Node.js中日志信息的案例分析?这个问题可能是我们日常学习或工作经常见到的。希望通过这个问题能让你收获颇深。下面是小编给大家带来的参考内容,让我们一起来看看吧!
当你开始用 JavaScript 进行开发时,可能学到的第一件事就是如何用 console.log 将内容记录到控制台。如果你去搜索如何调试 JavaScript,会发现数百篇博文和 StackOverflow 文章都会简单的告诉你用 console.log。因为这是一种很常见的做法,我们甚至会在代码中使用像 no-console 这样的 linter 规则来确保不会留下意外的日志信息。但是如果我们真的想要去记录某些内容呢?
在本文中,我们将梳理各种情况下要记录的日志信息,Node.js 中 console.log 和console.error之间的区别是什么,以及如何在不发生混乱的情况下把你库中的日志记录输出到用户控制台。
console.log(`Let's go!`);
虽然你可以在浏览器和 Node.js 中使用 console.log 或 console.error,但在使用 Node.js 时要记住一件重要的事。当你在 Node.js 中将以下代码写入名为 index.js 的文件中时:
console.log('Hello there');
console.error('Bye bye');并用 node index.js 在终端中执行它,你会直接看到两者的输出:
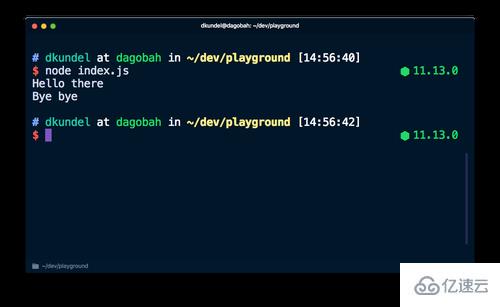
虽然它们看起来可能一样,但实际上系统对它们的处理方式是不同的。如果你查阅 Node.js 文档的
console部分,会看到 console.log 是输出到 stdout 而 console .error 用的是 stderr。
每个进程都有三个可用的默认 stream。那些是 stdin,stdout 和 stderr。 stdin 流用来在处理进程的输入。例如按下按钮或重定向输出。 stdout 流用于程序的输出。最后 stderr 用于错误消息。如果你想了解为什么会有 stderr 存在,以及应该在什么时候使用它,可以查看这篇文章。
简而言之,这允许我们在 shell 中使用重定向(>)和管道(|)来处理错误和诊断信息,它们是与程序的实际输出结果是分开的。虽然 > 允许我们将命令的输出重定向到文件中,但是 2> 允许我们将 stderr 的输出重定向到文件中。例如,下面这个命令会将 “Hello there” 传给一个名为 hello.log 的文件并把 “Bye bye” 传到一个名为 error.log 的文件中。
node index.js > hello.log 2> error.log
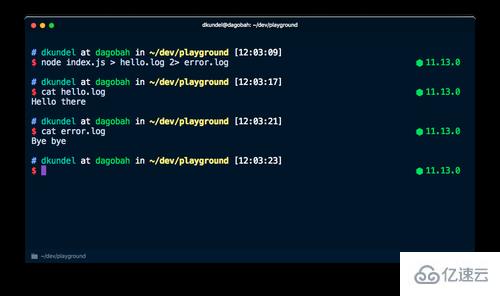
现在我们已经了解了日志记录的底层技术,接下来让我们谈谈应该在什么情况下记录日志内容。通常应该是以下情况之一:
我们将跳过前两种情况,并重点介绍基于 Node.js 的后三点。
可能你在服务器上记录日志的原因有多种。例如记录传入的请求并允许你从中提取诸如统计信息之类的内容,比如有多少用户在点击时发生了 404 错误,或者用户浏览器的 User-Agent。你也想知道在什么时候因为什么出错了。
如果你想编码尝试下面的内容,请先创建一个新的项目目录。在目录中创建一个 index.js 并运行以下命令来初始化项目并安装 express:
npm init -y npm install express
让我们设置一个带有中间件的服务器,每个请求只需用 console.log进行输出。将以下内容复制到 index.js 文件中:
const express = require('express');
const PORT = process.env.PORT || 3000;
const app = express();
app.use((req, res, next) => {
console.log('%O', req);
next();
});
app.get('/', (req, res) => {
res.send('Hello World');
});
app.listen(PORT, () => {
console.log('Server running on port %d', PORT);
});在这里用 console.log('%O', req) 来记录整个对象的信息。 console.log 在底层使用了 util.format 来支持 %O 占位符。你可以在 Node.js 文档中查阅它们的细节。
当你运行 node index.js 来启动你的服务器并导航到 http://localhost:3000 时,会发现它会打印出很多我们确实需要但不知道的信息。
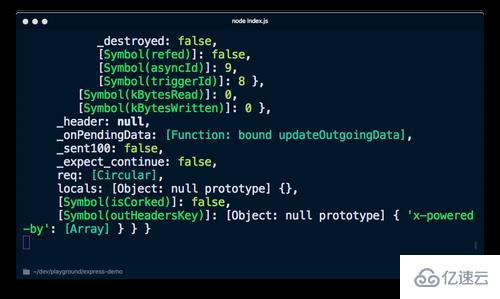
如果将其更改为 console.log('%s', req) 不打印整个对象,我们就不会获得更多信息。
![终端中输出的 "[object Object]" 信息](https://s3.amazonaws.com/com....
可以通过编写自己的日志函数只输出我们关心的东西,但是先等等,谈谈我们通常关心的东西。虽然这些信息经常成为我们关注的焦点,但实际上可能还需要其他信息:
pm2 来运行多个Node进程既然一切都会被转到 stdout 和 stderr,那么我们可能会想要不同的日志级别,还有配置和过滤日志的能力。
我们可以通过依赖 process 的各个部分并编写一堆 JavaScript 来获得所有这些,但关于 Node.js 的好消息是有 npm 这个生态系统,里面已经有了各种各样的库供我们使用。其中一些是:
pino
winston
roarr
bunyan(请注意,这个已经 2 年没有更新了)我更喜欢pino,因为它速度很快。接下来看看怎样使用 pino 来帮助我们记录日志。同时我们可以用 express-pino-logger 包来记录请求。
安装 pino 和 express-pino-logger:
npm install pino express-pino-logger
用下面的代码更新你的 index.js文件以使用 logger 和中间件:
const express = require('express');
const pino = require('pino');
const expressPino = require('express-pino-logger');
const logger = pino({ level: process.env.LOG_LEVEL || 'info' });
const expressLogger = expressPino({ logger });
const PORT = process.env.PORT || 3000;
const app = express();
app.use(expressLogger);
app.get('/', (req, res) => {
logger.debug('Calling res.send');
res.send('Hello World');
});
app.listen(PORT, () => {
logger.info('Server running on port %d', PORT);
});在这段代码中,我们创建了一个 pino 的实例 logger,并将其传给 express-pino-logger 创建一个新的 logger中间件来调用 app.use。另外,我们用 logger.info 替换了服务器启动时的 console.log,并在路由中添加了一个额外的 logger.debug 来显示不同的日志级别。
再次运行 node index.js 重新启动服务器,你会看到一个完全不同的输出,它每一行打印一个 JSON。再次导航到 http://localhost:3000 ,你会看到添加了另一行JSON。
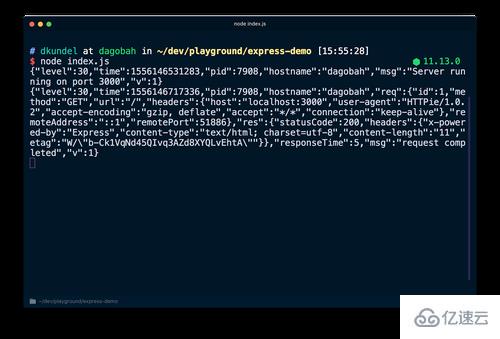
如果你检查这些 JSON,将看到它包含所有前面所提到的信息,例如时间戳等。你可能还会注意到 logger.debug 语句没有打印出来。那是因为我们必须修改默认日志级别才能看到。当我们创建 logger 实例时,将值设置为 process.env.LOG_LEVEL,这意味着我们可以通过它修改值,或接受默认的 info。通过执行 LOG_LEVEL = debug node index.js,就可以调整日志级别。
在这之前要先解决一个问题,即现在的输出不适合人类阅读。pino 遵循一种理念,为了提高性能,你应该通过管道(使用 |)将输出的任何处理移动到一个单独的进程中。这包括使其可读或将其上传到云主机。这些被称为 transports。可以通过查看 transports 文档了解为什么 pino 中的错误不会写入 stderr。
让我们用工具 pino-pretty 来查看更易阅读的日志版本。在你的终端中运行:
npm install --save-dev pino-pretty LOG_LEVEL=debug node index.js | ./node_modules/.bin/pino-pretty
现在所有的日志都被用 | 运算符输入给 pino-pretty 命令,你的输出应该会经过美化,并且还会包含一些关键信息,而且应该是彩色的。如果再次请求 http://localhost:3000 ,你还应该看到debug消息。
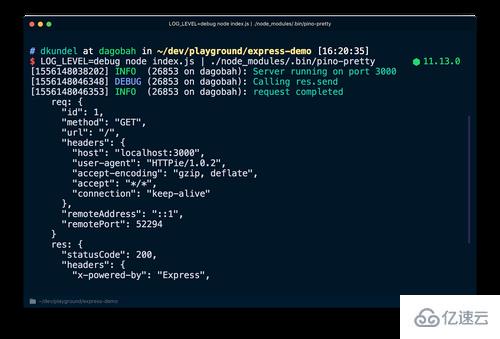
有各种各样的 transports 来美化或转换你的日志。你甚至可以用 pino-colada 显示 emoji。这些对你的本地开发很有用。在生产中运行服务器之后,你可能希望将日志传输到另一个 transports,再用 > 或者用像 tee) 这样的命令将它们写入磁盘以便稍后处理。
这个文档 中还将包含有关轮换日志文件、过滤和把日志写入不同文件等内容的信息。
现在讨论一下怎样有效地为我们的服务器程序编写日志,为什么不对我们的库使用相同的技术呢?
问题是你的库可能希望通过记录日志来进行调试,但是不应该与使用者的程序相混淆。如果需要调试某些内容,使用者应该能够启用日志。默认情况下,你的库应该是静默的,并将是否输出日志的决策权留给用户。
一个很好的例子是 express。 express 的底层有很多东西,你可能想在调试自己的程序时偷看它。如果我们查阅
express 文档,就会注意到你可以在自己的命令之前添加 DEBUG=express:*,如下所示:
DEBUG=express:* node index.js
如果你运行这个命令,将看到许多其他的输出,这些可帮助你调试程序中的问题。

如果你没有启用调试日志记录,则不会看到任何此类日志。这是通过一个称为 debug 的包来完成的。它允许我们在“命名空间”下编写日志消息,如果库的用户包含该命名空间或在 DEBUG 环境变量 中匹配了它的通配符,就会输出这些。要使用 debug 库,首先要安装它:
npm install debug
让我们通过创建一个名为 random-id.js 的新文件来模拟我们的库,并将以下代码复制到其中:
const debug = require('debug');
const log = debug('mylib:randomid');
log('Library loaded');
function getRandomId() {
log('Computing random ID');
const outcome = Math.random()
.toString(36)
.substr(2);
log('Random ID is "%s"', outcome);
return outcome;
}
module.exports = { getRandomId };这将创建一个带有命名空间 mylib:randomid 的新 debug 记录器,然后将两条消息输出到日志。让我们在前面的 index.js 中使用它:
const express = require('express');
const pino = require('pino');
const expressPino = require('express-pino-logger');
const randomId = require('./random-id');
const logger = pino({ level: process.env.LOG_LEVEL || 'info' });
const expressLogger = expressPino({ logger });
const PORT = process.env.PORT || 3000;
const app = express();
app.use(expressLogger);
app.get('/', (req, res) => {
logger.debug('Calling res.send');
const id = randomId.getRandomId();
res.send(`Hello World [${id}]`);
});
app.listen(PORT, () => {
logger.info('Server running on port %d', PORT);
});如果用 DEBUG=mylib:randomid node index.js 重新运行我们的服务器,它会打印前面“库”的调试日志。
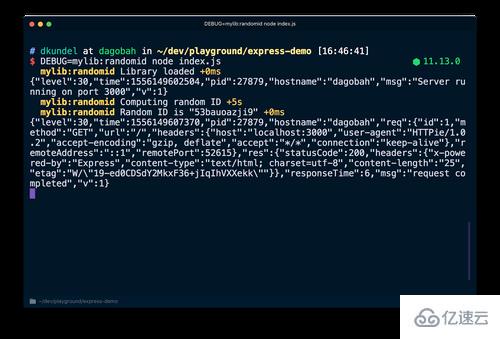
如果你的库的用户想要将这个调试信息放到他们的 pino 日志中,他们可以用 pino 团队开发的名为 pino-debug 的库来正确的格式化这些日志。
用以下命令安装库:
npm install pino-debug
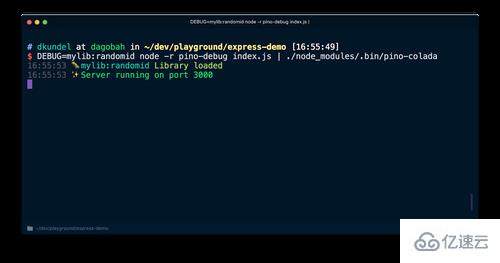
在我们第一次使用debug之前,需要初始化pino-debug。最简单的方法是在启动 javascript 脚本的命令之前使用 Node.js 的 -r 或 --require 标志来 require 模块。使用如下命令重新运行你的服务器(假设你安装了pino-colada):
DEBUG=mylib:randomid node -r pino-debug index.js | ./node_modules/.bin/pino-colada
你现在将用与程序日志相同的格式查看库的调试日志。
本文介绍的最后一个案例是针对 CLI 进行日志记录的特殊情况。我的理念是将“逻辑日志”与 CLI 的输出 “日志” 分离。对于所有的逻辑日志,你应该用像 debug 这样的库。这样你或其他人就可以重新使用该逻辑,而不受 CLI 的特定用例的约束。
当你用 Node.js 构建 CLI 时,可能希望添加一些看上去很漂亮颜色,或者用有视觉吸引力的方式格式化信息。但是,在构建 CLI 时,应该记住以下这几种情况。
一种情况是你的 CLI 可能会在持续集成(CI)系统的上下文中使用,因此你可能希望删除颜色和花哨的装饰输出。一些 CI 系统设置了一个名为 CI 的环境标志。如果你想更安全地检查自己是否在 CI 中,那就是使用像 is-ci 这样的包去支持一堆 CI 系统。
像 chalk 这样的库已经为你检测了CI 并为你删除了颜色。我们来看看它的样子。
使用 npm install chalk 安装 chalk 并创建一个名为 cli.js 的文件。将以下内容复制到其中:
const chalk = require('chalk');
console.log('%s Hi there', chalk.cyan('INFO'));Now if you would run this script using node cli.js you'll see colored output.
现在如果你用 node cli.js 运行这个脚本,将会看到彩色输出。
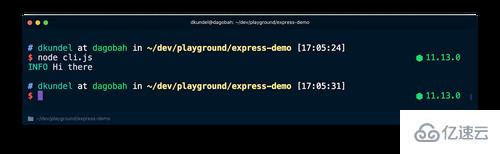
但是如果你用 CI=true node cli.js 运行它,你会看到颜色被消除了:
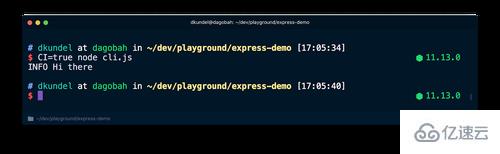
你要记住的另一个场景是 stdout 是否以终端模式运行,也就是将内容写入终端。如果是这种情况,我们可以使用 boxen 之类的东西显示所有漂亮的输出。如果不是,则可能会将输出重定向到文件或用管道传输到某处。
你可以通过检查相应流上的 isTTY 属性来检查 stdin、stdout 或 stderr 是否处于终端模式。例如:process.stdout.isTTY。 TTY 的意思是 “电传打印机(teletypewriter)”,在这种情况下专门用于终端。
根据 Node.js 进程的启动方式,这三个流每个流的值可能不同。你可以在 Node.js 文档的"process I/O" 这一部分中详细了解它。
让我们来看看 process.stdout.isTTY 的值在不同情况下是如何变化的。先更新你的 cli.js :
const chalk = require('chalk');
console.log(process.stdout.isTTY);
console.log('%s Hi there', chalk.cyan('INFO'));在终端中运行 node cli.js,你会看到输出的 true 被着色了。
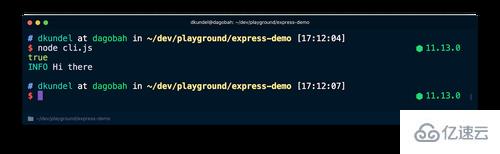
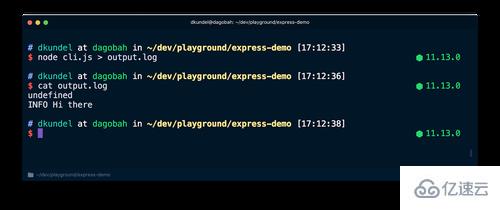
之后运行相同的内容,但是将输出重定向到一个文件,然后检查内容:
node cli.js > output.log cat output.log
你会看到这次它打印了 undefined 后面跟着一个简单的无色消息,因为 stdout 的重定向关闭了它的终端模式。因为 chalk 用了 supports-color,它们会在相应的流上检查 isTTY。
像 chalk这样的工具已经为你处理了这种行为,但是在开发 CLI 时,你应该始终了解 CLI 可能在 CI 模式下运行或重定向输出的情况。它还可以帮助你进一步获得 CLI 的体验。例如你可以在终端中以漂亮的方式排列数据,如果isTTY 是 undefined ,你可以切换到更容易解析的方式。
刚开始用 JavaScript 开发时用 console.log 记录你的第一行日志确实很快,但是当你将代码投入生产环境时,应该考虑更多关于日志记录的内容。本文纯粹是对各种方式和可用的日志记录解决方案的介绍。我建议你去看一些自己喜欢的开源项目,看看它们是怎样解决日志记录问题的,还有它们所用到的工具。

感谢各位的阅读!看完上述内容,你们对Node.js中日志信息的案例分析大概了解了吗?希望文章内容对大家有所帮助。如果想了解更多相关文章内容,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





