近日,OpenAI开发了一套“OpenAI Five”算法,他们的五种神经网络算法已经可以在Dota 2游戏中进行团队协作击败业余人员队伍。
OpenAI表示,虽然今天的游戏中仍有限制,但他们的目标是在8月份的国际比赛中击败一批顶尖的专业人士,当然只限于一些有限的“英雄”角色。
然而,Dota 2是世界上最流行和最复杂的电子竞技游戏之一。

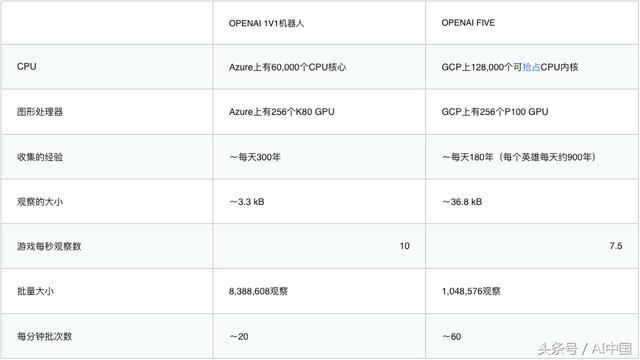
OpenAI Five每天都会玩180年的游戏,通过自我对抗来学习。 它使用在256个GPU和128,000个CPU内核上运行的扩展版Proximal策略优化进行训练 - 这是为他们去年发布的游戏更简单的单人版本而设置的更大规模版本的系统。 在游戏中,会对每个英雄使用单独的LSTM并且不使用人类数据的情况下学习到可识别的策略。
这场比赛OpenAI Five与OpenAI员工团队进行对战,由专业评论员Blitz和OpenAI Dota团队成员Christy Dennison进行了解说,不少的社区人员也相继围观。
问题
人工智能的一个里程碑是在像星际争霸或Dota这样复杂的视频游戏中超越人类的能力。相对于以前的AI里程碑,如国际象棋或围棋,复杂的视频游戏开始反映现实世界的混乱和连续性的本质。能够解决复杂视频游戏的系统具有很高的通用性,其应用程序不在游戏中。
人工智能领域的一个里程碑是在像星际争霸或Dota这样的复杂电子游戏中超越人类的能力。相对于以前的人工智能里程碑,比如国际象棋或围棋,人们可能更为关注的是解决复杂电子游戏的系统将是高度通用的,而不仅仅是在游戏领域有应用。
Dota 2是一款实时战略游戏,由两名玩家组成,每个玩家控制一个称为“英雄”的角色。玩Dota的AI必须掌握以下几点:
Dota规则也非常复杂。该游戏已经被积极开发了十多年,游戏逻辑在数十万行代码中实现。这一逻辑执行的时间是几毫秒,而对于国际象棋或围棋则只需要几纳秒。游戏每两周更新一次,不断改变环境语义。
方法
OpenAI Five的系统使用Proximal Policy Optimization的大规模版本进行学习。 OpenAI Five和早期的1v1机器人都完全依靠自我学习进行。他们从随机参数开始,不使用来自人类的数据。
强化学习的研究人员(包括我们自己)一般认为,长时间视野需要从根本上取得新的进展,如层级强化学习。结果表明,我们并没有给今天的算法足够的信用,至少是当它们以足够的规模和合理的探索方式运行时。
代理人经过训练,可以最大化未来奖励的指数衰减总和,并由称为γ的指数衰减因子加权。在最新的OpenAI Five训练中,从0.998(评估未来奖励的半衰期为46秒)到0.9997(评估未来奖励的半衰期为五分钟)退化γ。为进行比较,近端策略优化(PPO)论文中最长的平面是0.5秒的半衰期,Rainbow 论文中最长的半衰期为4.4秒,观察和进一步观察纸张的半衰期为46秒。
尽管当前版本的OpenAI Five在最后一击时表现不佳(观察我们的测试比赛,专业Dota评论员Blitz估计它大约是Dota玩家的中位数附近),但其客观的优先级匹配一个常见的专业策略。获得战略地图控制等长期回报往往需要牺牲短期回报,因为组建攻击塔需要时间。这一观察增强了OpenAI 的信念,即系统真正在长期的优化。
模型架构
每个OpenAI Five的网络都包含一个单层1024单元的LSTM,它可以查看当前的游戏状态(从Valve的Bot API中提取),并通过几个可能的动作发出对应动作。 每个动作都具有语义含义,例如延迟此动作的刻度数量,要选择的动作数量,单位周围网格中此动作的X或Y坐标等。
交互式演示OpenAI Five使用的观察空间和动作空间。 OpenAI Five将“世界”视为20,000个数字的列表,并通过发布8个列举值的列表来采取行动。 选择不同的操作和目标以了解OpenAI Five如何编码每个动作,以及它如何观察。以下图像显示的是我们看到的景象。

OpenAI Five可以对丢失的相关的状态片段做出反应。 例如,直到最近OpenAI Five的观测并没有包括弹片区域(弹丸落在敌人身上的区域),只是人类在屏幕上看到了这些区域。 然而,我们观察到OpenAI Five学习走出(虽然不能避免进入)活动的弹片区域,因为它可以看到它的“健康状况”在下降
勘探
鉴于能够处理长期视野的学习算法,我们仍然需要探索环境。即使有我们的限制,也有数百种物品,数十种建筑物、法术和单位类型,以及需要了解的大量游戏机制,其中许多产生了强大的组合。要有效地探索这个组合广阔的空间并不容易。
OpenAI Five从自我对抗开始(从随机权重开始)学习,这为探索环境提供了一个自然的课程。为了避免“战略崩溃”,代理商训练80%的游戏与自己对抗,另外20%与过去的自己对抗。在第一场比赛中,英雄们漫无目的地在地图上漫步。经过几个小时的训练后,出现了诸如农业或中期战斗等概念。几天后,他们一直采用基本的人类战略:试图从对手手中夺取赏金符文,步行到他们的一级塔去种田,并在地图上旋转英雄以获得通道优势。并且通过进一步的训练,他们就能够熟练掌握一些高级战略。
2017年3月, OpenAI 的第一个产品击败了机器人,但却对人类无能为力。为了强制在战略空间进行探索,在训练期间(并且只在训练期间),我们随机化了单位的属性(包括健康,速度,开始水平等),让它与人类对战。后来,当一名测试玩家不停击败1v1机器人时,增加了随机训练,这时候,测试玩家开始失败。(我们的机器人团队同时将相似的随机化技术应用于物理机器人,以便从仿真转移到现实世界。)
OpenAI Five使用为1v1机器人编写的随机数据。它也使用一个新的“车道分配”(lane assignment)。在每次训练比赛开始时,随机地将每个英雄“分配”给一些子集,并对其进行惩罚以避开这些车道。
可以发现,探索得到了很好的回报。奖励主要包括衡量人们如何在游戏中做出的决定:净值、杀戮、死亡、助攻、最后的命中等等。我们通过减去其他团队的平均奖励后处理每一个智能体的奖励,以防止它找到积极情况。
协调
团队合作由称为“团队精神”的超参数控制。团队精神从0到1,对OpenAI Five的每个英雄都应该关心其个人奖励功能与团队奖励功能的平均值有多重要。我们在训练中将其值从0调至1。
Rapid

系统被实施为通用RL训练系统Rapid,可应用于任何环境。我们已经使用Rapid解决了OpenAI的其他问题,包括竞争性的自我对抗。
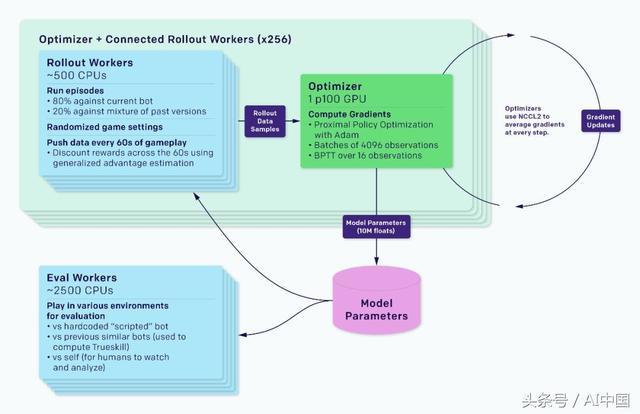
训练系统分为运行游戏副本和代理收集体验的部署工作人员,以及优化器节点,这些节点在整个GPU队列中执行同步梯度下降。部署工作人员通过Redis将他们的体验同步到优化器。每个实验还包含评估经过训练的代理商与参考代理商的工作人员,以及监控软件,如TensorBoard、Sentry和Grafana。
在同步梯度下降过程中,每个GPU计算批次部分的梯度,然后对梯度进行全局平均。我们最初使用MPI的allreduce进行平均,但现在使用NCCL2来并行GPU计算和网络数据传输。
右侧显示了不同数量的GPU同步58MB数据(OpenAI Five参数的大小)的延迟。延迟低到足以被GPU并行运行的GPU计算所掩盖。
OpenAI为Rapid实施了Kubernetes、Azure和GCP后端。
游戏
到目前为止,OpenAI Five已经在各种限制下,与球队进行了比赛:
最好的OpenAI员工团队:2.5k MMR(第46百分位)
观看OpenAI员工比赛的最佳观众玩家(包括评论第一场OpenAI员工比赛的Blitz):4-6k MMR(90-99th百分点),尽管他们从来没有作为一个团队参赛
公司员工团队:2.5-4k MMR(第46-90百分位)
业余队:4.2k MMR(第93百分位),训练为一支队伍
半职业队:5.5k MMR(第99百分位),团队训练
4月23日的OpenAI Five版本是第一个击败脚本基线的。 OpenAI Five的5月15日版本与第一队平分秋色,赢得了一场比赛并输掉了另一场。 6月6日的OpenAI Five版本决定性地赢得了所有的比赛。与第四和第五队建立了非正式的比赛,预计结果不会太好,但是OpenAI Five在前三场比赛中赢得了两场比赛。
我们观察到OpenAI Five有以下表现:
为了换取控制敌人的安全车道,反复牺牲了自己的安全车道(可怕的顶部车道;辐射的底部车道),迫使对手向更难防御的一边走近。这种策略在过去几年中出现在专业领域,现在被认为是盛行的策略。
比对手更快的完成从比赛初期到赛季中期的转场。它是这样做的:(1)建立成功的ganks(当玩家在地图上移动以埋伏敌方英雄 - 参见动画),当玩家在他们的车道中过度扩张时;(2)在对手组织起来之前,进行组队推塔。
与当前的游戏风格不同的是,在一些方面,比如给予英雄(通常不优先考虑资源)大量的早期经验和黄金支持。OpenAI Five的优先级使得它的伤害更早达到顶峰,并使它的优势更加强大,赢得团队战斗并利用错误来确保快速的胜利。

与人类的差异
OpenAI Five可以访问与人类相同的信息,可以立即看到诸如位置、健康状况和物品清单等数据,这些数据是人类必须手动检查的。我们的方法与观察状态没有本质的联系,但是仅仅从游戏中渲染像素就需要数千个gpu。
OpenAI Five的平均动作速度约为每分钟150-170个动作(理论上最大动作速度为450个,因为每隔4帧就观察一次)。尽管对于熟练的玩家来说,框架完美的时机选择是可能的,但对于OpenAI Five来说是微不足道的。OpenAI Five的平均反应时间为80ms,比人类快。
这些差异在1v1中最为重要(我们的机器人的反应时间为67ms),但由于我们看到人类从机器人身上学习并适应机器人,所以竞争环境相对公平。在去年的TI测试后的几个月里,数十名专业人士使用了我们的1v1机器人进行训练。根据Blitz的说法,1v1机器人已经改变了人们对1v1的看法(这个机器人采用了快节奏的游戏风格,现在每个人都已经适应了)。
令人惊讶的发现
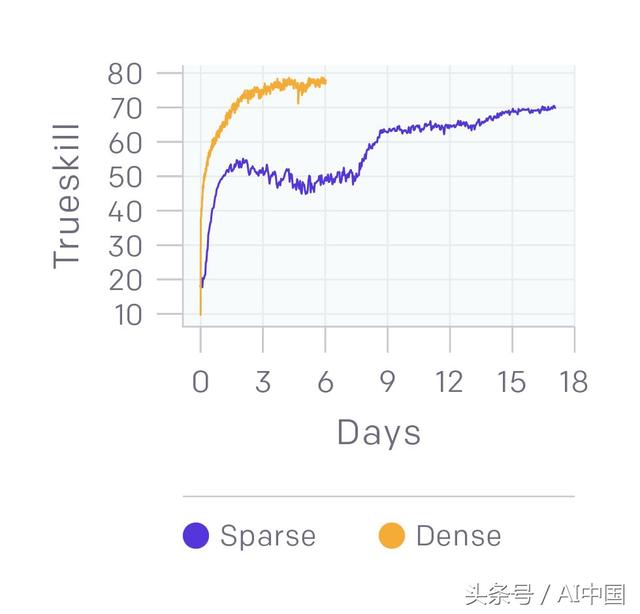
稀疏与密集的奖励学习曲线,显示密集达到同等水平的性能更快。二值奖励能带来好的表现。我们的1v1模型有一个形状的奖励,包括对最后命中目标的奖励、杀戮等等。他们做了一个实验,只奖励那些成功或失败的人,它训练了一个数量级更慢,并且在中间有一些停滞,这与我们通常看到的平滑的学习曲线形成了对比。这个实验运行在4500个核心和16k80个gpu上,训练到半专业级(70个TrueSkill),而不是最好的1v1机器人的90个TrueSkill。
可以从头学习卡兵。对于1v1,学习了使用传统RL的卡兵,并得到了一个奖励。团队的一个成员在休假时离开了2v2的模型训练,想看看还需要多久的训练才能提高性能。令他惊讶的是,这个模型已经学会了在没有任何特殊指导或奖励的情况下卡兵。
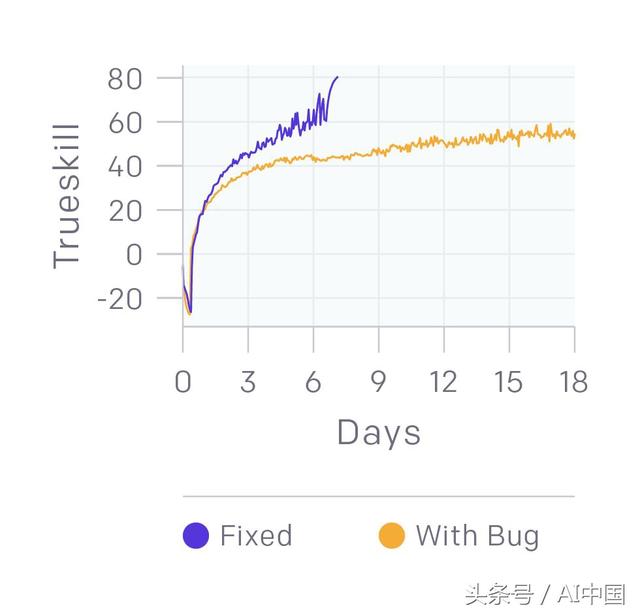
比较bug修复前后的学习曲线,显示修复bug如何提高学习速度。该图表显示了击败业余玩家的代码的训练运行情况,与此相比,只是修复了一些bug,比如在训练中偶尔发生的崩溃,或者一个bug,如果达到了25级,就会得到很大的负面奖励。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





