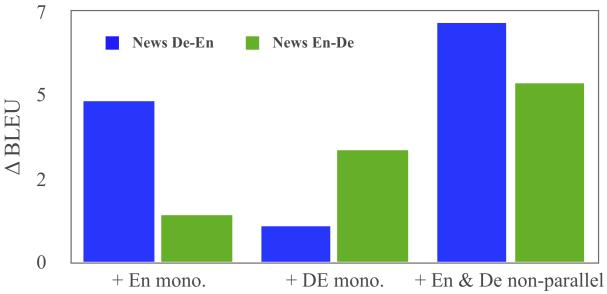
Figure 5:单语非平行语料对BLEU的影响
本文提出了一个镜像生成式的机器翻译模型MGNMT以更高效地利用非平行语料。
该模型通过一个共享双语隐语义空间对双向翻译模型和各自的语言模型进行联合学习。在MGNMT中两个翻译方向都可同时受益于非平行语料。此外,MGNMT在解码时天然利用学习到的target语言模型,这能直接提升翻译质量。实验证明本文MGNMT在各个语种翻译对中都优于其他方法。
• 未来方向
未来的研究方向,是要将MGNMT用于完全无监督机器翻译中。
AAAI 2020 论文集:
AAAI 2020 论文解读会 @ 望京(附PPT 下载)
AAAI 2020 论文解读系列:
01. [中科院自动化所] 通过识别和翻译交互打造更优的语音翻译模型
02. [中科院自动化所] 全新视角,探究「目标检测」与「实例分割」的互惠关系
03. [北理工] 新角度看双线性池化,冗余、突发性问题本质源于哪里?
04. [复旦大学] 利用场景图针对图像序列进行故事生成
05. [腾讯 AI Lab] 2100场王者荣耀,1v1胜率99.8%,腾讯绝悟 AI 技术解读
06. [复旦大学] 多任务学习,如何设计一个更好的参数共享机制?
07. [清华大学] 话到嘴边却忘了?这个模型能帮你 | 多通道反向词典模型
08. [北航等] DualVD:一种视觉对话新框架
09. [清华大学] 借助BabelNet构建多语言义原知识库
10. [微软亚研] 沟壑易填:端到端语音翻译中预训练和微调的衔接方法
11. [微软亚研] 时间可以是二维的吗?基于二维时间图的视频内容片段检测
12. [清华大学] 用于少次关系学习的神经网络雪球机制
13. [中科院自动化所] 通过解纠缠模型探测语义和语法的大脑表征机制
14. [中科院自动化所] 多模态基准指导的生成式多模态自动文摘
15. [南京大学] 利用多头注意力机制生成多样性翻译
16. [UCSB 王威廉组] 零样本学习,来扩充知识图谱(视频解读)
https://www.toutiao.com/i6779699118714389006/
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/69946223/viewspace-2672989/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



