本篇文章给大家分享的是有关Mysql中的临时表与分区表的区别有哪些,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
临时表与内存表
内存表,指的是使用Memory引擎的表,建表语法是create table … engine=memory。这种 表的数据都保存在内存里,系统重启的时候会被清空,但是表结构还在。除了这两个特性看 上去比较“奇怪”外,从其他的特征上看,它就是一个正常的表
临时表,可以使用各种引擎类型 。如果是使用InnoDB引擎或者MyISAM引擎的临时表,写 数据的时候是写到磁盘上的。当然,临时表也可以使用Memory引擎。
临时表特性

由于临时表只能被创建它的session访问,所以在这个session结束的时候,会自动删除临时表。 也正是由于这个特性,临时表就特别适合join优化这种场景。
create temporary table temp_t like t1;
alter table temp_t add index(b);
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b);
不同session的临时表是可以重名的,如果有多个session同时执行join优化,不需要担心表名重复导致建表失败的问题。不需要担心数据删除问题。如果使用普通表,在流程执行过程中客户端发生了异常断开,或者数据库发生异常重启,还需要专门来清理中间过程中生成的数据表。而临时表由于会自动回收,所以不需要这个额外的操作。临时表的应用
分库分表系统的跨库查询
一般分库分表的场景,就是要把一个逻辑上的大表分散到不同的数据库实例上。比如。将一个大 表ht,按照字段f,拆分成1024个分表,然后分布到32个数据库实例上。
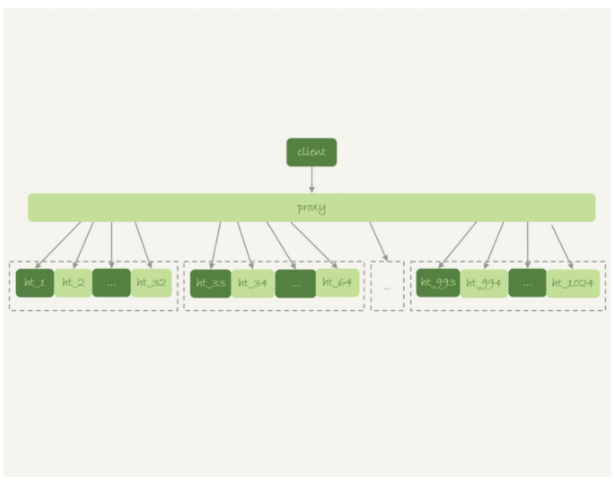
分区key的选择是以“减少跨库和跨表查询”为依据的。如果大部分的语句都会包 含f的等值条件,那么就要用f做分区键。这样,在proxy这一层解析完SQL语句以后,就能确定将这条语句路由到哪个分表做查询。 比如
select v from ht where f=N;
这时,我们就可以通过分表规则(比如,N%1024)来确认需要的数据被放在了哪个分表上。这种语句只需要访问一个分表,是分库分表方案最欢迎的语句形式了。
但是,如果这个表上还有另外一个索引k,并且查询语句是这样的:
select v from ht where k >= M order by t_modified desc limit 100;
这时候,由于查询条件里面没有用到分区字段f,只能到所有的分区中去查找满足条件的所有 行,然后统一做order by 的操作。这种情况下,有两种比较常用的思路:
在proxy层的进程代码中实现排序,对proxy端的压力比较大,尤其是很容易出现内存不够用和CPU瓶颈的问题。
把各个分库拿到的数据,汇总到一个MySQL实例的一个表中,然后在这个汇总实例上做逻辑操作。
在汇总库上创建一个临时表temp_ht,表里包含三个字段v、k、t_modifified;
在各个分库上执行
select v,k,t_modified from ht_x where k >= M order by t_modified desc limit 100;
把分库执行的结果插入到temp_ht表中;
执行
select v from temp_ht order by t_modified desc limit 100;
为什么临时表可以重名
create temporary table temp_t(id int primary key)engine=innodb;
执行这个语句的时候,MySQL要给这个InnoDB表创建一个frm文件保存表结构定义,还要有地方保存表数据。
这个frm文件放在临时文件目录下,文件名的后缀是.frm,前缀是“#sql{进程id}_{线程id}_序列 号”。你可以使用select @@tmpdir命令,来显示实例的临时文件目录。

这个进程的进程号是1234,session A的线程id是4,session B的线程id是5。所以session A和session B创建的临时表,在磁盘上的文件不会重名
MySQL维护数据表,除了物理上要有文件外,内存里面也有一套机制区别不同的表,每个表都对应一个table_def_key。 对于临时表,table_def_key在“库名+表名”基础上,又加入了“server_id+thread_id”。
也就是说,session A和sessionB创建的两个临时表t1,它们的table_def_key不同,磁盘文件名 也不同,因此可以并存。
分区表的引擎层行为
ATE TABLE `t` (
`ftime` datetime NOT NULL,
`c` int(11) DEFAULT NULL,
KEY (`ftime`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
PARTITION BY RANGE (YEAR(ftime))
Û ॔ګդᎱ
B
(PARTITION p_2017 VALUES LESS THAN (2017) ENGINE = InnoDB,
PARTITION p_2018 VALUES LESS THAN (2018) ENGINE = InnoDB,
PARTITION p_2019 VALUES LESS THAN (2019) ENGINE = InnoDB,
PARTITION p_others VALUES LESS THAN MAXVALUE ENGINE = InnoDB);
insert into t values('2017-4-1',1),('2018-4-1',1);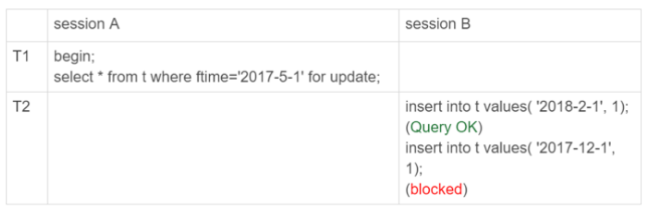
初始化表的时候,只插入了两行数据,sessionA的select语句对ftime这两个记录之间的间隙加了锁,间隙和加锁状态如图:
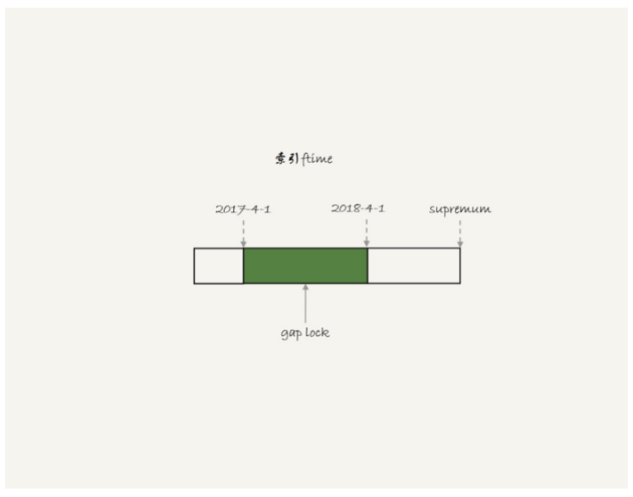
也就是说,2017-4-1和2018-4-1这两个记录之间的间隙会被锁住,那么sessionB的两条插入语句都应该进入锁等待状态。但是从效果上看,第一个insert语句是可以执行成功的,因为对于引擎来说,p2018和p2019是不同的表,2017的下一个记录不是2018-4-1而是p2018中的supremum,所以在t1时刻索引如图:
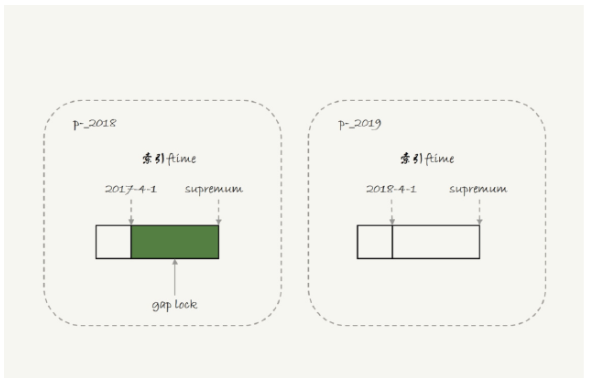
由于分区表的规则,sessionA只操作了p2018,sessionB要插入2018-2-1是可以的但要写入2017-12-1要等待sessionA的间隙锁。
对于MYISAM引擎:
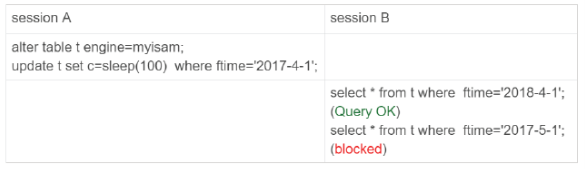
因为在sessionA中,sleep了100秒,由于myisam只支持表锁,所以这条update会锁住整个表t的读,但是结果是,B的第一条语句是可以执行的,第二条语句才进入锁等待状态。
这是myisam表锁只在引擎层实现的,sessionA加的表锁,是所在p2018上,因此只会堵住分区上执行的查询,落到其他分区的查询不受影响。这样看来,分区表还不错,为什么不用呢,我们使用分区表的一个原因就是单表过大,那么不使用分区表,就要使用手动分表的方式。
手动分表需要创建t_2017,t_2018,t_2019,也就是找到需要更新的所有分表,依次执行,这和分区表无实质的差别,两者一个由serverceng决定使用哪个分区,一个由应用层代码决定使用哪个分表,因此,从引擎层看无实际差别。其实主要区别是在server层:打开表行为。
分区策略
每当第一次访问一个分区表时,mysql需要把所有分区都访问一遍:如果分区很多,比如查过了1000个,mysql启动的时候,open_files_limit默认为1024,那么就会在访问表的时候,由于打开了所有文件,超过了上限而报错。
mysiam使用的分区策略成为通用分区策略,每次访问分区都是有server层控制。有比较严重的性能问题。
innodb引擎引入了本地分区策略,是在innodb内部自己管理打开分区的行为。
分区表的server层行为
从server层看,一个分区表就是一个表。

虽然B只操作2017分区,但是由于A持有整个表t的mdl锁,导致了B的alter语句被堵住。如果是使用普通分表,不会跟另外一个分表上的查询语句出现MDL冲突。
小结:
分区表应用场景
分区表的优势是对业务透明,相对于用户分表来说,使用分区表的业务代码更简洁,分区表可以很方便的清理历史数据。
alter table t drop partition 操作是删除分区文件,效果跟drop类似,与delete相比,优势是速度快,对系统影响小。
以上就是Mysql中的临时表与分区表的区别有哪些,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





