如果我们要锻炼一个人类小孩最基本的运动智力,比如抓握抬举,或者是叠被子叠衣服这样的家务活儿,几乎是不需要指导的。
很多时候只要将婴孩放置到日常生活情境中,让他与周围的环境和物体互动,大多数就能在玩耍中自动掌握判断空间、重力、协调等能力了。
与之相比,机器人就比较“娇生惯养”了。
目前绝大多数机器人,都无法自我适应和从对复杂的环境中学习通用运动能力。
这就带来了一个难题:机器人只能很“笨拙”地完成一些程序员率先编程好的动作,并且是用单一的物体来完成单一的技能,这个特定的任务和道具就是它的全世界。比如,会递杯子就不会叠被子。

这意味着,我们可能要设计成千上万种机器人,只为了应对某一个具体任务。这实在是太蠢了。
不过,要让机器学会自主感知世界,并根据环境变化做出相应的动作,那可是个大工程。
最近,伯克利大学就研究出了一种新的算法,基于视觉模型的强化学习,让全能机器人成为可能。
换句话说,原本独属于人类的“元运动智力”,也有望在机器身上打开。
当机器人具有了掌握一般性技能并将其内化成“经验”的能力,能够灵活地执行多种同类任务,不需要每次都重新学习或编程,前景显然是值得惊喜的。
那么,这么神奇的事情究竟是怎么实现的?
新算法是如何指导机器工作的?
简要来说,这种算法可以通过一个预测墨西哥,使用没有标签的感官数据集,让机器自主学习大量多样化的图像,进而在完成任务时更灵活地预测和判断。这样,它就能执行在各种不同的物体上执行很多不同任务,而不需要针对每个对象或每个任务都重新学习一次。
在伯克利大学的研究人员眼中,能够在单一模式下获得这种通用型运动能力,是智力的一个基本体现。
那么,这种方法究竟是如何指导机器人完成工作的呢?
首先,研究人员为机器人制作一个庞大且丰富多彩的数据集合,不局限于某一个物体或某一项技能;
然后,为机器人装上了能够感知图像像素(视觉)、手臂位置(自我感觉)和发送电机指令(动作)的各种传感器。
完成这些准备工作之后,就让两个机器人同时在资源库中自主收集数据和学习,并且实时进行分享。
由于两个机器人可以分享彼此的感觉和数据,这就使其掌握了预测接下来手臂移动路线的能力,从而使得动作的运动范围具备了更大的伸缩弹性,以完成操作不同类型物体的多样任务。
比如他们就让一台机器完成了移动苹果这样的刚性物体,以及折叠衣服这样的柔性物体,机器人都表现的还不错。
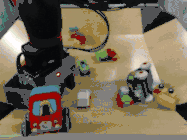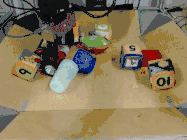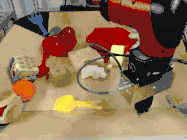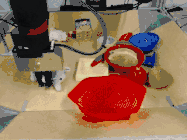

而且,即使面对以前从未见过的目标,虽然做出的预测并非和人类一样十全十美,但仍然可以有效地完成指定任务。
比如下图中,研究人员给出的任务是把苹果放在盘子里,中间是机器人做出的计划,然后是执行的情况。



这个算法模型在想法上绝对是别具一格。一直以来,基于预期结果来规划行动路线,并根据不同步骤和观察状况来实时迭代和改进计划,是人类应对复杂世界意外的独特技能。如今,机器人也有望学会这样的“高智力”游戏,在应用性上带来的改变令人真实心动了。
重建机器效率的坐标系:新模型的应用场景
现实环境是复杂多样的,提高机器人对环境的适应能力,让任务执行更加灵活,这个新算法确实给机器人应用带来了极大的想象空间。
最大的亮点在于,对机器的功能设想更符合现实情况。通用能力可以很容易地被迁移到不同的任务上,大大减少了完成特定任务所需要开发和部署的算法数量。
目前看来,新模型至少会在以下领域革新机器人的表现:
1.客服机器人。大多数客服机器人对环境不具备适应性,需要程序员将各种情况考虑在内,有的甚至直接由人工在后台进行交互操作。但有了通用模型算法之后,机器人就能够在与人类用户的交互中自主学习,学会解决一些开放型问题,变得更加自主灵活。
2.医学机械。目前,医学机器人只能作为医生双手的延伸来协助完成手术任务。要自主完成高精度手术,帮助减少医生的劳力,医学机器人必须能够感知手术部位的空间位置、处理更精细、更高复杂度的操作,新的模型显然提供了更多的可能性。

3.工业机械。工业机器人已经拥有了一定的通用性和适应性,但往往都需要跟随其工作环境变化的需求再编程,或者是更换不同的操作器来执行不同任务,都会带来一定的成本。如果新算法被真实应用起来,工业生产的成本和效率都将变得更低。
4.个性化视频生成。除了在现实世界中进行动作感知和理解预测,该算法在视频生成领域也有极大空间。比如系统可以通过大量无需标记的视频资源自主学习,根据视频中的人物进行体态识别和模仿,让AI量身定制高拟人度的视频成为可能。
掌握了通用技能的机器应用还有很多,其背后的商业前景也十分广阔,毕竟效率才是人类发明机器的初衷。
品尝果实之前,还需应对哪些挑战?
说了这么多,感觉新算法的实现并不难,应用端也有着足够的承托力。是不是很快就可以成为现实了呢?
目前来看,在“摘桃子”之前,该算法还有一些特殊的限制,可能会使其在实际应用中受阻。
一是需要的训练数据量很大。机器做出实际可执行的操作预测,完全依赖于庞大多元化数据集。
为了让机器能够根据预测先前帧的运动分布来想象和模拟接下来的像素运动,研究人员引入了59,000个机器人交互的数据集,进行大规模自监督学习。
如何在成本控制之下获取庞大优质的数据资源,恐怕会成为算法落地的头号门槛。

二是无监督学习带来的一系列问题。比如,由于训练数据完全没有标签和奖励机制,如何保证机器人能够理解并接受指定任务,再以结果导向展开行动,在现实层面有很多未知性。
伯克利的解决方案是设置一个自我监督算法,让机器保持对目标的兴趣,持续跟踪并不断重试,直至成功。但是否能够稳定输出,还需要更多的补充研究。
再比如,无监督下机器做出的预测都是人类无法用自主经验来解释的,有可能并不是最优的传输方案,还可能因为“黑箱”带来不可预知的风险。

当我们还不理解自己的“元智力”是如何运作的时候,又如何保证可以将机器的“元智力”控制的很好呢?
总而言之,这一算法虽然很令人惊喜,但也并非完美。想象很美好,实用性也不算差,但从实验室到商业场景之间,还有很长的一段路要走。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/31561483/viewspace-2285816/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



