MySQLдёӯе”ҜдёҖзҙўеј•е’Ңжҷ®йҖҡзҙўеј•е“ӘдёӘеҘҪ
д»ҠеӨ©е°ұи·ҹеӨ§е®¶иҒҠиҒҠжңүе…іMySQLдёӯе”ҜдёҖзҙўеј•е’Ңжҷ®йҖҡзҙўеј•е“ӘдёӘеҘҪпјҢеҸҜиғҪеҫҲеӨҡдәәйғҪдёҚеӨӘдәҶи§ЈпјҢдёәдәҶи®©еӨ§е®¶жӣҙеҠ дәҶи§ЈпјҢе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеёҢжңӣеӨ§е®¶ж №жҚ®иҝҷзҜҮж–Үз« еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
жғіиұЎиҝҷж ·дёҖдёӘеңәжҷҜпјҢеңЁи®ҫи®ЎдёҖеј з”ЁжҲ·иЎЁж—¶пјҢжҜҸдәәзҡ„иә«д»ҪиҜҒеҸ·жҳҜе”ҜдёҖзҡ„пјҢйңҖиҰҒжҗңзҙўгҖӮдҪҶз”ұдәҺиә«д»ҪиҜҒеҸ·еӯ—ж®өиҫғеӨ§пјҢдёҚеҘҪе°Ҷе…¶дҪңдёәдё»й”®гҖӮеңЁдёҡеҠЎд»Јз Ғе·Із»ҸдҝқиҜҒжҸ’е…Ҙиә«д»ҪиҜҒе”ҜдёҖзҡ„жғ…еҶөдёӢпјҢеҸҜд»ҘйҖүжӢ©е»әз«Ӣе”ҜдёҖзҙўеј•е’Ңжҷ®йҖҡзҙўеј•пјҢиҝҷж—¶иҜҘеҰӮдҪ•йҖүжӢ©е‘ўпјҹжҺҘдёӢжқҘпјҢе°Ҷд»ҺжҹҘиҜўе’Ңжӣҙж–°зҡ„жү§иЎҢиҝҮзЁӢиҝӣиЎҢеҲҶжһҗгҖӮ
жҹҘиҜўиҝҮзЁӢ
еҒҮи®ҫ k жҳҜиЎЁ t дёҠзҡ„зҙўеј•пјҢеңЁжҗңзҙў select id from t where k=5 ж—¶пјҢдјҡе…Ҳд»Һ k иҝҷжЈө B+ зҡ„ж ‘ж №ејҖе§ӢпјҢжҢүеұӮжҗңзҙўеҸ¶еӯҗиҠӮзӮ№пјҢжүҫеҲ° k=5 зҡ„ж•°жҚ®йЎөпјҢ然еҗҺеңЁж•°жҚ®йЎөеҶ…е®№иҝӣиЎҢдәҢеҲҶжі•е®ҡдҪҚгҖӮ
еҜ№дәҺжҷ®йҖҡзҙўеј•пјҢжүҫеҲ° k=5 зҡ„и®°еҪ•еҗҺпјҢдјҡ继з»ӯеҗ‘дёӢжҹҘжүҫдёҖдёӘпјҢзӣҙеҲ°зў°еҲ°з¬¬дёҖдёӘдёҚжҳҜ 5 зҡ„и®°еҪ•з»“жқҹгҖӮ
еҜ№дәҺе”ҜдёҖзҙўеј•пјҢз”ұдәҺеҸ–еҖје”ҜдёҖпјҢжүҫеҲ°еҗҺзӣҙжҺҘеҒңжӯўгҖӮ
з”ұдәҺ InnoDB жҳҜжҢүз…§ж•°жҚ®йЎөдёәеҚ•дҪҚпјҲж•°жҚ®йЎөй»ҳи®Ө 16 KBпјүиҝӣиЎҢиҜ»еҶҷзҡ„пјҢеңЁиҜ»еҸ–дёҖжқЎж•°жҚ®ж—¶пјҢдјҡе°Ҷж•ҙдёӘж•°жҚ®йЎөж•ҙдҪ“иҜ»еҲ°еҶ…еӯҳгҖӮ еңЁиҜ»е…ҘеҶ…еӯҳзҡ„ж•°жҚ®йЎөдёӯпјҢеҰӮжһңеҢ…еҗ« k=5 зҡ„и®°еҪ•пјҢеңЁжҹҘиҜўзҡ„жғ…еҶөдёӢпјҢе”ҜдёҖзҙўеј•жҜ”жҷ®йҖҡзҙўеј•еӨҡдәҶдёҖж¬ЎжҹҘжүҫе’ҢеҲӨж–ӯзҡ„иҝҮзЁӢпјҢеҸҜд»ҘеҝҪз•ҘгҖӮ
еҰӮжһң k=5 жҳҜеҪ“еүҚж•°жҚ®йЎөзҡ„жңҖеҗҺдёҖжқЎпјҢе°ұйңҖиҰҒеңЁиҜ»еҸ–дёӢдёҖдёӘж•°жҚ®йЎөгҖӮдҪҶиҝҷеҸ‘з”ҹзҡ„жҰӮзҺҮиҫғдҪҺпјҢд№ҹеҸҜд»ҘеҝҪз•ҘгҖӮ
жүҖд»ҘжҖ»еҫ—жқҘиҜҙпјҢжҷ®йҖҡзҙўеј•е’Ңе”ҜдёҖзҙўеј•еңЁжҹҘиҜўзҡ„иҝҮзЁӢдёӯе·®ејӮдёҚеӨ§гҖӮ
change buffer
еңЁеҲҶжһҗе”ҜдёҖзҙўеј•е’Ңжҷ®йҖҡзҙўеј•зҡ„еҪұе“ҚеүҚпјҢе…ҲжқҘи®ӨиҜҶдёҖдёӢ change buffer иҝҷдёӘз»“жһ„гҖӮ
д»Җд№ҲжҳҜ change buffer ?
еңЁжү§иЎҢжӣҙж–°ж“ҚдҪңж—¶пјҢеҰӮжһңиҰҒжӣҙж–°зҡ„ж•°жҚ®йЎөеңЁеҶ…еӯҳдёӯе°ұзӣҙжҺҘжӣҙж–°пјҢеҗҰеҲҷзҡ„иҜқпјҢеңЁдёҚеҪұе“Қж•°жҚ®дёҖиҮҙжҖ§зҡ„еүҚжҸҗдёӢпјҢInnoDB дјҡе°Ҷжӣҙж–°ж“ҚдҪңзј“еӯҳеңЁ change buffer дёӯпјҢд»ҺиҖҢзңҒеҺ»дәҶд»ҺзЈҒзӣҳиҜ»еҸ–ж•°жҚ®йЎөзҡ„иҝҮзЁӢгҖӮеңЁдёӢж¬ЎжҹҘиҜўж“ҚдҪңиҜ»еҸ–еҲ°жҒ°еҘҪйңҖиҰҒжӣҙж–°зҡ„ж•°жҚ®йЎөж—¶пјҢдјҡе°Ҷ change buffer зҡ„жӣҙж–°иҜӯеҸҘжү§иЎҢпјҢеҶҷе…Ҙж•°жҚ®йЎөгҖӮе°Ҷж“ҚдҪңеә”з”ЁеҲ°зЎ¬зӣҳзҡ„иҝҮзЁӢеҸ« merge. еҗҺеҸ°зәҝзЁӢдјҡе®ҡжңҹ merge жҲ– ж•°жҚ®еә“жӯЈеёёе…ій—ӯж—¶пјҢд№ҹдјҡиҝӣиЎҢ merge ж“ҚдҪңгҖӮ
merge зҡ„жү§иЎҢжөҒзЁӢпјҡ
- д»ҺзЈҒзӣҳиҜ»е…ҘиҖҒзүҲжң¬ж•°жҚ®йЎөгҖӮ
- д»Һ change bufferдёӯжүҫеҮәе’ҢиҜҘж•°жҚ®йЎөе…іиҒ”зҡ„и®°еҪ•пјҢдҫқж¬Ўеә”з”ЁпјҢеҫ—еҲ°ж–°зүҲж•°жҚ®йЎөгҖӮ
- еҶҷ redo logпјҢи®°еҪ•ж•°жҚ®зҡ„еҸҳжӣҙе’Ң change buffer зҡ„еҸҳжӣҙгҖӮ
change buffer е®һйҷ…дёҠжҳҜеҸҜд»ҘжҢҒд№…еҢ–еҲ°зЎ¬зӣҳдёӯзҡ„ж•°жҚ®пјҢд№ҹе°ұжҳҜиҜҙеңЁеҶ…еӯҳе’ҢзЎ¬зӣҳдёҠйғҪ change buffer зҡ„еӯҳеңЁгҖӮchange buffer д№ӢеүҚеҸ« insert bufferпјҢејҖе§ӢеҸӘеҜ№ insert buffer жңүдјҳеҢ–пјҢеҗҺжқҘеҠ дёҠдәҶеҜ№ delete е’Ң update зҡ„ж”ҜжҢҒпјҢиҝӣиҖҢж”№еҗҚеҸ« change bufferгҖӮ
еҸҜд»ҘзңӢеҲ°пјҢе…Ҳе°Ҷжӣҙж–°ж“ҚдҪңи®°еҪ•еңЁ change bufferпјҢеҮҸе°‘дәҶе°ҶзЈҒзӣҳж•°жҚ®йЎөиҜ»еҸ–еҲ°еҶ…еӯҳзҡ„иҝҮзЁӢпјҢиҜӯеҸҘзҡ„жү§иЎҢйҖҹеәҰдјҡжңүеҫҲжҳҺжҳҫзҡ„жҸҗеҚҮгҖӮеҗҢж—¶пјҢе°Ҷж•°жҚ®иҜ»е…ҘеҶ…еӯҳпјҢдјҡеҚ з”Ё buffer pool еҶ…еӯҳпјҢжүҖд»ҘеҮҸе°‘иҜ»ж“ҚдҪңпјҢиҝҳжҸҗй«ҳдәҶеҶ…еӯҳдҪҝз”ЁзҺҮгҖӮ
Buffer Pool жҳҜеҶ…еӯҳдёӯзҡ„дёҖдёӘеҢәеҹҹпјҢInnoDB еңЁи®ҝй—®иЎЁе’Ңзҙўеј•ж•°жҚ®ж—¶дјҡеңЁе…¶дёӯиҝӣиЎҢзј“еӯҳгҖӮе…Ғи®ёеңЁеҶ…еӯҳдёӯзӣҙжҺҘжӣҙж–°з»ҸеёёдҪҝз”Ёзҡ„ж•°жҚ®пјҢжқҘеҠ еҝ«еӨ„зҗҶйҖҹеәҰгҖӮеңЁдёҖдәӣдё“з”Ёзҡ„жңҚеҠЎеҷЁдёҠпјҢдјҡе°Ҷ 80% зҡ„зү©зҗҶеҶ…еӯҳеҲҶдёә buffer pool.
еҸҜд»ҘйҖҡиҝҮ innodb_change_buffer_max_size жқҘи®ҫзҪ® change buffer еҚ з”Ё buffer pool зҡ„еӨ§е°ҸгҖӮ
change buffer еә”з”ЁеңәжҷҜпјҹ
еҰӮдёҠйқўжҸҗеҲ°пјҢchange buffer йў„е…ҲдҝқеӯҳдәҶжӣҙж–°и®°еҪ•пјҢеҮҸе°‘дәҶиҜ»еҸ–ж•°жҚ®йЎөзҡ„иҝҮзЁӢпјҢд»ҺиҖҢжҸҗй«ҳжҖ§иғҪгҖӮд№ҹе°ұжҳҜиҜҙеҰӮжһң change buffer дёӯй’ҲеҜ№дёҚеҗҢзҡ„ж•°жҚ®йЎөеҰӮжһңеҢ…еҗ«зҡ„жӣҙж–°и®°еҪ•и¶ҠеӨҡпјҢе…¶е®һ收зӣҠд№ҹе°ұи¶ҠеӨ§гҖӮ
еӣ жӯӨеҜ№дәҺеҶҷеӨҡиҜ»е°‘зҡ„дёҡеҠЎпјҲжӣҙж–°е®Ңз«ӢеҚіжҹҘиҜўпјүchange buffer еҸ‘жҢҘзҡ„дҪңз”Ёд№ҹе°ұи¶ҠеӨ§гҖӮеҰӮеёёи§Ғзҡ„иҙҰеҚ•зұ»пјҢж—Ҙеҝ—зұ»зӯүзі»з»ҹгҖӮ
еҰӮжһңдёҡеҠЎжҳҜжӣҙж–°е®Ңз«ӢеҚіжҹҘиҜўпјҢиҷҪ然еҸҜд»Ҙе°Ҷжӣҙж–°и®°еҪ•ж”ҫеңЁ change buffer дёӯпјҢдҪҶз”ұдәҺд№ӢеҗҺиҰҒ马дёҠжҹҘиҜўж•°жҚ®йЎөпјҢжүҖд»Ҙдјҡз«ӢеҚіи§ҰеҸ‘ merge иҝҮзЁӢгҖӮиҝҷж ·йҡҸжңәи®ҝй—® IO 次数并дёҚдјҡеҮҸе°‘пјҢеҸҚиҖҢеўһеҠ дәҶ change buffer зҡ„з»ҙжҠӨд»Јд»·пјҢиө·еҲ°еҸҚж•ҲжһңгҖӮ
жӣҙж–°иҝҮзЁӢ
еҜ№дәҺе”ҜдёҖзҙўеј•жқҘиҜҙпјҢжүҖжңүзҡ„жӣҙж–°ж“ҚдҪңйғҪйңҖиҰҒеҲӨж–ӯжҳҜеҗҰиҝқеҸҚе”ҜдёҖжҖ§зәҰжқҹгҖӮжүҖд»Ҙеҝ…йЎ»жҠҠжүҖйңҖиҰҒзҡ„ж•°жҚ®йЎөиҜ»е…ҘеҶ…еӯҳпјҢ然еҗҺзӣҙжҺҘжӣҙж–°е°ұеҸҜд»ҘпјҢдёҚйңҖиҰҒдҪҝз”Ё change buffer. жүҖд»Ҙ change buffer еҸӘеҜ№жҷ®йҖҡзҙўеј•жңүз”ЁгҖӮ
е…·дҪ“еҲҶжһҗдёӢпјҢеҜ№дәҺдёҖеј иЎЁжҸ’е…ҘдёҖдёӘж–°и®°еҪ•пјҡ
еҰӮжһңж–°и®°еҪ•иҰҒжӣҙж–°зҡ„ж•°жҚ®йЎөеңЁеҶ…еӯҳдёӯпјҡ
еҜ№дәҺе”ҜдёҖзҙўеј•пјҢжүҫеҲ°еҗҲйҖӮзҡ„дҪҚзҪ®пјҢеҲӨж–ӯжңүжІЎжңүеҶІзӘҒпјҢжҸ’е…ҘеҖјпјҢиҜӯеҸҘз»“жқҹгҖӮ
еҜ№дәҺжҷ®йҖҡзҙўеј•пјҡжүҫеҲ°дҪҚзҪ®пјҢжҸ’е…ҘеҖјпјҢиҜӯеҸҘз»“жқҹгҖӮ
жүҖд»Ҙж•°жҚ®йЎөеңЁеҶ…еӯҳж—¶пјҢе”ҜдёҖе’Ңжҷ®йҖҡзҙўеј•е°ұе·®дёҖдёӘеҲӨж–ӯзҡ„иҝҮзЁӢгҖӮеҸҜд»ҘеҝҪз•ҘгҖӮ
еҰӮжһңж–°и®°еҪ•иҰҒжӣҙж–°зҡ„ж•°жҚ®йЎөдёҚеңЁеҶ…еӯҳдёӯпјҡ
еҜ№дәҺе”ҜдёҖзҙўеј•пјҢе°Ҷж•°жҚ®йЎөиҜ»е…ҘеҶ…еӯҳпјҢеҲӨж–ӯеҶІзӘҒпјҢжҸ’е…ҘпјҢиҜӯеҸҘз»“жқҹгҖӮ
еҜ№дәҺжҷ®йҖҡзҙўеј•пјҢе°ҶиҜӯеҸҘи®°еҪ•еңЁ change buffer дёӯпјҢиҜӯеҸҘз»“жқҹгҖӮ
з”ұдәҺд»ҺзЈҒзӣҳеҲ°еҶ…еӯҳж¶үеҸҠйҡҸжңә IO и®ҝй—®пјҢжҳҜж•°жҚ®еә“жҲҗжң¬жңҖй«ҳзҡ„ж“ҚдҪңд№ӢдёҖгҖӮжҷ®йҖҡзҙўеј•жҜ”е”ҜдёҖзҙўеј•еҮҸе°‘зҡ„иҜ»е…Ҙж“ҚдҪңпјҢеҸҜд»ҘжңүеҫҲеҘҪзҡ„жҖ§иғҪжҸҗеҚҮгҖӮ
е”ҜдёҖжҲ–жҷ®йҖҡзҙўеј•зҡ„йҖүжӢ©
йҖҡиҝҮеңЁжҹҘиҜўе’Ңжӣҙж–°ж–№йқўпјҢдёӨиҖ…зҡ„жҜ”иҫғгҖӮжҲ‘们зҹҘйҒ“пјҢеңЁжҹҘиҜўиҝҮзЁӢдёӯпјҢйҷӨдәҶжһҒзү№ж®Ҡжғ…еҶөпјҢе…¶е®һдёӨиҖ…зҡ„е·®ејӮ并дёҚеӨ§гҖӮ
дё»иҰҒзҡ„е·®ејӮжҳҜеңЁжӣҙж–°иҝҮзЁӢдёӯпјҢиҰҒжӣҙж–°зҡ„ж•°жҚ®йЎө并дёҚеңЁеҶ…е®№дёӯзҡ„жғ…еҶөгҖӮиҝҷж—¶е”ҜдёҖзҙўеј•пјҢз”ұдәҺйңҖиҰҒе”ҜдёҖжҖ§жЈҖжҹҘпјҢдёҚиғҪеҲ©з”Ё change buffer. еӨҡдәҶд»ҺзЈҒзӣҳеҲ°еҶ…е®№иҜ»еҸ–ж•°жҚ®зҡ„иҝҮзЁӢпјҢе…¶дёӯж¶үеҸҠйҡҸжңә IO зҡ„и®ҝй—®пјҢзӣёеҜ№жқҘиҜҙж•ҲзҺҮе°ұдҪҺдәҶгҖӮ
жүҖд»ҘеҰӮжһңдёҡеҠЎйңҖиҰҒжӣҙж–°дёҚй”ҷзҡ„жҖ§иғҪпјҢиҝҷж—¶еҸҜд»ҘйҖүз”Ёжҷ®йҖҡзҙўеј•гҖӮеҪ“然дёҖеҲҮйғҪжҳҜе»әз«ӢеңЁиғҪдҝқиҜҒж•°жҚ®еҮҶзЎ®жҖ§зҡ„еүҚжҸҗдёӢгҖӮ
еҪ“еҰӮжһңжӣҙж–°еҗҺжқҘзҙ§жҺҘзқҖжҹҘиҜўж“ҚдҪңпјҢеҸҜд»ҘиҖғиҷ‘е…іжҺү change buffer. е…¶д»–зҡ„жғ…еҶөпјҢchange buffer йғҪиғҪжңүеҫҲеҘҪзҡ„жҸҗеҚҮгҖӮ
зү№еҲ«й’ҲеҜ№жңәжў°зЎ¬зӣҳпјҢchange buffer ж•ҲжһңеҫҲжҳҫи‘—гҖӮ
redo log е’Ң change buffer зҡ„жҜ”иҫғ
InnoDB дёӯ redo log зҡ„еҮәзҺ°дҪҝе…¶е…·жңүдәҶ crash-safe зҡ„иғҪеҠӣпјҢеҗҢж—¶иҝҳжҸҗй«ҳдәҶж•ҲзҺҮпјҢйҖҡиҝҮ WAL е…ҲеҶҷж—Ҙеҝ—пјҢеҶҚеҶҷзЈҒзӣҳгҖӮ
иҖҢ change buffer жҳҜиҠӮзңҒдәҶд»ҺзЈҒзӣҳиҜ»е…Ҙж•°жҚ®йЎөеҲ°еҶ…еӯҳзҡ„йҡҸжңәIOиҝҮзЁӢгҖӮ
дёӢйқўйҖҡиҝҮдёҖжқЎжҸ’е…ҘиҜӯеҸҘжқҘеҲҶжһҗдёӢдёӨиҖ…й—ҙзҡ„е…ізі»пјҡ
mysql> insert into t(id,k) values(id1,k1),(id2,k2);
еҒҮи®ҫ k дёәжҷ®йҖҡзҙўеј•пјҢk1 жүҖжҸ’е…Ҙзҡ„ж•°жҚ®йЎөеңЁеҶ…еӯҳдёӯпјҢ k2 дёҚеңЁгҖӮ
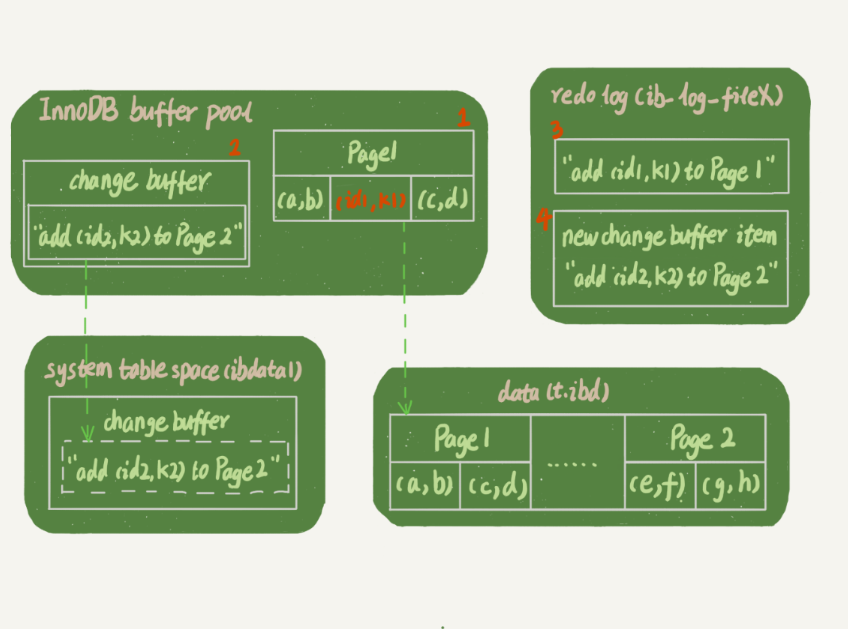
жү§иЎҢжҸ’е…Ҙж“ҚдҪңж—¶пјҢдё»иҰҒж¶үеҸҠдәҶеӣҫдёӯиҝҷеӣӣйғЁеҲҶзҡ„еҶ…е®№пјҡ
InnoDB buffer poolпјҡеҶ…еӯҳеҢәеҹҹ
redo logпјҡж—Ҙеҝ—
system table space(ibdata1):зі»з»ҹиЎЁз©әй—ҙ
data(t.idb): ж•°жҚ®иЎЁз©әй—ҙ
innodb_file_per_table ејҖеҗҜж—¶пјҢиЎЁиў«еҲӣе»әеңЁзӢ¬з«Ӣзҡ„иЎЁз©әй—ҙдёӢпјҢеҗҰеҲҷзҡ„иҜқиў«еҲӣе»әеңЁзі»з»ҹзҡ„иЎЁз©әй—ҙдёӢгҖӮ
жү§иЎҢиҝҮзЁӢеҰӮдёӢпјҡ
- k1 жүҖеңЁзҡ„ page1 еңЁеҶ…еӯҳдёӯпјҢзӣҙжҺҘжӣҙж–°еҶ…еӯҳ
- k2 жүҖеңЁзҡ„ page2 дёҚеңЁеҶ…еӯҳдёӯпјҢи®°еҪ•еңЁ change buffer.
- е°Ҷ k1 е’Ң k2 зҡ„ж“ҚдҪңи®°еҪ•еңЁ redo log.
- жҸҗдәӨдәӢеҠЎгҖӮ
еҸҜд»ҘзңӢеҲ°иҝҷжқЎжӣҙж–°иҜӯеҸҘ(еҢ…жӢ¬жҸ’е…ҘпјҢеҲ йҷӨпјҢжӣҙж–°ж“ҚдҪң)жү§иЎҢжҲҗжң¬еҫҲдҪҺпјҢдёӨж¬ЎеҶҷе…ҘеҶ…еӯҳпјҢ1ж¬ЎйЎәеәҸеҶҷе…ҘзЈҒзӣҳгҖӮиҷҡзәҝзҡ„ж“ҚдҪңпјҢжҳҜеҗҺеҸ°ж“ҚдҪңпјҢдёҚеҪұе“Қе“Қеә”ж—¶й—ҙгҖӮ
еҶҚжқҘзңӢдёҖжқЎжҹҘиҜўиҜӯеҸҘпјҡ
select * from t where k in (k1, k2)
еҒҮи®ҫиҜ»иҜӯеҸҘеҸ‘з”ҹеңЁжӣҙж–°иҜӯеҸҘдёҚд№…пјҢеҶ…еӯҳж•°жҚ®иҝҳеңЁпјҢжӯӨж—¶иҜ»ж“ҚдҪңе°ұе’Ңзі»з»ҹиЎЁз©әй—ҙе’Ң redo log ж— е…ігҖӮ
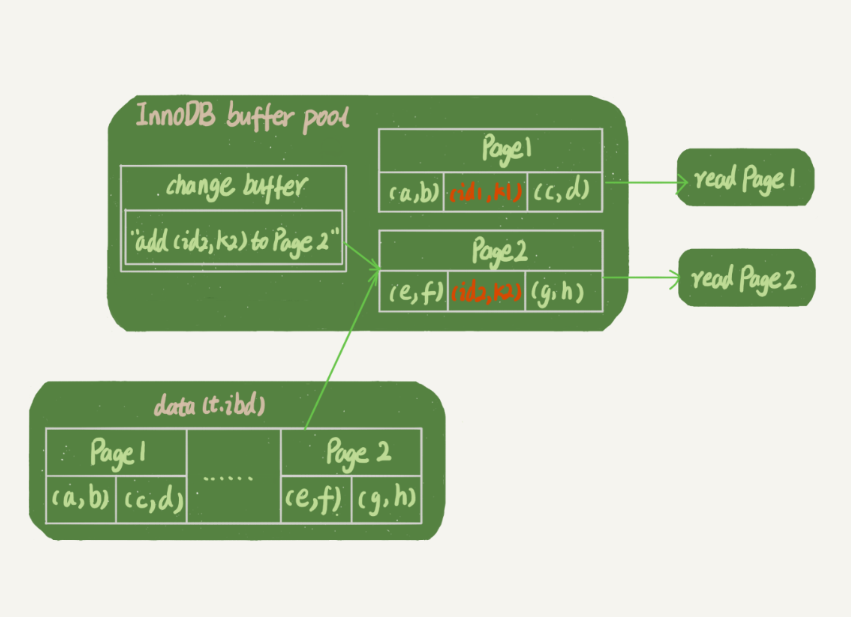
жү§иЎҢиҝҮзЁӢпјҡ
- иҜ»еҸ– k1 жүҖеңЁзҡ„ page1пјҢеңЁеҶ…еӯҳдёӯпјҢзӣҙжҺҘиҝ”еӣһгҖӮжіЁж„ҸпјҢ并没жңүиҜ»зЈҒзӣҳдёҠзҡ„ж•°жҚ®пјҢиҖҢдё”зЈҒзӣҳдёҠзҡ„ж•°жҚ®иҝҳжңүеҸҜиғҪжҳҜд№ӢеүҚзҡ„зүҲжң¬зҡ„гҖӮ
- иҜ»еҸ– k2 жүҖеңЁзҡ„ page2пјҢиҝҷж—¶йңҖиҰҒе°Ҷ page2 д»ҺзЈҒзӣҳеҠ иҪҪеҲ°еҶ…еӯҳпјҢ并еә”з”Ё change buffer зҡ„еҶ…е®№пјҢ然еҗҺиҝ”еӣһжӯЈзЎ®зҡ„з»“жһңгҖӮд»ҺиҝҷйҮҢд№ҹиғҪзңӢеҮәпјҢchange buffer дёҚйҖӮз”ЁдәҺжӣҙж–°е®Ңз«Ӣ马еҺ»иҜ»зҡ„жғ…еҶөгҖӮ
жҖ»з»“дёӢ redo log е’Ң change buffer зҡ„е…ізі»пјҡ
еӯҳеӮЁдҪҚзҪ®пјҡchange buffer д№ҹдјҡжҢҒд№…еҢ–еңЁзЎ¬зӣҳйҮҢпјҢдҪҶдҝқеӯҳеңЁзі»з»ҹиЎЁз©әй—ҙ ibdata1 йҮҢгҖӮиҖҢ redo log жҳҜеҚ•зӢ¬зҡ„ж–Ү件гҖӮ
и®°еҪ•еҶ…е®№пјҡchange buffer и®°еҪ•зҡ„жҳҜжӣҙж–°ж“ҚдҪңзҡ„еҶ…е®№пјҢиҖҢ redo log и®°еҪ•зҡ„жҳҜжҷ®йҖҡж•°жҚ®йЎөзҡ„дҝ®ж”№е’Ң change buffer зҡ„ж”№еҠЁгҖӮ
еҗҢжӯҘзЈҒзӣҳиҝҮзЁӢпјҡеҗҢжӯҘеҶ…еӯҳдёӯж•°жҚ®йЎөзҡ„дҝ®ж”№ж—¶йҖҡиҝҮ merge ж“ҚдҪңиҝӣиЎҢзҡ„пјҢиҖҢдёҚжҳҜж №жҚ® redo log.
д»Һжӣҙж–°зҡ„иҝҮзЁӢжқҘзңӢ: redo log е°ҶйҡҸжңәеҶҷзЈҒзӣҳзҡ„ IO иҪ¬жҚўжҲҗдәҶйЎәеәҸеҶҷпјҢиҖҢ change buffer еҲҷжҳҜиҠӮзңҒдәҶйҡҸжңәиҜ»зЈҒзӣҳзҡ„ IO ж¶ҲиҖ—гҖӮ
еҰӮжһңжңҚеҠЎеҷЁејӮеёёжҺүз”өпјҢдјҡдёҚдјҡеҜјиҮҙ change buffer дёўеӨұпјҹ
并дёҚдјҡпјҢеӣ дёә change buffer дёӯзҡ„ж•°жҚ®е·Із»Ҹиў«и®°еҪ•еҲ° redo log дёӯпјҢжүҖд»ҘдёҚдјҡдёўеӨұгҖӮ
з”ұдәҺ change buffer дёҖйғЁеҲҶж•°жҚ®еңЁзЈҒзӣҳпјҢдёҖйғЁеҲҶеңЁеҶ…еӯҳгҖӮеҜ№дәҺеңЁзЈҒзӣҳзҡ„ж•°жҚ®е·Із»Ҹ merge жүҖд»ҘдёҚдјҡдёўеӨұгҖӮ
еҜ№дәҺеңЁеҶ…еӯҳдёӯзҡ„ж•°жҚ®пјҡ
- еҰӮжһң change buffer еҶҷе…ҘпјҢдҪҶ redo log жңӘжҸҗдәӨпјҢbinlog жңӘжҸҗдәӨпјҢдәӢеҠЎдјҡеӣһж»ҡпјҢиҝҷйғЁеҲҶж•°жҚ®дёҚеӯҳеңЁгҖӮ
- еҰӮжһң change buffer еҶҷе…ҘпјҢredo log еҶҷе…ҘпјҢbinlog еҶҷе…ҘпјҢ并已жҸҗдәӨпјҢдёҚдјҡдёўеӨұгҖӮд»Һ redo log зӣҙжҺҘжҒўеӨҚгҖӮ
- еҰӮжһң change buffer еҶҷе…ҘпјҢredo log еҶҷе…ҘдҪҶжңӘ commitпјҢbinlog еҶҷе…ҘпјҢд»Һ binlog жҒўеӨҚ redo log еҶҚжҒўеӨҚ change buffer.
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们еҜ№MySQLдёӯе”ҜдёҖзҙўеј•е’Ңжҷ®йҖҡзҙўеј•е“ӘдёӘеҘҪжңүиҝӣдёҖжӯҘзҡ„дәҶи§Јеҗ—пјҹеҰӮжһңиҝҳжғідәҶи§ЈжӣҙеӨҡзҹҘиҜҶжҲ–иҖ…зӣёе…іеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеӨ§е®¶зҡ„ж”ҜжҢҒгҖӮ





