如何利用 CNNs 建立计算机视觉模型?什么是现有的数据集?训练模型的方法有哪些?本文在尝试理解计算机视觉的最重要的概念的过程中,为现有的一些基本问题,提供了答案。
在机器学习中最热门的领域之一是计算机视觉,它具有广泛的应用前景和巨大的潜力。它的发展目的是:复制人类视觉的强大能力。但是如何通过算法来实现呢?
让我们来看看构建计算机视觉模型中,最重要的数据集以及方法。
计算机视觉算法并不神奇。 他们需要数据才能工作,并且它们只会与你输入的数据的情况一样。这些是收集正确数据的不同来源,具体还是要取决于任务:
ImageNet是最庞大且最著名的数据集之一,它是一个现成的数据集,包含1400万幅图像,使用WordNet概念手工注释。在整个数据集中,100万幅图像包含边界框注释。

带有对象属性注释的ImageNet图像。图片来源
另一个著名的例子是Microsoft COCO(Common Objects in Contex,常见物体图像识别)的 DataSet,它包含了32.8万张图片,其中包括91种对象类型,这些对象类型很容易被识别,总共有250万个标记实例。

来自COCO数据集的带注释图像的示例
虽然没有太多可用的数据集,但有几个适合不同的任务,
研究人员运用了包含超过20万名人头像的CelebFaces Attributes数据集和超过300万图像的"卧室"室内场景识别数据集(15,620幅室内场景图像);和植物图像分析数据集(来自11个不同物种的100万幅植物图像)。
照片数据集,通过这些大量的数据,不断训练模型,使其结果不断优化。
深度学习方法和技术已经深刻地改变了计算机视觉以及人工智能的其他领域,以至于在许多任务中,它的使用被认为是标准的。特别是,卷积神经网络(CNN)已经超越了使用传统计算机视觉技术的最先进的技术成果。
这四个步骤概述了使用CNN建立计算机视觉模型的一般方法:
解决对象检测挑战的方法有很多种。 在Paul Viola 和 Michael Jones 的论文《健壮实时对象检测》(Robust Real-time Object Detection)中提出了普遍的方法。
论文传送门: 「链接」
虽然该方法可以训练用来检测不同范围的对象类,但其最初的目的是面部检测。它是如此的快速和直接,并且它是在傻瓜相机中实现的算法,这也使得实时人脸检测几乎没有处理能力。
该方法的核心特性是使用一组基于Haar特性的二进制分类器进行训练的。这些特征表示边和线,在扫描图像时非常容易计算。
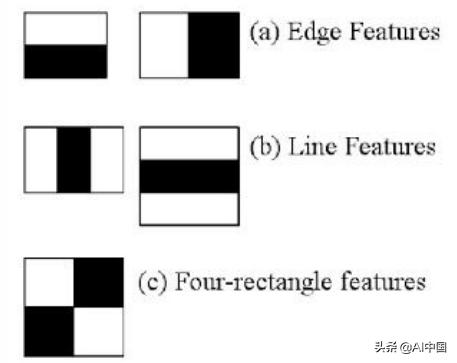
Haar features
虽然非常基本,但在特定的人脸情况下,这些特征允许捕获重要的元素,如鼻子、嘴巴或眉毛之间的距离。它是一种监督方法,需要识别对象类型的许多正例和反例。
基于CNN的方法
深度学习已经成为机器学习中一个真正的游戏规则改变者,特别是在计算机视觉领域中,基于深度学习的方法是许多常见任务的前沿。
在提出的各种实现目标检测的深度学习方法中,R-CNN(具有CNN特征的区域)特别容易理解。本文作者提出了三个阶段的过程:
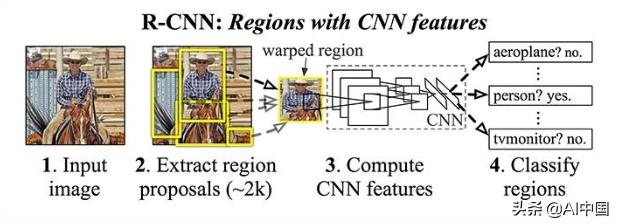
R-CNN Architecture. 图片来源
虽然R-CNN算法对于具体采用的区域建议方法是不可知的,但是在原著中选择的区域建议的方法是选择性搜索。步骤3非常重要,因为它减少了候选对象的数量,从而降低了方法的计算开销。
这里提取的特征不如前面提到的Haar特征直观。综上所述,我们使用CNN从每个区域提案中提取4096维特征向量。考虑到CNN的性质,输入必须始终具有相同的维度。这通常是CNN的弱点之一,不同的方法以不同的方式解决这个问题。对于R-CNN方法,经过训练的CNN架构需要输入227×227像素去固定区域。由于提议的区域大小与此不同,作者的方法只是扭曲图像,使其符合所需的尺寸。

与CNN所需的输入维度匹配的扭曲图像的示例
虽然取得了很好的效果,但是训练遇到了一些障碍,最终这种方法被其他人超越了。其中一些在文章中进行了深入的回顾——《深度学习的对象检测:权威指南》。
https://www.toutiao.com/a6693688027820065292/
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





