这篇文章将为大家详细讲解有关Hashmap的容量是2的幂次的原因,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
做为面试常考的问题之一,每次都答的模模糊糊,有必要了解一下,首先来看一下hashmap的put方法的源码
public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //将空key的Entry加入到table[0]中
int hash = hash(key.hashCode()); //计算key.hashcode()的hash值,hash函数由hashmap自己实现
int i = indexFor(hash, table.length);//获取将要存放的数组下标
/*
* for中的代码用于:当hash值相同且key相同的情况下,使用新值覆盖旧值(其实就是修改功能)
*/
for (Entry<K, V> e = table[i]; e != null; e = e.next) {//注意:for循环在第一次执行时就会先判断条件
Object k;
//hash值相同且key相同的情况下,使用新值覆盖旧值
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
//e.recordAccess(this);
return oldValue;//返回旧值
}
}
modCount++;
addEntry(hash, key, value, i);//增加一个新的Entry到table[i]
return null;//如果没有与传入的key相等的Entry,就返回null
}
/**
* "按位与"来获取数组下标
*/
static int indexFor(int h, int length) {
return h & (length - 1);
}hashmap始终将自己的桶保持在2的n次方,这是为什么?indexFor这个方法解释了这个问题
大家都知道计算机里面位运算是基本运算,位运算的效率是远远高于取余%运算的
举个例子:
2^n转换成二进制就是1+n个0,减1之后就是0+n个1,如16 -> 10000,15 -> 01111
那么根据&位运算的规则,都为1(真)时,才为1,那0≤运算后的结果≤15,假设h <= 15,那么运算后的结果就是h本身,h >15,运算后的结果就是最后四位二进制做&运算后的值,最终,就是%运算后的余数。
当容量一定是2^n时,h & (length - 1) == h % length
补充知识:HashMap容量和负载因子
HashMap底层数据结构是数组+链表,JDK1.8中还引入了红黑树,当链表长度超过8个时,会将链表转成红黑树,以提升其查找性能。那么,给出一个<key, value>节点,HashMap是如何确定这个节点应该放在具体哪个位置呢?(以JDK1.8为例)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// HashMap没有被初始化,则先进行初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 节点所在index = (n - 1) & hash,该位置没有数据,则直接将新节点放在数组的index位置上
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else { // index上已经有节点了
Node<K,V> e; K k;
// 如果新key与原来的key一样,则e指向原节点p(后面会用新value替换e所指向的value)
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果该节点是树节点,则采用树的插入算法,插入新节点
else if (p instanceof HashMap.TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { // 该节点是链表节点
for (int binCount = 0; ; ++binCount) {
// 将新节点插入到index所在链表的末端
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 链表节点超过8个,则进行链表转树处理
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 同样的,如果key已经存在的话,则不进行插入操作,而是后面进行value替换
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// e != null的情况,就是key已经存在了,这里统一进行了新值value,替换旧值e.value的操作
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
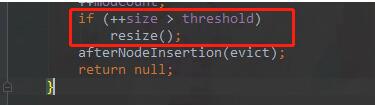
// 插入后数组size 大于阈值的话,需要进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}看源码,节点落在数组中的index = (数组长度 - 1) & key的hashcode,如果该index上没有数据,则直接插到该index上,如果节点已经有数据了,则把新节点插入该index对应的链表中(如果链表节点大于8个,会进行链表转树,之后的插入算法就变成了树的插入算法)。
每次put之后,会检测一下是否需要扩容,size超过了 总容量 * 负载因子,则会扩容。默认情况下,16 * 0.75 = 12个。
1、为什么初始容量是16
当容量为2的幂时,上述n -1 对应的二进制数全为1,这样才能保证它和key的hashcode做&运算后,能够均匀分布,这样才能减少hash碰撞的次数。至于默认值为什么是16,而不是2 、4、8,或者32、64、1024等,我想应该就是个折中处理,过小会导致放不下几个元素,就要进行扩容了,而扩容是一个很消耗性能的操作。取值过大的话,无疑会浪费更多的内存空间。因此在日常开发中,如果可以预估HashMap会存入节点的数量,则应该在初始化时,指定其容量。
2、为什么负载因子是0.75
也是一个综合考虑,如果设置过小,HashMap每put少量的数据,都要进行一次扩容,而扩容操作会消耗大量的性能。如果设置过大的话,如果设成1,容量还是16,假设现在数组上已经占用的15个,再要put数据进来,计算数组index时,发生hash碰撞的概率将达到15/16,这违背的HashMap减少hash碰撞的原则。
关于Hashmap的容量是2的幂次的原因就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



